按照早期的数据库理论,比较流行的数据库模型有三种,分别为层次式数据库,网络式数据库和关系型数据库,而在当今的互联网中,最常用的数据库模型主要是两种,即关系型数据库和非关系型数据库。
1.1关系型数据库介绍
1.关系数据库冲突
虽然网状数据库和层次数据库已经很好的解决了数据集中和共享问题,但是在数据独立性和抽象级别上有很大欠缺,用户在对这两种数据库进行存储时,仍然需要明确数据的存储结构,指出存储路径,而关系型数据库就可以较好的解决这些问题。
2.关系型数据库介绍
关系型数据库模式是把复杂的数据结构归结为简单的二元关系(及即二维表格形式), 例如老男孩教育某一期的学生关系就是一个二元关系,在关系型数据库中,对数据的操作几乎全部建立在一个或多个关系表格上,通过对这些关联的表格分类、合并、连接或选取等运 算来实现数据的管理
3.关系型数据库表格之间的关系举例
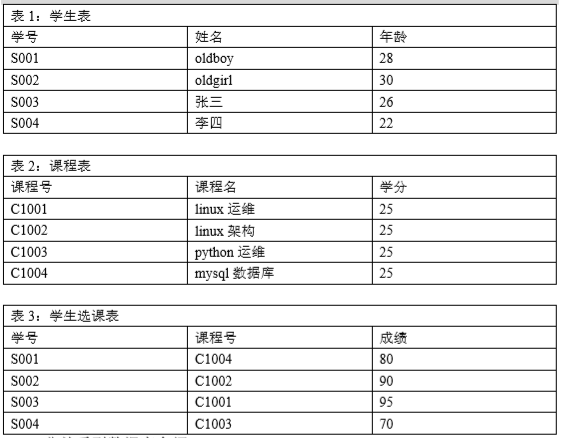
1.2 非关系型数据库介绍
非关系型数据库也被称为 NOSQL 数据库,NOSQL 的本意是 NOT ONLY SQL, 指的是非关系型数据库,NOSQL 是为了高性能,高并发而生的,NOSQL 典型产品 memcached (纯内存),redis(持久化缓存),mongodb。
1.3 非关系型数据库种类
1 键值(key-value)存储数据库
键值数据库就类似传统语言中使用的哈希表,可以通过 key 来添加、查询或者删除数 据,因此使用 key 主键访问,所以会获得很高的性能及扩展性 键值(key-value)数据库主要是使用一个哈希表,这个表中有一个特定的键和一个指 针指向特定的数据,key/value 模型对于 IT 系统来说的优势在与简单、易部署、高并发
典型产品:memcached、redis
2、列存储(column-oriented)数据库
列存储数据将数据存储在列族(column family)中,一个列族存储经常被一起查询的 相关数据,举个例子,如果我们有一个 person 类,我们通常会一起查询他们的姓名和年龄而 不是薪资,这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中 这部分数据库通常是用来应对分布式存储的海量数据,键仍然存在,但是他们的特点是指向了多个列,这些列是由列家族安排的
典型产品:cassandra,hbase
3、面向文档(document-oriented)数据库
文档型数据库的灵感是来自于 lotus notes 办公室软件的,而且它同第一键值存储相类 似,改类型的数据模式是版本化的文档,半结构化的文档以特定的格式存储,比如 JSON。 文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值,而且文档型数据库比键 值数据库的查询效率更高 面向文档数据库会将数据以文档的形式存储,每个文档都是自包含的数据单元,是一 系列数据项的集合,每个数据项都有一个名称与对应的值,值即可以是简单的数据类型,如 字符串、数字和日期等;也可以是复杂的类型。如有序列表和关联对象。数据存储的最小单 位是文档,同一个表中存储的文档属性可以是不同的,数据可以使用 XML,JSON 或者 JSONB 等多种形式存储 典型产品:mongodb、couchdb
4、图形(graph)数据库
图形数据库允许我们将数据以图的方式存储,实体会被称作为顶点,而实体之间的关 系会被作为边。
典型产品:neo4j、infogrid
1.4 关系型数据库产品介绍
1、oracle 数据库
主要应用范围:传统大企业,大公司,政府,金融,证券等等
2、mysql 数据库
主要应用范围:互联网领域,大中型网站,游戏公司,电商平台等等
3、mariadb 数据库
是 mysql 数据库的一个分支
4、SQL server 数据库
是微软公司开发的大型数据库系统,只能运行在 windows 平台下
1.5 常用非关系型数据库产品介绍
1、memcached(key-value)
qmemcached 是一个开源的、高性能的、具有分布式内存对象的缓存系统。通过它可以 减轻数据库负载,加速动态的 web 应用。 缓存一般用来保存一些经常被存取的对象或数据(例如,浏览器会把经常访问的网页 缓存起来一样),通过缓存来存取对象或数据要比在磁盘上存取快很多,前者是内存,后者 是磁盘。memcached 是一种纯内存缓存系统,把经常存取的对象或数据缓存在 memcached 的内存中,这些被缓存的数据被程序通过 API 的方式存取,memcached 里面的数据就像一 张巨大的 HASH 表,数据以 key-value 对的方式存在,memcached 通过缓存经常被存取的对 象或数据,从而减轻频繁读取数据库的压力,提高网站的响应速度,构建出速度更快的可扩 展的 web 应用。官方:http://memcached.org/
2、redis
和 memcached 类似,redis 也是一个 key-value 型存储系统,但 redis 支持的存储 value 类型相对更多,包括 string(字符串)、list(链表)、set(集合)和 zset(有序集合)等,redis 的数据都是缓存在内存中,区别是 redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
3、mongodb(document-oriented)
mongodb 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,类似 json 的 bjson 格式,因 此可以存储比较复杂的数据类型,mongodb 最大的特点是支持的查询语言非常强大,其语法 有点类似面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而 且还支持对数据建立索引,它的特点是高性能、易部署、易使用、存储数据非常方便 主要功能特性:
1、 面向集合存储,易存储类型的数据
2、 模式自由
3、 支持动态查询
4、 支持完全索引,包含内部对象
5、 支持查询
6、 支持复制和故障恢复
7、 使用高效的二进制数据存储,包括大型对象(如视频等)
8、 自动处理碎片,以支持云计算层次的扩展性
9、 支持 RUBY,PYTHON,JAVA,C++,PHP 等多种语言
10、文件存储格式为 BSON(一种 JSON 的扩展)
11、可通过网络访问