hadoop3的jdk和基础环境搭建参考 url: https://www.cnblogs.com/gzgBlog/p/13702720.html
处节点设置为:
| IP | 主机名 | 节点 |
| 192.168.10.11 | mater | NameNode(NN)、DataNode(DN) |
| 192.168.10.12 | slave01 | Secondary NameNode(SN)、DataNode(DN) |
| 192.168.10.13 | slave02 | DataNode(DN) |
三台机器分别修改ip和对应主机名(此处不做介绍)
配置需要 master 免密登录 slave01和slave02(此处不做介绍)
master中配置解压jdk, tar -zvxf jdk安装包,
解压hadoop安装包,tar -zvxf ./appinstall/hadoop-3.2.1.tar.gz,环境变量中添加 jdk和hadoop vim /etc/profile

是配置文件生效,source /etc/profile
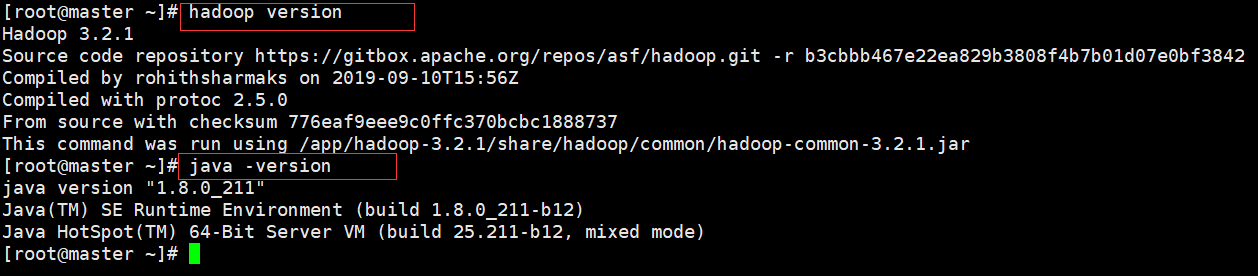
配置完成可分别使用 Java -version 和 hadoop version 测试,出现如下信息表示配置成功
1.部署及配置
