代码
#-*- encoding:utf-8 -*-
import pandas as pd
from pandas import DataFrame
import csv
import os
from openpyxl.utils import get_column_letter, column_index_from_string
#原文:
#https://www.cnblogs.com/SH170706/p/10450239.html
#https://blog.csdn.net/wangxingfan316/article/details/79628463
#https://blog.csdn.net/brucewong0516/article/details/79097909
#https://blog.csdn.net/qq_38115310/article/details/98031934
#https://blog.csdn.net/AuserBB/article/details/79269562
#https://www.cnblogs.com/programmer-tlh/p/10461353.html
# 获取列的索引
def get_column_index(column_name):
dic={
'所属店铺' : 2,
'日期' : 3,
'交易金额' : 4,
'访客人数' : 5,
'支付人数' : 6,
'支付转化率' : 7,
'客单价' : 8,
'uv价值' : 9,
}
return dic[column_name]
# 获取一列值
def get_column_value(file_name, column_name):
with open(file_name, newline='', encoding='UTF-8') as csvfile:
rows = csv.reader(csvfile)
arr1 = []
for row_index,row in enumerate(rows):
if row_index==0:# 跳过首行,首行都是列名
continue
if isinstance(row,list):
if len(row)==10:
column_index = get_column_index(column_name)
value = str(row[column_index]).replace(',', '')
arr1.append(value)
#arr1.append(','.join(row).split(',')[column_index])# 这句代码是有bug的,单元格如果出现逗号就有问题!!!
return arr1
# 获取店铺名称
def get_store_name(file_name):
return get_column_value(file_name, '所属店铺')[0]
# 创建sheet
def create_sheet(column_name):
path = "./files/"
files = os.listdir(path)
dic1 = {}
# 生成首列
arr_date = get_column_value(path+files[0], '日期')
dic1['日期'] = arr_date
# 遍历文件
for filename in files:
fullname = path + filename# excel的相对路径
# 生成数据列
store_name = get_store_name(fullname)
arr_value = get_column_value(fullname, column_name)
dic1[store_name] = arr_value
return dic1
# 生成excel
writer = pd.ExcelWriter('1.xlsx')
arr_column_names=['交易金额', '访客人数', '支付人数', '支付转化率', '客单价', 'uv价值']
for item in arr_column_names:
pd.DataFrame(create_sheet(item)).to_excel(writer, sheet_name=item, index=False)
# 列固定宽度
for index, item in enumerate(writer.sheets):
max_column = writer.sheets[item].max_column
for i in range(max_column):
letter = get_column_letter(i+1)
writer.sheets[item].column_dimensions[letter].width = 20
writer.save()
效果

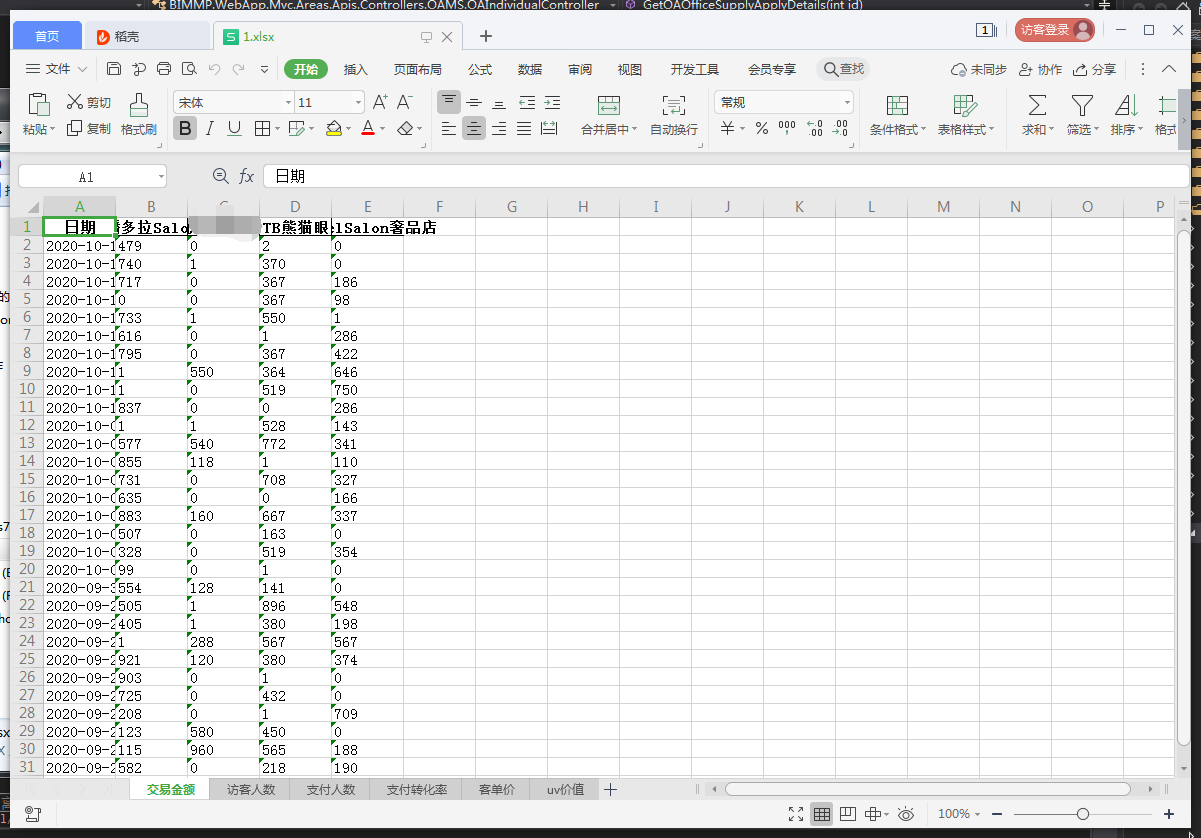
mark
以后空了再编译成exe文件传上来