2019/10/26
第一章:Python介绍
Python是一种解释型,面向对象的语言。特点是:
- 可读性强
- 简洁,简洁
- 面向对象
- 免费开源
- 可移植性和跨平台性
- 丰富的库
- 可扩展性
应用范围:1、人工智能,2、数据分析,3、Web开发,4、爬虫,5、自动化测试运维
Python开发环境,英文IED (Integrated Development Environment 集成开发环境)
推荐IED
PyCharm
Python的交互模式(脚本shell模式)
1.进入命令行窗口,输入:python
2.>>> 即为提示符
3.退出交互模式:
- Ctr+Z 和回车
- 输入quit()
- 直接关闭命令行窗口
4.中断程序执行:ctr+C
第二章:编程基础概念
Python程序的构造
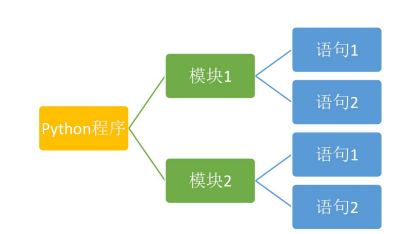
- Python程序由模块组成,一个模块对应Python的源文件,一般后缀名是:.py
- 模块由语句组成,运行Python时,按照模块中语句的顺序依次执行。
- 语句是Python程序的构造单元,用于创建对象,变量赋值,调用函数,控制语句等
对象:
Python中一切皆对象。每个对象由:标识(Identity) 、类型(type)、值(value)组成
1. 标识用于唯一标识对象,通常对应于对象在计算机内存中的地址。使用内置函数 id(obj) 可返回对象 obj 的标识。
2. 类型用于表示对象存储的“数据”的类型。类型可以限制对象的取值范围以及可执行的 操作。可以使用 type(obj)获得对象的所属类型。
3. 值表示对象所存储的数据的信息。使用 print(obj)可以直接打印出值。
- eg:
- a = 3
- b = "我爱你"
- id(a)
- type(a)
- print(a)
- id(b)
- type(b)
- print(b)