Hadoop的配置涉及以下几个文件,分别是:hadoop-env.sh、core-site.xml、hdfs-site.xml和workers。其中,
hadoop-env.sh是Hadoop运行环境变量配置;
core-site.xml是Hadoop公共属性的配置;
hdfs-site.xml是关于HDFS的属性配置;workers是DataNode分布配置。下面我们分别配置这几个文件。
(1)hadoop-env.sh文件(注意:=左右均不能有空格)
在/etc/hadoop/hadoop-env.sh中配置运行环境变量,在默认情况下,这个文件是没有任何配置的。我们需要配置JAVA_HOME、HDFS_NAMENODE_USER和HDFS_DATANODE_USER等,HDFS_SECONDARYNAMENODE_USER配置代码如下:
export JAVA_HOME=/app/jdk1.8.0_211
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
其中,JAVA_HOME= /app/hadoop-3.2.1 是指定JDK的位置,
HDFS_NAMENODE_USER=root是指定操作NameNode进程的用户是root。
同理,HDFS_DATANODE_USER和HDFS_SECONDARYNAMENODE_USER分别指定了操作DataNode和Secondary NameNode的用户,在这里我们设置为root用户,具体应用时,读者根据情况进行设置即可。
在这里需要注意的是,HDFS_NAMENODE_USER、HDFS_DATANODE_USER和HDFS_SECONDARYNAMENODE_USER是Hadoop 3.x为了提升安全性而引入的。
(2)core-site.xml文件
core-site.xml中主要配置Hadoop的公共属性,配置代码如下:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9820</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoopdata</value> </property> </configuration>
其中,
fs.defaultFS是指定NameNode所在的节点,在这里配置为node1;9820是默认端口;hdfs:是协议;
hadoop.tmp.dir是配置元数据所存放的配置,这里配置为/opt/hadoopdata,后续如果需要查看fsiamge和edits文件,可以到这个目录下查找。
(3)hdfs-site.xml文件
hdfs-site.xml文件中主要是HDFS属性配置,配置代码如下:
