今天使用sqoop导入一张表,我去查数据库当中的数据量为650条数据,但是我将数据导入到hive表当中的时候出现了563条数据,这就很奇怪了,我以为是数据错了,然后多导入了几次数据发现还是一样的问题。
然后我去查数据字段ID的值然后发现建了主键的数据怎么可能为空的那。然后我去看数据库当中的数据发现,数据在存入的时候不知道加入了什么鬼东西,导致数据从哪一行截断了,导致多出现了三条数据。下面是有问题的字段。

这里我也不知道数据为啥会是这样,我猜想是在导入数据的时候hive默认行的分割符号是按照 的形式导入进来的,到这里遇到了这样的字符就对其按照下一行进行对待将数据截断了。
然后我测试了一直自定义的去指定hive的行的分割符号,使用--lines-terminated-by 指定hive的行的分割符号,但是不幸的是好像这个是不能改的。他会报下面的错误:
FAILED: SemanticException 1:424 LINES TERMINATED BY only supports newline '
' right now. Error encountered near token ''164''
于是上网找资料,然后发现可以使用一个配置清除掉hive当中默认的分割符号,然后导入数据,配置如下:
--hive-drop-import-delims 这个参数是去掉hive默认的分割符号,加上这个参数然后在使用--fields-terminated-by 指定hive的行的分割符号
最终数据导入成功,数据量和原来数库当中的数据一致。
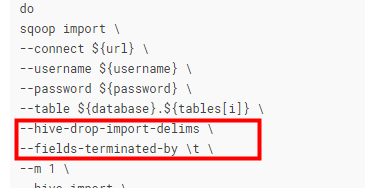
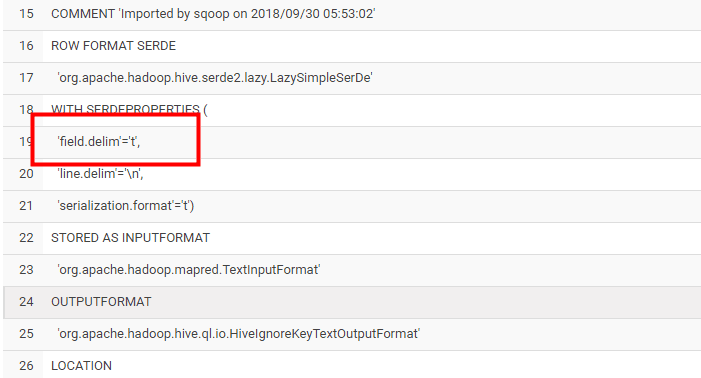
上面是sqoop脚本的部分内容,下面是执行完hive之后,hive创建的表,字段之间默认的分割符号。
至此问题得到了解决。