一、昨日内容回顾
字典
|
增
|
setdefault()
dic['key'] = value
|
|
删
|
.pop()
.popitem()
.clear()
del dic['key']
|
|
改
|
dic['key']='v'
.update(dic)
.update(name='alex')
|
|
查
|
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
print "dict['Name']: ", dict['Name'];
print "dict['Age']: ", dict['Age'];
#以上实例输出结果:
#dict['Name']: Zara
#dict['Age']: 7
|
练习题:

二、数据类型的补充 ***
int
str
bool
list循环列表时尽量不要改变列表大小,会影响各数据的索引值
tuple
dict在循环一个字典时不能改变字典的大小,会报错。
set 元组中只有一个元素并且没有逗号“,”,则就不是元组,而就是这个元素而已
数据类型之间的转换补充:
str-->list split ***
list -->str join ***
bool:False 0和各种空
list<-->tuple
list <--dict 字典不能转化成列表 list(dict)将字典中键转换成list
tuple<--dict
list>-->set ***
三、小数据池和代码块
== 比较运算符
id()查内存地址
is 判断两端的元素内存地址是否相同,相同返回True,否则返回False
代码块
为了节省内存,提升性能。产生了两种优化机制:
个人理解每行代码是一个代码块,每个py文件是一个代码块。
1小数据池(驻留机制,驻驻存机制,字符串的缓存机制等)适应的数据类型:str(一定条件下的str满足小数据池) bool int(限制:-5~256)

2代码块内的缓存
#如果你在同一个代码块中,用同一个代码块中的缓存机制
#如果你在不同代码块中,用小数据池
四、编码转换:
ASCII:
unicode:
utf-8:
gbk:
1那么他们之间不能互相识别。(报错,或乱码)
2规定:文字通过网络传输,或者硬盘存储不能使用unicode的编码方式。
大前提:
Python3环境:
唯独str类型在内存中的编码方式是unicode
Python3版本中的str不能用于直接的网络传输和文件存储
补充一个数据类型:bytes(与str是孪生兄弟方法一毛一样)
由于中文或其他的非英文的bytes形式显示的是十六进制的形式,不方便阅读与编写,因此bytes在需要网络传输和文件存储时就要考虑一下。
str-->bytes(gbk utf-8)
即unicode --> (gbk utf-8)
.encode('gbk')#编码 表示编成gbk码
.decode('gbk')#解码 表示解成unicode码
a = "中国" b = "abc" a = a.encode("gbk").decode("gbk").encode("utf-8").decode("utf-8") b = bytes(b, encoding="utf-8") print(a) print(b)
运行结果:
中国
b'abc'
五、深浅copy
|
浅copy
|
会在内存中开辟一个新的空间,内部元素沿用原来的
|
|
深copy
|
会在内存中开辟一个新的空间,将原列表以及列表里面的可变数据类型重新创建一份,不可变的数据类型沿用原来的
|
那么切片得来的列表与原来的是什么关系呢?深copy还是浅copy呢?***
全切得到的list是对原list进行的浅copy
半切当然是得到一个新的
六、集合
set 1={'eiya', 'maya', 1, 2, 3}
集合本身是一个可变的数据类型,它要求里面的元素是一个不可变的类型(可hash)
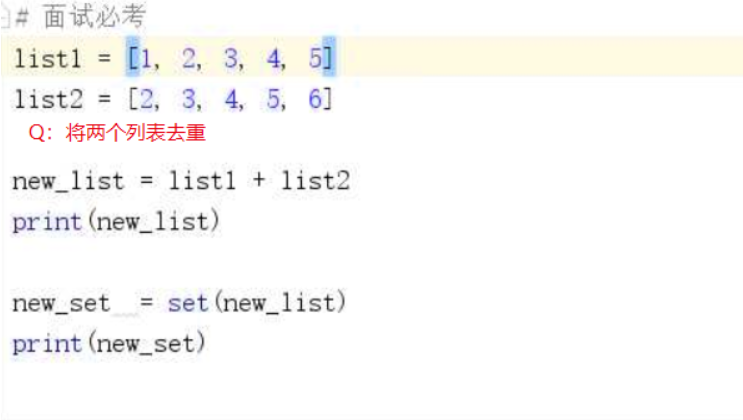
集合可以实现去重的功能
特点:
1天然去重
2数据分析
3是无序的不可以通过索引去查询
4集合里面的元素一定是不可变的(可hash)
集合的操作:
1创建:set = {'w', 'a', 'i'}
2增:set.add("wow") set.update()迭代的增加
3删:set.remove('wow') 删除一个指定的元素 set.pop()随机删除一个元素
set.clear()清空集合
del set 删除集合
4改、查 没有直接的方法完成这两个动作,但是可以通过间接的方式实现(如删掉一个,再添加一个)
其他操作:
|
交集
|
&或者.intersection()方法
|
|
并集
|
|或者.union()方法
|
|
差集
|
-或者.difference()方法
|
|
反交集
|
^或者symmetric_difference()
|
|
子集和超集
|
set1 < set2(被包含的是儿子辈儿的“,即子集)
.issuperset()方法判断返回bool值
|
| frozenset |
不可变集合,让集合编程不可变类型
|
面试超高频考题:***