hive是什么:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能(HQL)
hive有什么用
1.通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
2.可以用来进行数据提取转化加载(ETL)
3.可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制
4.允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
5.HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户
适用场景
1.Hive 并不能够在大规模数据集上实现低延迟快速的查询
2.Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(不包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)
1.首先需要搭建hadoop环境:hadoop集群的搭建
2.mysql数据库的安装:CentOS安装mysql源码包
3.创建Hive数据库
4.上传hive安装包到/sur/local/src中,并且解压缩
cd /usr/local/src
tar -zxvf apache-hive-2.0.1.0-bin.tar.gz
5.解压缩完成后,复制到上级目录
mv apache-hive-2.0.1.0-bin. ../
6.配置hive-site.xml
cd /usr/local/apache-hive-2.1.0-bin/conf
vim hive-site.xml
内容如下:


<?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.local</name> <value>true</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://guoyansi128:3306/hive?characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>gys</value> </property> </configuration>
7.查看文件,是否有hive-site.xml

8.复制java connector到依赖库
下载mysql-connector-java-5.1.12.tar.gz,并且上传至/usr/local/src并且解压缩
tar -zxvf mysql-connector-java-tar.gz
复制其中的mysql-connector-java-5.1.12-bin.jar到/usr/local/apache-hive-2.0.1.0-bin/lib
cp mysql-connector-java-5.1.12-bin.jar /usr/local/apache-hive-2.0.1.0-bin/lib
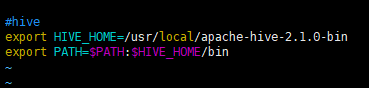
9.修改 .bash_profile文件
vim /root/.bash_profile
在末尾添加
#hive
export HIVE_HOME=/usr/local/apache-hive-2.1.0-bin
export PATH=$PATH:$HIVE_HOME/bin
10.查看 mysql是否启动
service mysqld status //查看状态
service mysqld start //启动
service mysqld stop //停止
11.元数据库初始化
schematool -dbType mysql -initSchema
12.启动Hive
cd /usr/local/apache-hive-2.1.0-bin/bin
./hive
13.启动成功后会出现 hive> 表示环境安装成功

Hive的基本应用(Hive shell模式,命令行模式)
上面13是进入了Hive shell模式
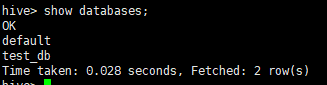
Hive shell模式(前面有hive>)查看数据库:
show databases;
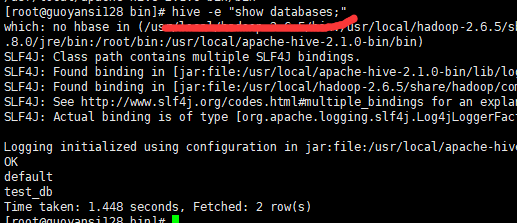
命令行模式查看databases;
hive -e "show databases;"