存储过程,又称存储程序(英语:Stored Procedure),是在数据库存储复杂程序,以便外部程序调用的数据库对象,可以视为数据库的一种函数或子程序。
优点:
- 存储过程可封装,并隐藏复杂的商业逻辑
- 存储过程可以回传值,并可以接受参数
- 存储过程无法使用SELECT指令运行,因为它是子程序,与查看表、资料表或用户定义函数不同
创建存储过程
CREATE OR REPLACE 过程名([参数1, 参数2, ...]) AS <过程化SQL块>;
执行存储过程
CALL/PERFORM PROCEDURE 过程名([参数1, 参数2, ...]);
存储过程定义变量的两种方式
方式一:
使用set或select直接赋值,变量名以@开头。
例如:set @val = 1;
方式二:
以DECLARE关键字声明的变量,只能在存储过程中使用,称为存储过程变量。
例如:DECLARE var1 INT DEFAULT 0;
区别:
在调用存储过程时,以DECLARE声明的变量会被初始化为NULL,而会话变量(以@开头的变量则不会再次被初始化),在一个会话内只会被初始化一次。可以把会话变量当做是一个全局变量,以DECLARE声明的变量当做是函数内部的一个局部变量。MySQL只能在存储过程或函数中声明变量。
举个例子
对学生-课程数据库编写存储过程,完成下述功能:
统计离散数学的成绩分布,即按照各分数段统计人数
思路:
其实刚开始碰到这道题的时候我是没有思路的,看了别人的博客之后才知道这道题应该怎么来处理。
首先,可以声明一些变量用来存储各个分数段的学生人数,然后把各个分数段的名称和人数存储到一张表或者是一个视图中,最后将视图中的全部信息输出即可。
代码:
-- DROP PROCEDURE mycount; CREATE PROCEDURE `mycount`() BEGIN DECLARE less60 INT DEFAULT 0; DECLARE b60a70 INT DEFAULT 0; DECLARE b70a80 INT DEFAULT 0; DECLARE b80a90 INT DEFAULT 0; DECLARE larg90 INT DEFAULT 0; DECLARE courseid VARCHAR(10) DEFAULT '****'; SELECT c_id INTO courseid FROM course WHERE c_name = 'DM'; SELECT COUNT(*) INTO less60 FROM score WHERE c_id = courseid AND s_score < 60; SELECT COUNT(*) INTO b60a70 FROM score WHERE c_id = courseid AND s_score >= 60 AND s_score < 70; SELECT COUNT(*) INTO b70a80 FROM score WHERE c_id = courseid AND s_score >= 70 AND s_score < 80; SELECT COUNT(*) INTO b80a90 FROM score WHERE c_id = courseid AND s_score >= 80 AND s_score < 90; SELECT COUNT(*) INTO larg90 FROM score WHERE c_id = courseid AND s_score >= 90; CREATE TABLE score_range ( _range VARCHAR(10), number INT ); INSERT INTO score_range VALUES ('less60', less60); INSERT INTO score_range VALUES ('b60a70', b60a70); INSERT INTO score_range VALUES ('b70a80', b70a80); INSERT INTO score_range VALUES ('b80a90', b80a90); INSERT INTO score_range VALUES ('larg90', larg90); SELECT * FROM score_range; END
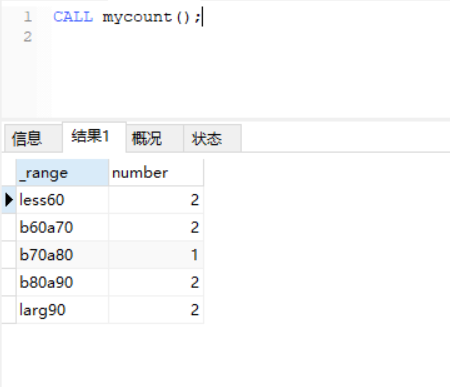
运行结果:
函数定义
CREATE OR REPLACE FUNCTION 函数名 ([参数1,参数2,...])
RETURNS <类型> AS <过程化SQL语句>;
存储过程和函数的区别
相同点:都是持久性存储模块
不同点:函数必须指定返回类型