数据集的链接:行人检测数据集voc数据集(100张)
原始图片和.xml数据目录结构如下:
.
└── data
├── 003002_0.jpg
├── 003002_0.xml
├── 003002_1.jpg
├── 003002_1.xml
├── 003008_1.jpg
├── 003008_1.xml
└── .......
└── xml2voc2007.py
- data目录下就是你的数据集原始图片,加上标注的.xml文件。
- xml2voc2007.py源码放到这篇文章的最后边。
在labelme2coco.py文件的目录下,打开命令行执行:
python xml2voc2007.py --input_dir data --output_dir VOCdevkit
- --input_dir:指定data文件夹,默认输入为xml2voc2007.py同级目录下的data文件夹。
- --output_dir:指定你的输出文件夹,默认输出为xml2voc2007.py同级目录下的VOCdevkit文件夹(没有的话就会创建)。
执行结果如下图:
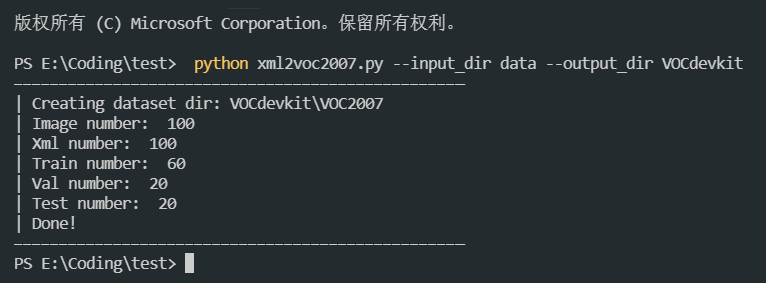
生成的voc数据集目录结构如下:
.
└── VOCdevkit
└── VOC2007
├── Annotations
│ ├── 003002_0.xml
│ ├── 003002_1.xml
│ ├── 003008_1.xml
│ └── .......
├── ImageSets
│ └── Main
│ ├── test.txt
│ ├── train.txt
│ ├── trainval.txt
│ └── val.txt
└── JPEGImages
├── 003002_0.jpg
├── 003002_1.jpg
├── 003008_1.jpg
└──.......
如果想调整训练集验证集的比例,可以在labelme2coco.py源码中搜索 percent_trainval (训练集和验证集在总数中的占比),percent_train,(训练集在percent_trainval中的占比)
xml2voc2007.py源码:
# 命令行执行: python xml2voc2007.py --input_dir data --output_dir VOCdevkit
import argparse
import glob
import os
import random
import os.path as osp
import sys
import shutil
percent_train = 0.9
# 主程序执行
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("--input_dir", default="data", help="input annotated directory")
parser.add_argument("--output_dir", default="VOCdevkit", help="output dataset directory")
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
print("| Creating dataset dir:", osp.join(args.output_dir, "VOC2007"))
# 创建保存的文件夹
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "Annotations")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "Annotations"))
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "ImageSets")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "ImageSets"))
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "ImageSets", "Main")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "ImageSets", "Main"))
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "JPEGImages")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "JPEGImages"))
# 获取目录下所有的.jpg文件列表
total_img = glob.glob(osp.join(args.input_dir, "*.jpg"))
print('| Image number: ', len(total_img))
# 获取目录下所有的joson文件列表
total_xml = glob.glob(osp.join(args.input_dir, "*.xml"))
print('| Xml number: ', len(total_xml))
num_total = len(total_xml)
data_list = range(num_total)
num_tr = int(num_total * percent_train)
num_train = random.sample(data_list, num_tr)
print('| Train number: ', num_tr)
print('| Val number: ', num_total - num_tr)
file_train = open(
osp.join(args.output_dir, "VOC2007", "ImageSets", "Main", "train.txt"), 'w')
file_val = open(
osp.join(args.output_dir, "VOC2007", "ImageSets", "Main", "val.txt"), 'w')
for i in data_list:
name = total_xml[i][:-4] + '\n'
if i in num_train:
file_train.write(name[5:])
else:
file_val.write(name[5:])
file_train.close()
file_val.close()
if os.path.exists(args.input_dir):
# root 所指的是当前正在遍历的这个文件夹的本身的地址
# dirs 是一个 list,内容是该文件夹中所有的目录的名字(不包括子目录)
# files 同样是 list, 内容是该文件夹中所有的文件(不包括子目录)
for root, dirs, files in os.walk(args.input_dir):
for file in files:
src_file = osp.join(root, file)
if src_file.endswith(".jpg"):
shutil.copy(src_file, osp.join(args.output_dir, "VOC2007", "JPEGImages"))
else:
shutil.copy(src_file, osp.join(args.output_dir, "VOC2007", "Annotations"))
print('| Done!')
if __name__ == "__main__":
print("—" * 50)
main()
print("—" * 50)