Django之DB数据库优化
取所有书的书名
res = models.Book.objects.values("title") #拿到的是一个列表套字典
还要for循环再res.get("title")
res=models.Book.objects.only("title")
拿到的是Book对象列表,此Book对象只封装了书名title属性
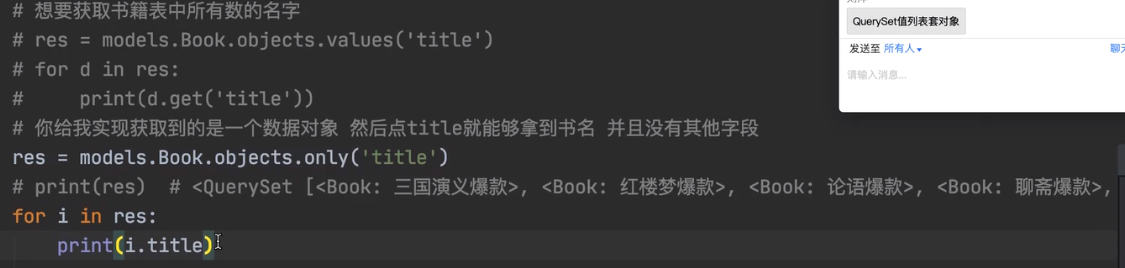
此时你可以i.price尽管Book对象里面没有封装price,但是仍然可以查到,但是会重新去DB里面查询
only括号里面没有的字段,会重新查询
而res=models.Book.objects.all()
查到的对象,已经有了对象所有的属性,想查什么就查什么,不会再走数据库。
defer()
res=models.Book.objects.defer("title")
拿到的仍是数据对象,他与oble()刚好相反,defer括号内放的字段不在查询出来的对象里面
想查询title字段,必须重走数据库,而如果查询的是非括号内字段,不再走数据库,可以直接.来获得。
select_related和prefetch_related 与跨表有关
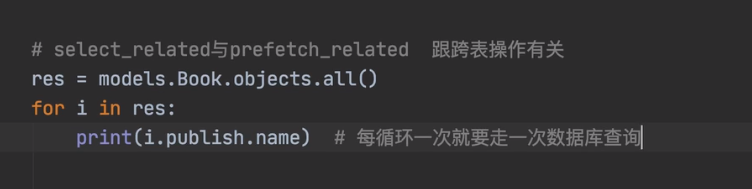
这里从book表,跨表查看出版社名字。会导致查出来的Book对象,每个都去跨表查一次出版社名

res=models.Book.obejcts.select_related("publish")
print(res)

这样网络请求少了,数据IO少了,相当于进行了优化,但是表如果很大,那么拼表的耗时会很长。
select_related里面只能放外键字段。只能放一对一和一对多
不能放多对多
pretch_related
多表操作除了连表操作,还可以用子查询,一张表的查询结果,当做领一张表的查询条件,比连表查询多了一次查询

子查询虽然查询次数多,但是单表先查询可能1秒,加起来2秒,不一定就慢于连表的时间,一定要看实际情况。
使用者感觉不出来两个方法的区别,只是内部的原理不同。