Mysql性能优化
一、概述
当我们想查看Mysql的状况的话,通过linux系统,我们可以这样
1、先查看所有的镜像。
docker ps -a
2、docker exec -it mysql bash进入 容器bash,就可以操作了。
常规的调优手段
3、show processlist(查看链接session状态)
我们为什么要查看session状态呢?先看看图形
我们用这个命令主要是来看看当前mysql是否有压力,有没有什么慢SQL正在执行之类的,都在跑什么sql语句,这个命令是实时变化的。
通过Time我们可以看到那条sql语句用的时间比较长。
host是用户地址,可以来追踪问题用户。
显示当前连接的执行的命令,一般就是休眠或空闲(sleep),查询(query),连接(connect)
State:显示使用当前连接的sql语句的状态,很重要的列,后续会有所有的状态的描述,请注意,state只是语句执行中的某一个状态,一个 sql语句,已查询为例,可能需要经过copying to tmp table,Sorting result,Sending data等状态才可以完成
Info: 线程执行的sql语句,如果没有语句执行则为null。这个语句可以使客户端发来的执行语句也可以是内部执行的语句
优化:从上到下排列
-- 查询非 Sleep 状态的链接,按消耗时间倒序展示,自己加条件过滤 select id, db, user, host, command, time, state, info from information_schema.processlist where command != 'Sleep' order by time desc
kill使用:
-- 查询执行时间超过2分钟的线程,然后拼接成 kill 语句
select concat('kill ', id, ';')
from information_schema.processlist
where command != 'Sleep'
and time > 2*60
order by time desc
一些问题会导致连锁反应,而且不太好定位,有时候以为是慢查询,很可能是大多时间是在等在CPU、内存资源的释放,所以有时候同一个查询消耗的时间有时候差异很大
总结了一些常见问题:
- CPU报警:很可能是 SQL 里面有较多的计算导致的
- 连接数超高:很可能是有慢查询,然后导致很多的查询在排队,排查问题的时候可以看到”事发现场“类似的 SQL 语句一大片,那么有可能是没有索引或者索引不好使,可以用:
explain分析一下 SQL 语句
4、explain
explain+SQL语句即可

id:表示语句执行操作表的顺序,id相同,执行顺序从上往下,id不同,id值越大,优先级越高,越先执行
select_type:查询类型,主要区别普通查询,联合查询,子查询等复杂查询。
1、simple:简单的select查询,查询中不包含子查询或者UNION
2、primary:查询中若包含任何复杂的子部分,最外层查询被标记
3、subquery:在select或where列表中包含子查询
4、derived:在from列表中包含的子查询被标记为derived(衍生),MySQL会递归执行这些子查询,把结果放到临时表中
5、union:如果第二个select出现在UNION之后,则被标记为UNION,如果union包含在from子句的子查询中,外层select被标记为derived
6、union result:UNION 的结果
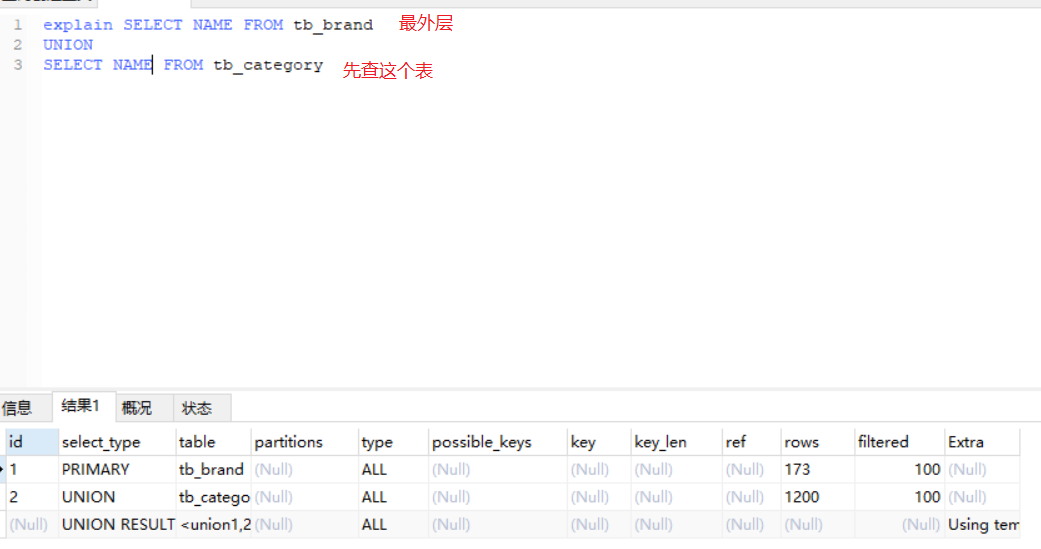
table:输出的行所引用的表
type:显示连接类型,按照从最佳到最坏类型排序
1、system:表中仅有一行=系统表,这是const联结类型的一个特例。
2、const:表示通过索引一次就找到,const用于比较primary key或者unique索引。因为只有匹配一行数据,所以如果将主键置于where列表中,mysql能将该查询转换为一个常量。
3、eq_ref:唯一性索引扫描,对于每个索引建,表中只有一条记录与之匹配。常见于唯一索引或者主键扫描。
4、ref:非唯一性索引扫描,返回匹配某个单独指的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,可能会找多个符合条件的行,属于查找和扫描的混合体。
5、range:只检索给定范围的行,使用一个索引来选择行,key列显示使用了哪个索引,一般就是where语句中出现了between,in等范围的查询。这种范围扫描索引扫描比全表扫描要好,因为它开始于索引的某一个点,而结束另一个点,不用全表扫描。
6、index:index与all却别,index类型只遍历索引树,通常比all快,因为索引文件比数据文件小很多。
7、all:遍历全表以找到匹配的行。
一般保证查询达到range级别,最好能达到ref
possible_keys:指出mysql能使用哪个索引在该表中找到行
key:显示mysql实际决定使用的键(索引)。如果没有选择索引,键是null。查询中如果使用覆盖索引,则该索引和查询的select子弹重叠
key_len:表示索引中使用的字节数,在不损失精度的情况下(索引准确的情况下),长度越短越好
ref:显示索引的哪一列被使用了,如果有可能是一个常数,哪些列或常量被用于查询索引列上的值。
rows:根据表统计信息以及索引选用情况,大致估算出找到所需的记录所需要读取的行数。
extra:包含不适合在其他列中显示,但是十分重要的额外信息。