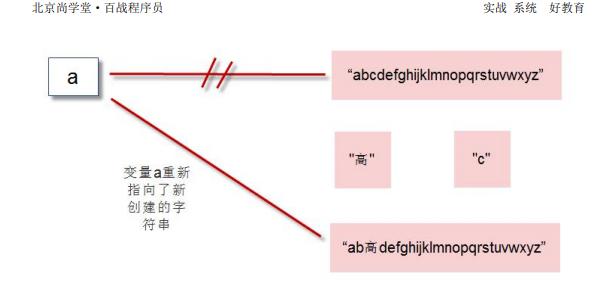
引用:
在Python中,变量也成为:对象的引用。因为,变量存储的就是对象的地址。
变量通过地址引用了“对象”
变量位于:栈内存(压栈出栈等细节,后续再介绍)。
对象位于:堆内存。
·Python 是动态类型语言 变量不需要显式声明类型。根据变量引用的对象,Python 解释器自动确定数据类型。
·Python 是强类型语言 每个对象都有数据类型,只支持该类型支持的操作
删除变量和垃圾回收机制
a = 1
del a
通过del 语句来删除变量。如果对象没有变量引用,就会被垃圾回收器回收,清空内存空间。
后面没有跟括号的叫语句,跟着括号的叫方法 比如print()
链式赋值
x = y = 12
系列解包赋值
a, b, c = 4, 5, 6
# a = 4, b = 5 , c = 6
关于常量:Python中没有常量的,没有语法规则限制改变一个常量的值
常量的命名规则:全大写
PI = 3.14
最基本内置数据类型和运算符
1.整型 :整数 12,233
2.浮点型: 小数 3.14, 或者科学计数法 314e-2
3.布尔型 : 真假 True False
4.字符串型 由字符串组成的序列 “abc'
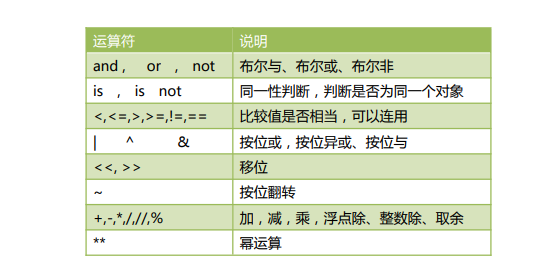
运算符
基本运算符
注意除法
/ 这是浮点数除法
// 整数除法
% 取余
比较运算符
== 等于
!= 不等于
>大于
<小于
>= 大于等于
<=小于等于
逻辑运算符
or 逻辑或
and 逻辑与
not 逻辑非
同一运算符
is 判断两个标识符是不是引用同一个对象
is not 判断两个标识符是不是引用不同对象
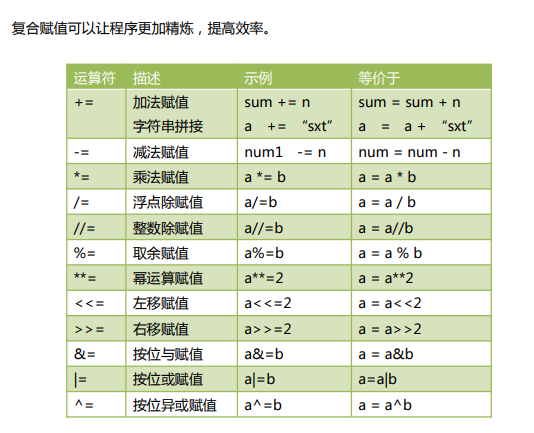
复合运算符:
is 与 == 的区别:
is 用于判断两个变量引用对象是否为同一个,既比较对象的地址
== 用于判断引用变量引用的值是否相等,默认调用对象的__eq__()方法
整数缓存问题 Python 仅仅对比较小的整数对象进行缓存(范围为[-5, 256])缓存起来,而并非是所有整数对 象。
需要注意的是,这仅仅是在命令行中执行,而在 Pycharm 或者保存为文件执行,结果是不一样 的,这是因为解释器做了一部分优化(范围是[-5,任意正整数])。
·总结
1、is 比较两个对象的 id 值是否相等,是否指向同一个内存地址;
2、== 比较的是两个对象的内容是否相等,值是否相等;
3、小整数对象[-5,256]在全局解释器范围内被放入缓存供重复使用;
4、is 运算符比 == 效率高,在变量和 None 进行比较时,应该使用 is。
整数:
Python 中,除了10进制,还有其他三种进制:
0b 或者 0B, 二进制 0 1 逢二进一
0o 或者 0O 八进制 0 1 2 3 4 5 6 7 逢 八进一
0x 或者 0X 十六进制 0 1 2 3 4 5 6 7 8 9 a b c d e f 逢 十六进一
类型转换:
Int()
float()
str()
2.1 字符串
创建字符串, 单引号 或者 又引号 '' ""
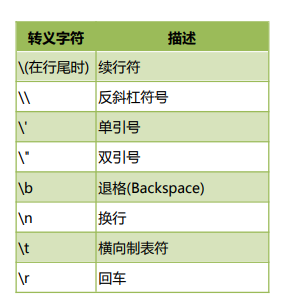
转义字符
字符串拼接
(1) 如果+两边都是字符串,则直接拼接,也可以用+号拼接
字符串复制
使用*可以实现字符串复制
a = 'Sxit*3'
a
'SxitSxitSxit'
不换行打印
end = "任意字符串”
Input 获取输入
[] 提取字符串 str[0]
replace()实现字符串替换

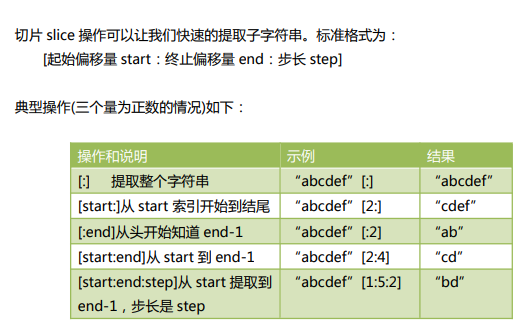
字符串切片slice操作

split()分割 和 join()合并

字符串经过split 转换后 变成 了 列表
列表经过''.join() 转换后,变成了字符串

字符串常用 方法 汇总
去除信息
1.去除首尾信息 str.strip("")
2.去除首信息 str.lstrip("") left
3.去除尾信息 str.rstrip("") right
大小写转换


格式排版

其他方法
1. isalnum() 是否为字母或数字
2. isalpha() 检测字符串是否只由字母组成(含汉字)。
3. isdigit() 检测字符串是否只由数字组成。
4. isspace() 检测是否为空白符
5. isupper() 是否为大写字母
6. islower() 是否为小写字母
字符串的格式化输出
3种
print('%d + %d = %d' % (a, b, a+b))
print('{} + {} + {} '.format(a,b, a+b))
下面这种是format的语法糖
print(f'{a} + {b} = {a+b}')
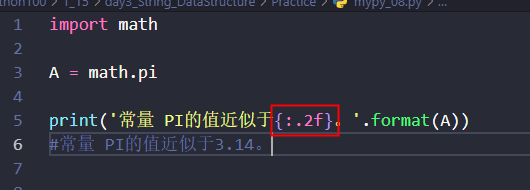
限制小数点的格式化数字输出


