这几天参加了很多公司的笔试,碰到了一些很有意思的题目,下面是我解决问题的算法,分享给大家,绝对是自己原创!
如果大家要转载,请注明出处,附加原文地址链接,否则将追究其法律责任。请尊重作者的劳动成果!
问题描述:输入n个字符串,每个字符串只出现A-J之间的字符,可以出现重复的字符,要求将A-J对应的字符编码为0-9的数字,给出编码方案,使得所有编码后的字符串加起来和最大。
例如:输入两个字符串“ABC”和“BCA”,将B编码为9,A编码为8,C编码为7,D编码为6,E编码为5,F编码为4,G编码为3,H编码为2,I编码为1,J编码为0。
则两个字符串对应的数值分别为:897和978,使得和最大为1875.
分析:第一次看到这道题,首先想到的是搜索的方法,然后贪心地去处理,这种方法确实可以实现,但是时间复杂度太高了,呈指数级增长,经过考虑后,想出了一个新的办法,可以降低时间复杂度。
先说下整体的思路,再编写实际的代码,可以结合代码看,代码写法比较通用,读者可以很容易的转换为其他语言。
1. 先求出所有的字符串中最长的长度,假设为maxLength,然后在长度不够最长长度的字符串前面补上A-J之外的任意字符(代码中我补的是‘@’),使得所有的字符串长度都相等,等于最长的长度。
2.然后开辟一个10*maxLength的二维数组,并全部初始化为0,行代表的是每个字符,列代表的是每个位置,然后依次扫描每个字符串的每一位,统计出各个字符出现的频率。如下图所示,
其中最上面一行代表的是权值,最左边的一列代表的是每个字符。格子里的数字表示每个字符在每一位出现的频率,为了简单起见,空代表0.
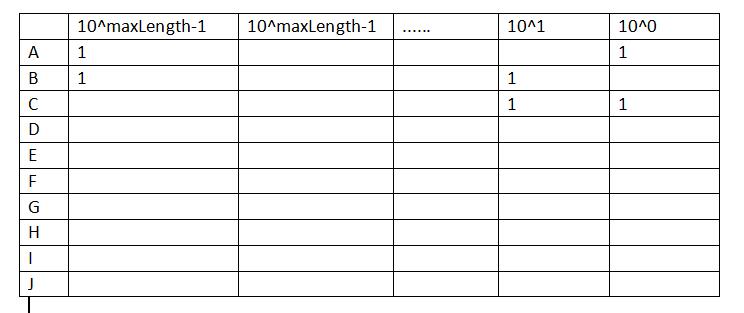
3. 统计完之后,把每个字符对应的位置的频率乘以对应的权值,计算出每个字符的基数和。存到另外一个数组b[]中,
4.然后将b[]进行排序,把最大的元素对应的字符编码为9,第二大的元素对应的字符编码为8,依次类推,对于没有出现过的字符可以任意编码,编码完成。
5. 把对应的元素乘以编码后的数字,再把所有的结果进行累加,即可得出最大的和。
具体的Java代码如下:
1 import java.util.*; 2 public class Main { 3 public static void main(String[] args) { 4 // TODO 自动生成的方法存根 5 Scanner scan=new Scanner(System.in); 6 int n=Integer.parseInt(scan.nextLine()); //读入n 7 String str[]=new String[n]; 8 int maxLength=0; 9 for(int i=0;i<n;i++) //读入每个字符串,并统计出最长的字符串的长度 10 { 11 str[i]=scan.nextLine(); 12 if(str[i].length()>maxLength)maxLength=str[i].length(); 13 } 14 int a[][]=new int[10][maxLength]; //开出一个10*最大长度的二维数组 15 for(int i=0;i<n;i++) 16 { 17 if(str[i].length()<maxLength) 18 { int length=str[i].length(); 19 for(int j=0;j<maxLength-length;j++) //把长度不够最大长度的字符串的前面补上无关的任意字符,这里我补的是@字符 20 str[i]="@"+str[i]; 21 } 22 for(int j=0;j<maxLength;j++) //统计每个字符串每个位上出现字符的频率,放到频率数组a[][]中 23 if(str[i].charAt(j)!='@') //如果是我之前补得无关字符,则忽略 24 a[str[i].charAt(j)-'A'][j]++; 25 } 26 int b[]=new int[10]; //开辟一个用来存储每个字符的单位和 27 char ch[]={'A','B','C','D','E','F','G','H','I','J'}; //用来和b[]绑定,用来记忆每个字符的位置,因为后面要对b[]排序 28 for(int i=0;i<=9;i++) //统计出每个字符出现的基数综合 29 for(int j=0;j<maxLength;j++) 30 b[i]=b[i]*10+a[i][j]; 31 32 33 for(int i=0;i<9;i++) //把每个字符的基数值总和进行排序 34 for(int j=i+1;j<10;j++) 35 if(b[i]>b[j]){ 36 int t=b[i]; 37 b[i]=b[j]; 38 b[j]=t; 39 char c=ch[i]; 40 ch[i]=ch[j]; 41 ch[j]=c; 42 } 43 44 int sum=0; //用来计算最终的总和 45 for(int i=0;i<=9;i++) 46 { 47 System.out.print(i+"对应"+ch[i]+", "); //输出每个数字对应的字符 48 sum=sum+b[i]*i; 49 } 50 System.out.println(); 51 System.out.println("总和为:"+sum); 52 } 53 54 }
输出结果为:
2
ABC
BCA
0对应D, 1对应E, 2对应F, 3对应G, 4对应H, 5对应I, 6对应J, 7对应C, 8对应A, 9对应B,
总和为:1875