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave01:9868</value> </property> </configuration>
其中,dfs.namenode.secondary.http-address属性是配置SecondaryNameNode的节点,在这里配置为node2。端口为9868。
关于这些配置,读者可以从官网上查找,网址为http://hadoop.apache.org/docs/r3.1.0/,其中的左下角有个Configuration项,其中包括core-default.xml等配置文件。
(4)workers文件
在workers中配DataNode节点,在其中写入:
master
slave01
slave02
将hadoop和 profile 分别复制到另外两台机器上
分别使另外两天机器profile配置生效
格式化
第一次安装Hadoop需要进行格式化,以后就不需要了。格式化命令在hadoop/bin下面,执行命令: hdfs namenode -format,如下格式成功
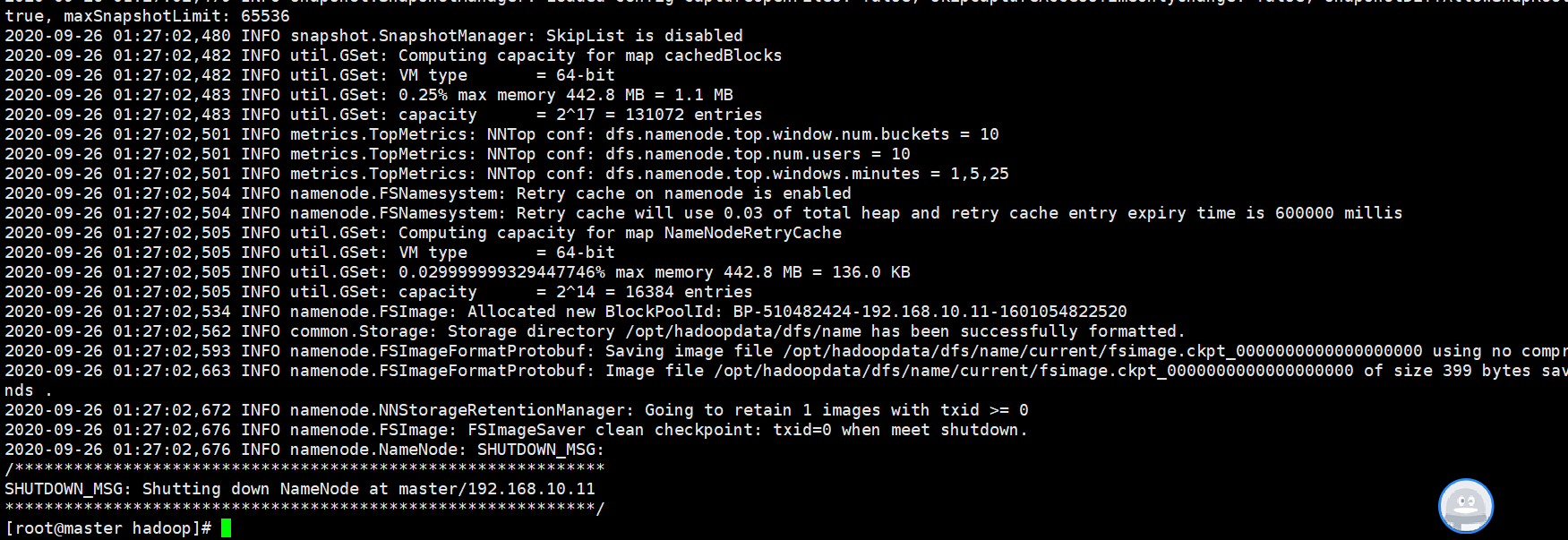