第三章 序列 (数据类型)
3.1 列表 list
列表:用于存储任意数目、任意类型的数据集合。
列表是内置可变序列,是包含多个元素的有序连续的内存空间。定义的标准语法格式 :
a = [10, 20, 30, 40]
10,20 这些叫 列表的元素。这些元素可以是任意类型。比如:a = [10, 20, 'abc',True]
列表常用的方法

列表的创建:
a = [0, 1, 'a']
a = [] # 创建 一个空列表
使用list()方法来创建
a = list('helloworld') # ['h','e','l'....]
a = list() #创建一个空列表
使用range() 方法来创建一个整数列表
a = list(range(5)) # [0,1,2,3,4]
推导式生成列表
>>> a = [x*2 for x in range(5)] #循环创建多个元素
>>> a
[0, 2, 4, 6, 8]
>>> a = [x*2 for x in range(100) if x%9==0] #通过 if 过滤元素
>>> a
[0, 18, 36, 54, 72, 90, 108, 126, 144, 162, 180, 198]
常用方法:
在尾部最快添加一个元素用 append()
a = [1,2]
a.append(3)
a = [1,2,3]
在尾部添加多个元素用 extend([])
a.extend([4,5,6])
a = [1,2,3,4,5,6]
在指定位置添加元素用 insert( , )
a.insert(1, 1.2)
+ 运算符
a += [50]
生成新的列表对象。
* 乘法扩展,生成新列表,原列表多次重复
a *= 2
元素删除
del 删除指定元素
del a[0]
pop() 方法 删除并返回指定位置的元素,若没有指定就删除最后一个
a.pop()
remove() 方法 删除首次出现的指定元素,若不存在元素会抛出异常
a.remove(2)
index()获得指定元素在列表中首次出现的索引
count()获得指定元素在列表中出现的次数
len()返回列表长度
列表的遍历
for obj in listObj:
print(obj)
复制列表所有的元素到新列表对象 如下代码实现列表元素的复制了吗?
list1 = [30,40,50]
list2 = list1
只是将 list2 也指向了列表对象,也就是说 list2 和 list2 持有地址值是相同的,列表对象本 身的元素并没有复制。
我们可以通过如下简单方式,实现列表元素内容的复制:
list1 = [30,40,50]
list2 = [] + list1
list2 = list1[:] # 切片复制也可以
成员资格判断 判断列表中是否存在指定的元素,我们可以使用 count()方法,返回 0 则表示不存在,返回 大于 0 则表示存在。但是,一般我们会使用更加简洁的 in 关键字来判断,直接返回 True 或 False。 >>> a = [10,20,30,40,50,20,30,20,30] >>> 20 in a True >>> 100 not in a True >>> 30 not in a False
列表的排序:
修改原列表,不建新列表的排序
a = [20,10,30,40]
a.sort() # 默认升序
a.sort(reverse = True) # 降序
import random
random.suffle(a) #打乱顺序
建新列表的排序
b = sorted(a) # 升序建立新的列表对象
reversed()返回迭代器 内置函数 reversed()也支持进行逆序排列,与列表对象 reverse()方法不同的是,内置函数 reversed()不对原列表做任何修改,只是返回一个逆序排列的迭代器对象。 >>> a = [20,10,30,40] >>> c = reversed(a) >>> c <list_reverseiterator object="" at="" 0x0000000002bcceb8=""> >>> list(c) [40, 30, 10, 20] >>> list(c) [] 我们打印输出 c 发现提示是:list_reverseiterator。也就是一个迭代对象。同时,我们使用 list(c)进行输出,发现只能使用一次。第一次输出了元素,第二次为空。那是因为迭代对象 在第一次时已经遍历结束了,第二次不能再使用。
元组 tuple
元组 tuple 列表属于可变序列,可以任意修改列表中的元素。元组属于不可变序列,不能修改元组中的 元素。因此,元组没有增加元素、修改元素、删除元素相关的方法。 因此,我们只需要学习元组的创建和删除,元组中元素的访问和计数即可。元组支持如 下操作: 1. 索引访问 2. 切片操作 3. 连接操作 4. 成员关系操作 5. 比较运算操作 6. 计数:元组长度 len()、最大值 max()、最小值 min()、求和 sum()等。
元组总结
1. 元组的核心特点是:不可变序列。
2. 元组的访问和处理速度比列表快。
3. 与整数和字符串一样,元组可以作为字典的键,列表则永远不能作为字典的键使用。
字典 dict
用法总结:
1. 键必须可散列 (1) 数字、字符串、元组,都是可散列的。
(2) 自定义对象需要支持下面三点:
1 支持 hash()函数
2 支持通过__eq__()方法检测相等性。
3 若 a==b 为真,则 hash(a)==hash(b)也为真。
2. 字典在内存中开销巨大,典型的空间换时间。
3. 键查询速度很快
4. 往字典里面添加新建可能导致扩容,导致散列表中键的次序变化。因此,不要在遍历字 典的同时进行字典的修改。