1、为什么分库分表
随着业务快速发展,数据库中的数据量猛增,访问性能也变慢了,优化迫在眉睫。分析一下问题出现在哪儿 呢? 关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。当单表的数据量达到 1000W或100G以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。
方案1:
通过提升服务器硬件能力来提高数据处理能力,比如增加存储容量 、CPU等,这种方案成本很高,并且如果瓶颈在
MySQL本身那么提高硬件也是有很的。
方案2:
把数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库 性能的目的,如下图:将电商数据库拆分为若干独立的数据库,并且对于大表也拆分为若干小表,通过这种数据库 拆分的方法来解决数据库的性能问题。
在这里插入图片描述
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
2、什么是分库分表
就是把原本存储于一个库的数据分块存储到多个库上,把原本存储于一个表的数据分块存储到多个表上。
3、分库分表的实施策略
分库分表有垂直切分和水平切分两种。
垂直切分,即将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数据库workDB、商品数据库payDB、用户数据库userDB等,分别用于存储项目数据定义表、商品定义表、用户数据表等。
水平切分,当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如userID散列,进行划分,然后存储到多个结构相同的表,和不同的库上。例如,我们的userDB中的用户数据表中,每一个表的数据量都很大,就可以把userDB切分为结构相同的多个userDB:part0DB、part1DB等,再将userDB上的用户数据表userTable,切分为很多userTable:userTable0、userTable1等,然后将这些表按照一定的规则存储到多个userDB上。
应该使用哪一种方式来实施数据库分库分表,这要看数据库中数据量的瓶颈所在,并综合项目的业务类型进行考虑。
如果数据库是因为表太多而造成海量数据,并且项目的各项业务逻辑划分清晰、低耦合,那么规则简单明了、容易实施的垂直切分必是首选。
而如果数据库中的表并不多,但单表的数据量很大、或数据热度很高,这种情况之下就应该选择水平切分,水平切分比垂直切分要复杂一些,它将原本逻辑上属于一体的数据进行了物理分割,除了在分割时要对分割的粒度做好评估,考虑数据平均和负载平均,后期也将对项目人员及应用程序产生额外的数据管理负担。
面对数据递增,解决方案通常是分库分表,冷热数据分离
垂直拆分——主要是字段的拆分
水平拆分——表结构不变,数据分表
4、分库分表包括分库和分表两个部分,在生产中通常包括 :垂直分库、水平分库、垂直分表、水平分表四种方式。
a、垂直分表:
垂直分表定义 :将一个表按照字段分成多表,每个表存储其中一部分字段。
它带来的提升是 :
- 为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响。
- 充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
为什么大字段IO效率低 :
- 由于数据量本身大,需要更长的读取时间;
- 跨页,页是数据库存储单位,很多查找及定位操作都是以页为单位,单页内的数据行越多数据库整体性能越好,而大字段占用空间大,单页内存储行数少,因此IO效率较低。
- 数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少来磁盘IO,从而提升来数据库性能。
