1.使用vmware 创建了两个虚拟机
2.分别更改ip可参考url: https://www.cnblogs.com/gzgBlog/p/13693754.html
此处主节点IP : 192.168.10.11
从节点IP: 192.168.10.12
3.分别修改主机名:vi /etc/hostname ,修改完毕,保存退出(重启后生效)

4.配置本地dns(ip和域名的映射关系) vi /etc/hosts

再两台机器分别使用ping 命令测试是否配置成功,如下表示成功

5.配置免密登录
配置前,先确保安装了openssh-server,默认是不安装的
输入dpkg --list | grep ssh,如果没有openssh-server,执行以下命令安装:
sudo apt-get install openssh-server
服务器A如果要免密码登录到服务器B时,需要在服务器A上生成密钥对,将生成的公钥上传到服务器B上,并把公钥追加到服务器B的authorized_keys信任文件中。
5.1.此处再master主机生成密钥 : ssh-keygen -t rsa -P ''
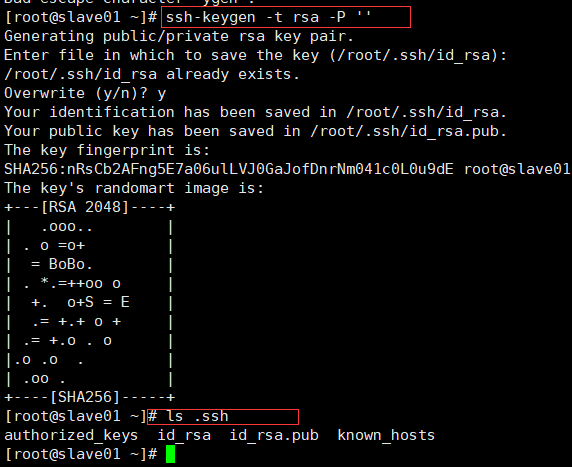
5.2将master公钥复制到slave01 命令: scp .ssh/id_rsa.pub root@slave01:~ 使用ssh验证是否免密码

5.3如果不成功关闭防火墙重试:
立即生效(重启后失效):service iptables stop
重启后永久生效:chkconfig iptables off
6.配置jdk环境
6.1解压jdk压缩包 tar -zvxf ./jdk-8u211-linux-x64.tar.gz

配置环境变量 vi /etc/profile ,后边追加
export JAVA_HOME=/app/jdk1.8.0_211
export PATH=$PATH:$JAVA_HOME/bin
保存并退出,使用:source /etc/profile 使配置生效
使用 java -version 出现如下信息表示jdk配置成功

7. 配置hadoop环境
7.1解压hadoop压缩包 tar -zvxf ./hadoop-2.2.0-64bit.tar.gz
7.2 在/etc/profile 中添加hadoop配置:vi /etc/profile
7.3hadoop-env.sh中添加java环境
进入 /app/hadoop-2.2.0/etc/hadoop 在hadoop-env.sh中添加JAVA_HOME环境

8.验证
使用 hadoop version 出现版本信息表示配置成功

Hadoop安装可以是单节点、伪分布式和完全分布式。这里我们着重介绍伪分布式和完全分布式。伪分布式是在一台机器上模拟分布式,主要用于测试;而完全分布式是由两个及两个以上的节点组建的集群,是真正的分布式。下面介绍伪分布式和完全分布式的安装过程。