递归函数:一个会调用自身的函数称为递归函数。凡是循环能干的事,递归也能干。
递归三部曲:
1.写出临界条件。
2.找这一次和上一次的关系。
3.假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果。
例如:要求用递归求1+2+3+4+5的和。
#思路解析:
1:找到临界条件:
if n==1:
return 1
2:找到这一次和一次的关系:
sum(1)+2=sum(2)
sum(2)+3=sum(3)
sum(1)+4=sum(4)
sum(1)+5=sum(5)
3.假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果。
sum(n-1)+n=sum(n)
#递归函数的实现:
def sum(n):
if n==1:
return 1
else:
return n+sum(n-1)
递归过程为:
5+sum(4)
5+4+sum(3)
5+4+3+sum(2)
5+4+3+2+sum(1)
5+4+3+2+1
因此最后返回的值为:5+4+3+2+1
#使用递归深度遍历目录下所有的文件和目录:
#思路,若该路径下有目录,则递归遍历。若只有文件,则打印它,不递归。
import os
import os.path
def getAllDir(path):
dirList=os.listdir(path)
for dirFile in dirList:
absPath=os.path.join(path,dirFile)
if os.path.isdir(absPath):
print('目录:'+dirFile)
getAllDir(absPath,str1)
else:
print('文件:'+dirFile)
#调用
path=r'C:UsersDesktop'
getAllDir(path)
根据递归三部曲解释这个程序:
1.写出临界条件-----》若该路径下面没有目录,for此时不能循环,退出。因此满足要求。
2.找这一次和上一次的关系。----》若该路径下有目录,则递归调用这个绝对路径,若没有,则不递归。
3.假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果。-------》为了达到下一个目录,需要本次的路径+目录合成的结果,进行递归。
栈与深度遍历:
栈:先进后出
列表的append方法和pop方法类似于压栈和出栈。
栈的应用:
深度遍历:

深度遍历的顺序的一种为ABCDEFGHKJILMN
#用非递归的方式(栈)遍历绝对路径下的所有文件和目录:
import os
import os.path
def getallDir(path):
filelist=[]
filelist.append(path)
while len(filelist)!=0:
file=filelist.pop()
if os.path.isdir(file):
print('目录:'+os.path.basename(file))
fileDirList=os.listdir(file)
for fileDir in fileDirList:
absPath=os.path.join(file,fileDir)
filelist.append(absPath)
else:
print('普通文件:'+os.path.basename(file))
#调用
getallDir(r'C:UsersDesktopProject')
#思路,每次弹出栈顶元素并访问该元素。若该元素是目录,则令其目录下的所有文件和目录进栈(以绝对路径的形式)。若该元素是普通文件,则不进行入栈操作。循环直到栈内元素为空。
队列与广度遍历:
队列:先进先出
import collections #数据的集合的模块
它封装了队列的功能:collections.deque()
queue1=collection.deque():创建一个队列,队列名叫queue1
queue1.append(value) #将value入队queue1(存数据)
value1=queue1.popleft() #出队(取数据),将队首元素赋值给value1
队列的应用:
广度遍历:
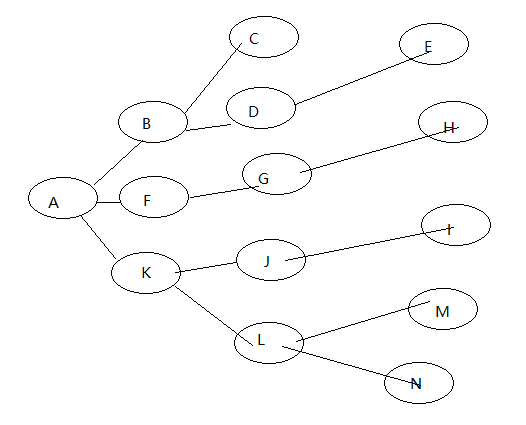
广度遍历的顺序的一种为:ABFKCDGJLEHIMN
#通过队列进行广度优先搜索遍历
import collections
import os
def WFS(path):
queue=collections.deque()
queue.append(path)
while len(queue)!=0:
file=queue.popleft()
print(os.path.basename(file))
if os.path.isdir(file):
fileList=os.listdir(file)
for fileDir in fileList:
absPath=os.path.join(file,fileDir)
queue.append(absPath)
WFS(r'C:UsersyuliangDesktopProject')
思路:将path入队,然后出队并访问该节点。若path是文件,则不做任何操作。若path是目录,则将path下面的文件和目录入队(以绝对路径的形式)。循环操作。