一般来说,某业务实体中的各个数据项的访问频次是不一样的,部分数据项可能是占用存储空间比较大的BLOB或是TEXT。例如上例中的商品描述。所以,当表数据量很大时,可以将表按字段切开,将热门字段、冷门字段分开放置在不同库中,这些库可以放在不同的存储设置上,避免IO争抢。垂直切分带来的性能提升主要集中在热门数据的操作效率上,而且磁盘争用情况减少。
通常我们按以下原则进行垂直拆分 :
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 经常组合查询的列放在一张表中;
b.垂直分库
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放不同的服务器上,它的核心理念是专库专用。
它带来的提升是 :
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
垂直分库通过将表按业务分类,然后分库在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
水平分库是把同一个表的数据按一定规则拆分到不同的数据库中,每个库可以放不同的服务器上。
对比 :垂直分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构。
它带来的提升是 :
- 解决来单库大数据,高并发的性能瓶颈。
- 提高来系统的稳定性及可用性。
稳定性体现在IO冲突减少,锁定减少,可用性指某个库出问题,部分可用。
当一个应用难以再细粒度的垂直切分,或切分后数据量行巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
b、水平分表
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
它带来的提升是 :
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
库内的水平分表,解决来单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
5、分库分表的问题
- 分库分表把数据分布在不同库甚至不同服务器,会带来分布式事务问题。
- 垂直分库后表不在一个数据库,甚至不在一台服务器,无法进行关联查询。可将原关联查询分为两次查询,第一次查询的结果集中找出关联数据id,然后根据id发起第二次请求得到关联数据,最后将获得到的数据进行拼装。
- 跨节点多库进行查询时,分页、排序等问题,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序。
- 在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库生成的ID无法保证全局唯一。因此需要单独设计全局主键,比避免跨库主键重复问题。
6、分库分表产生的问题的解决框架
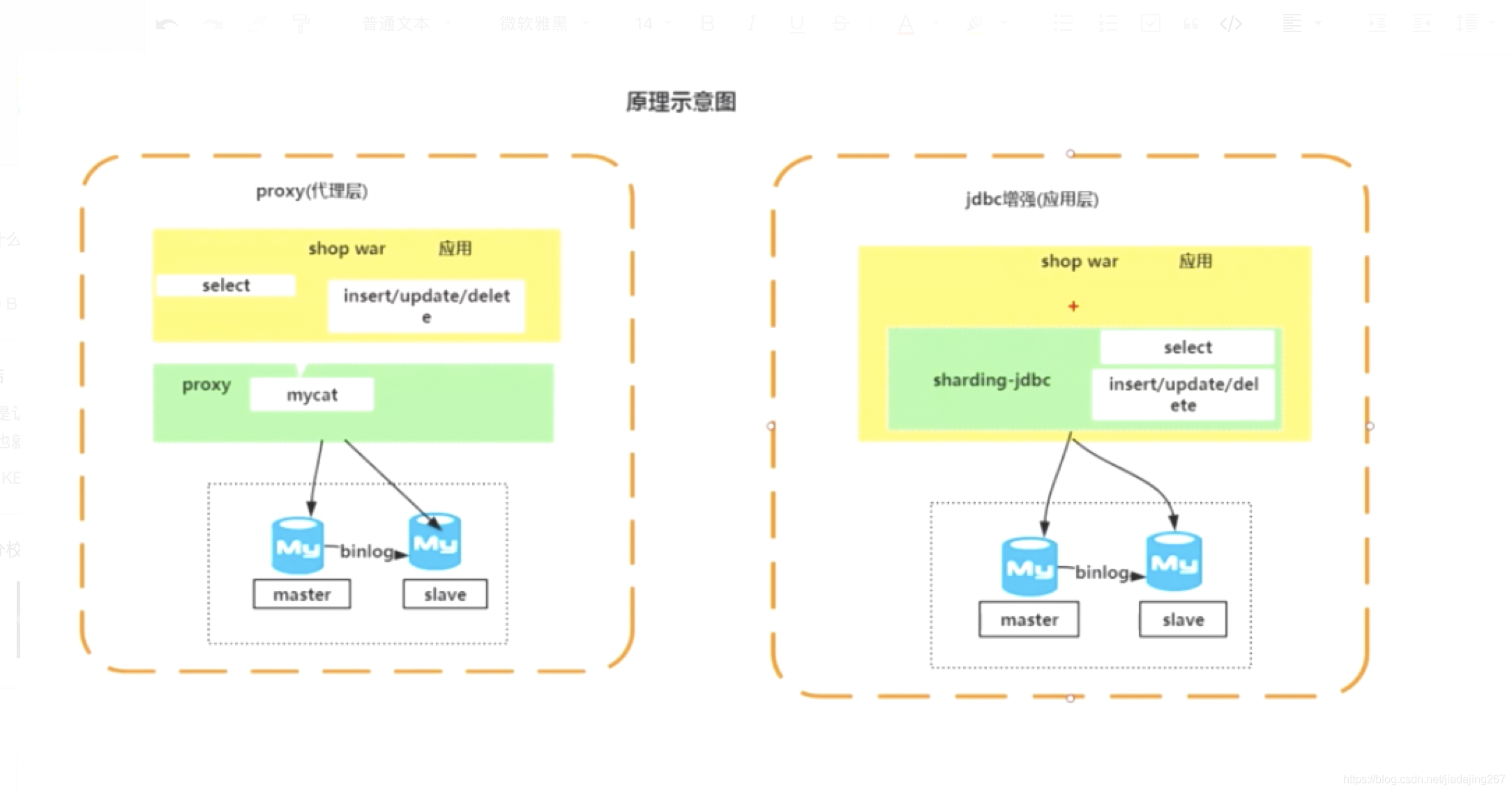
结合两种原理策略,主要说明分别使用上述原理的两个框架mycat和ShardingJdbc的优缺点:
mycat
优点:
1、开发无感知
2、增删节点程序不需要重启
3、跨语言(java 、php)
缺点:
1、性能下降没因为多了一层
2、不支持跨数据库
ShardingJdbc
优点:
1、性能很好的
2、支持跨数据库jdbc
缺点:
1、增加了开发难度
2、不支持跨语言(java)
简单来说
1)mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包
2)使用mycat时不需要改代码,而使用sharding-jdbc时需要修改代码