格式化后会创建一个空白的fsimage文件,可以在opt/hadoopdata/dfs/name/current中找到fsimage文件,注意此时没有edits文件。
启动命令
进入hadoop/sbin下面运行start-dfs.sh,启动HDFS集群,启动命令如下:
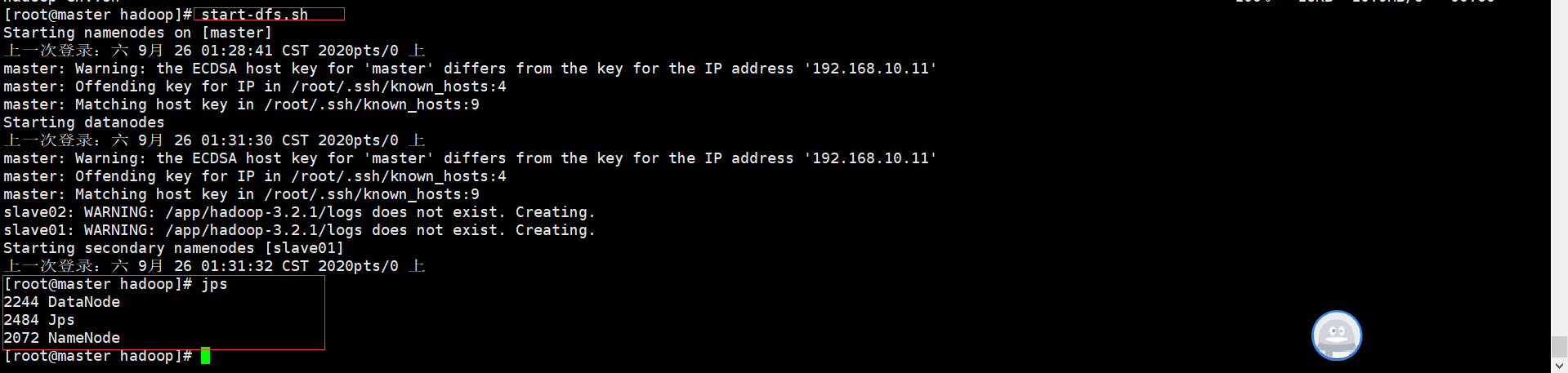
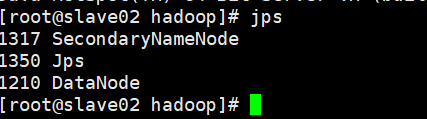
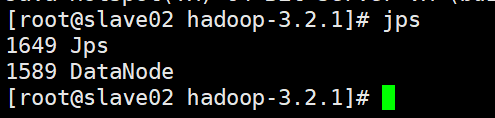
如上,表示启动成功,分别去另外两个节点查看是否启动成功,如下表示启动成功
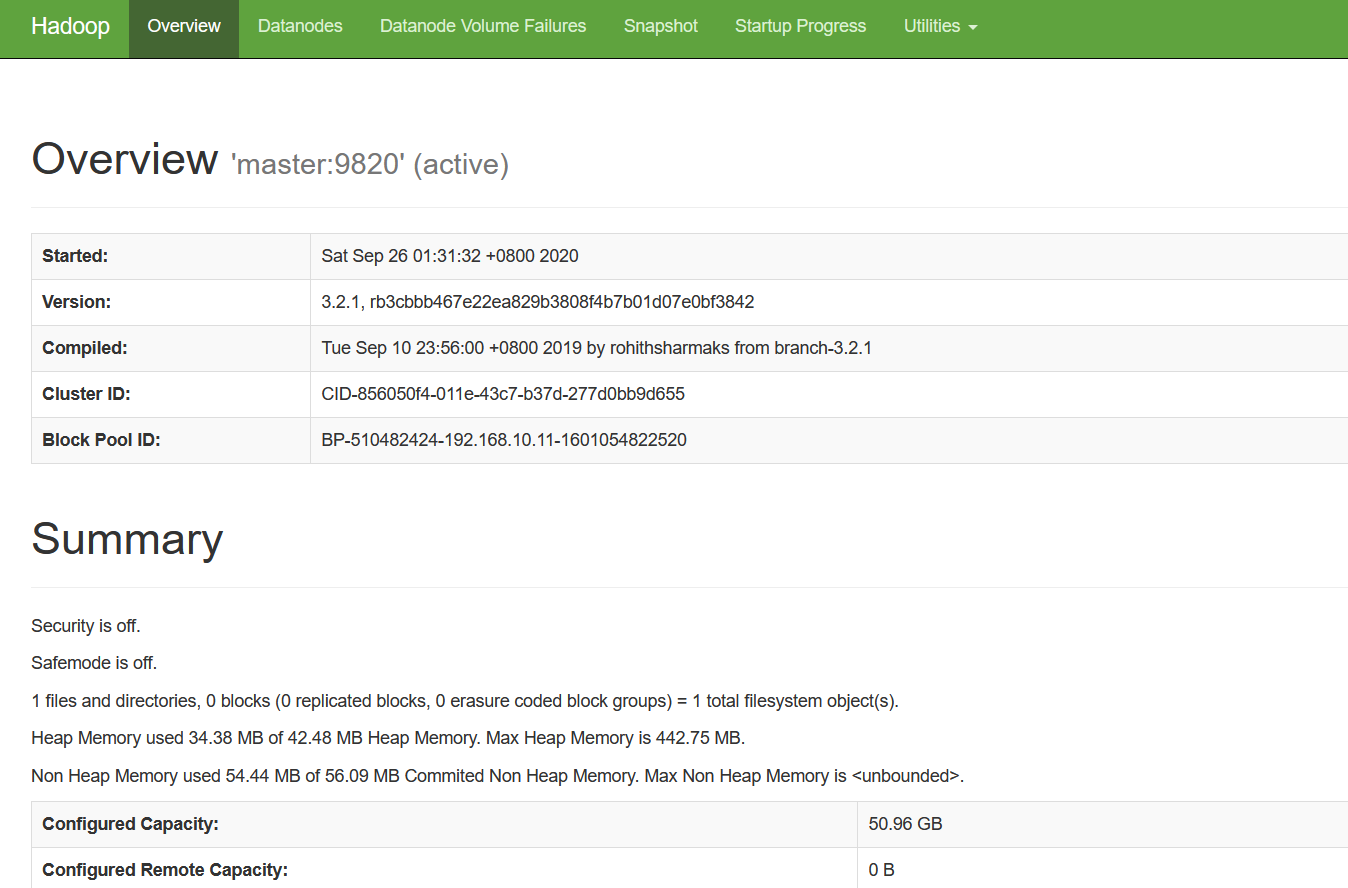
打开浏览器查看HDFS监听页面
在浏览器中输入http://ip:9870,比如这里输入http://192.168.10.11:9870/,出现以下界面则表示Hadoop完全分布式搭建成功,如图所示。
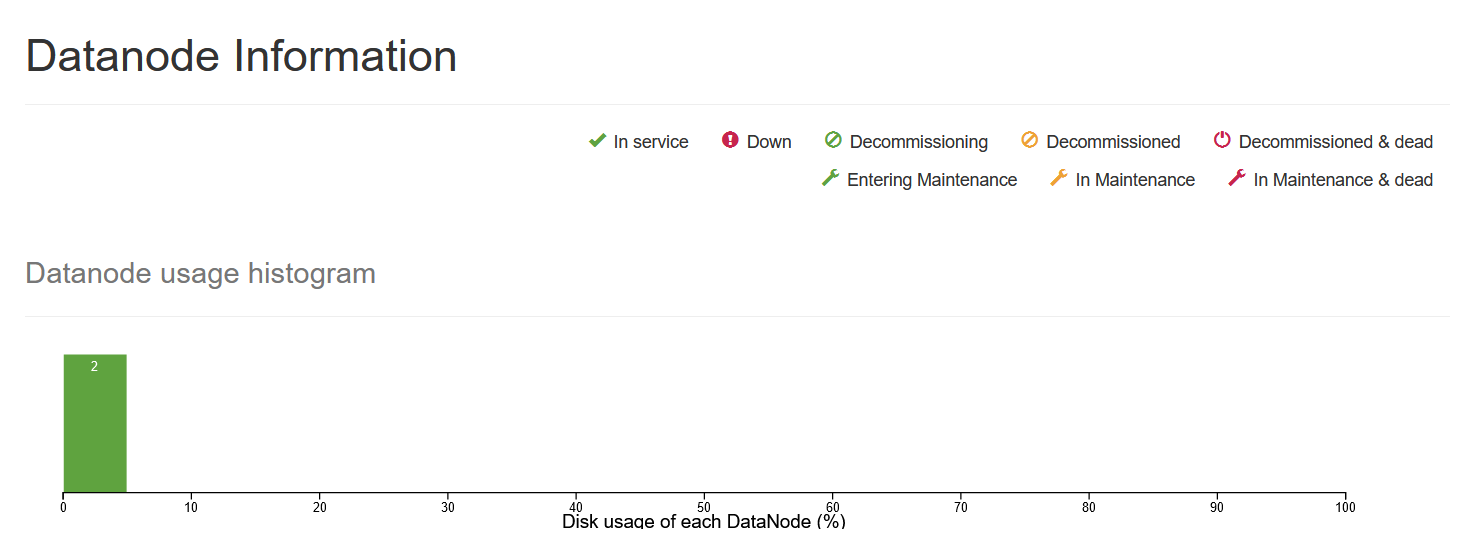
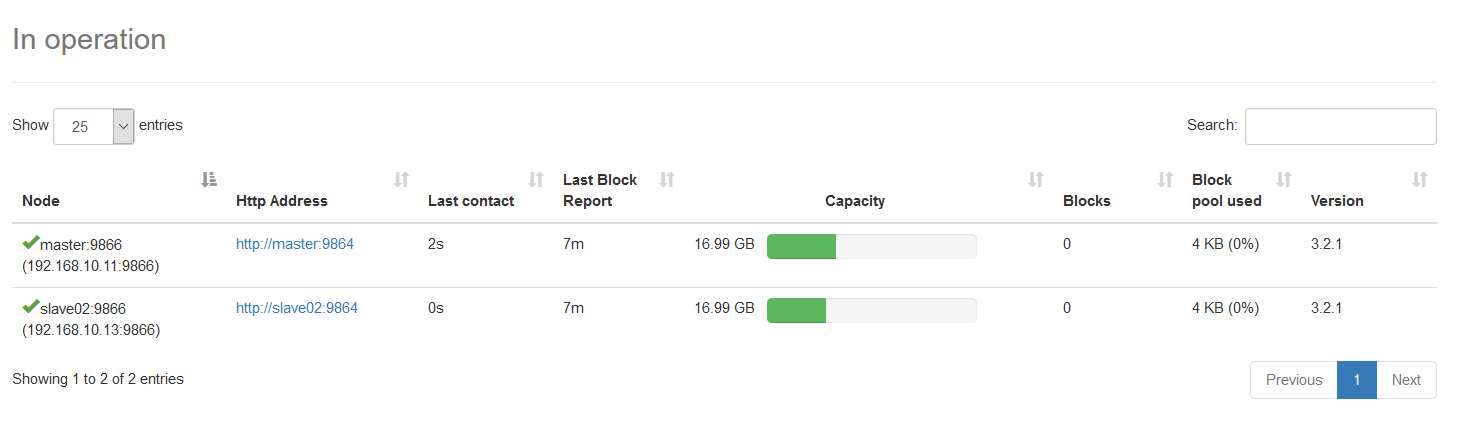
选择Datanodes选项,可以看到DataNode的利用率和DataNode的节点状态,如下图所示
上传文件
将1.txt上传到HDFS的根目录“/”下面,命令如下: hdfs dfs -put ./1.txt /
