一、昨日内容回顾
list:
增:append insert(index,object) extend()跌带着追加
删:pop()按照索引去删除,索引值不填默认从后面删,有返回值
remove()按照元素删除
clear()清空列表
del list 从内存中删除列表
del list[index]
dle list[0:3]
del list[0:3:2]
改:
按索引改单个元素
按索引改单个元素
按切片迭代改多个元素
按切片加步长
查:
索引,切片,切片+步长,for循环
其他方法:
len()
.index()
.count()
.reverse()
.sort()
.sort(reverse=True)
list的嵌套:
略
元组:
()里面放任意数据类型,不可以增删改,可以查:索引,切片,切片加步长,for循环。
range():
当做是一个可控范围的数字列表,多与for循环结合
二、作业讲解
略
数据类型的分类
容器类数据类型
list,tuple,dict,set
非容器型数据类型
str,bool,int
可变(不可hash)的数据类型
list,dict,set
不可变(可hash)的数据类型
str,bool,int,tuple
|
容器类数据类型
|
list,tuple,dict,set
|
|
非容器型数据类型
|
str,bool,int
|
|
可变(不可hash)的数据类型
|
list,dict,set
|
|
不可变(可hash)的数据类型
|
str,bool,int,tuple
|
三、字典
why:
1列表如果存储大量的数据,查询速度相对慢一些
2列表存储的数据一般没有什么关联性
针对以上因素,python提供了一个基础数据类型:dict字典
what:
dic{'name':'alex'}以键值对形式存储的数据类型
1字典的键必须是不可变(可hash)的数据类型,唯一的不重复,值可以是任意数据类型或对象
2 字典的查询速度非常快
3字典在3.5版本之前是无序的,但是在3.6版本做了优化-字典会按照创建时的顺序排列
4字典可以存储大量的关联性数据
how:
|
增
|
dic['weight'] = 150(有则覆盖,无则添加) dic.setdefault('high',175)(有则不变,无则添加) dic.update(weight=150,high=175)(有则覆盖,无则添加) |
|
删
|
.pop('键','返回值')通过键删除键值对,如果键不存在会返回指定的返回值,如未指定会报错,返回值为被删除的值
.clear()清空
.popitem()3.5版本是随机删除键值对,3.6之后因为字典有序了所以删除最后一个。返回值是一个元组形式的(key,value),如果列表是空会报错
del dic['name']键值不存在会报错
|
|
改
|
dic['weight'] = 150(有则覆盖,无则添加)
dic2.update(dic1)用dic1更新dic2(有则覆盖,无则添加),对dic1无影响。
|
|
查
|
按照键查对应的值:
dic['key']返回对应的值,key不存在时会报错
dic.get('key','返回值')返回对应的值,key不存在返回指定返回值,默认返回none不会报错
for循环打印获取的是key值
dic.keys()返回一个类似于列表的容器的数据类型包含key值
dic.values()按照键查对应的值:
dic['key']返回对应的值,key不存在时会报错
for循环打印获取的是key值
dic.keys()返回一个类似于列表的容器的数据类型包含key
dic.values()返回一个类似于列表的容器的数据类型包含values
dic.items()返回一个类似于列表的容器的数据类型包含item(键值对是元组形式)
for k,v in dic.items():
print(k,v)#通过分别赋值遍历打印
|
其他操作及填坑
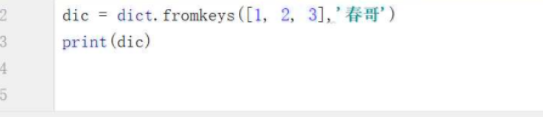
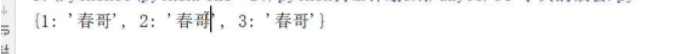


where:
为了存储大量关联性数据,方便快速查询时使用。
四、字典的嵌套
五、集合
六、知识点拾遗
格式化输出:
