正则化(Regularization)
过拟合问题(The problem of overfitting)
欠拟合(underfitting):算法没有很好地拟合训练数据,具有高偏差(high bias)。
过拟合(overfitting):很好的拟合了数据集,具有高方差。变量太多的时候会出现,数据集不足以约束模型。只能针对现有数据集拟合,对新样本就不拟合了。使用过多的特征来拟合预测(假设)函数时,得到的预测函数可能对训练集求得的代价都是非常小的,但是却无法对新的样本进行预测,即泛化能力弱。当变量过多,而训练集很少时,这时往往会出现过拟合问题。不仅在线性回归中会出现,在逻辑回归中也会出现。
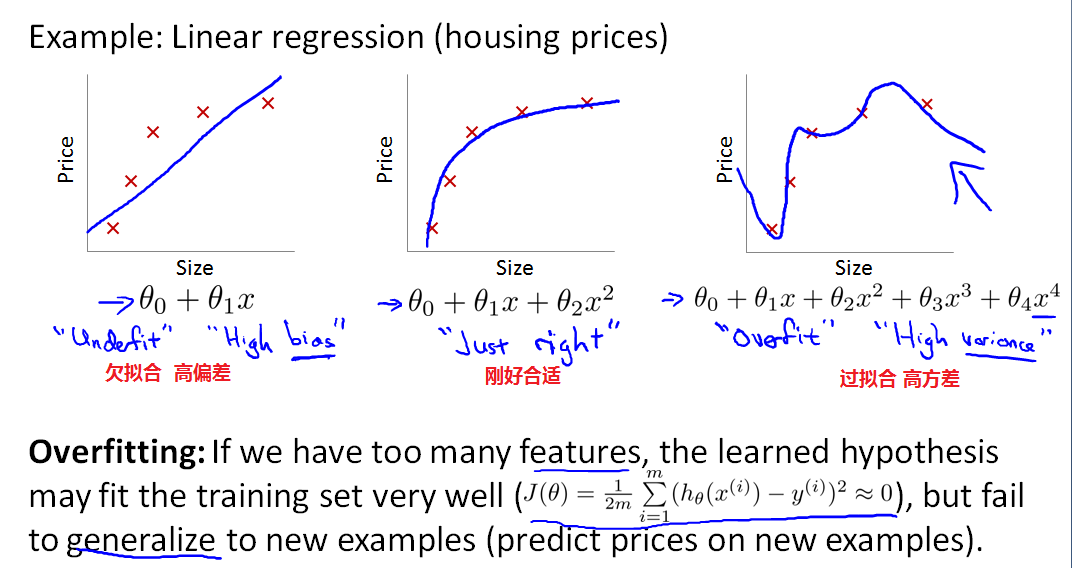
如何避免过拟合?
减少特征变量,正则化

代价函数(Cost Function)
在代价函数中加入正则化项,以前的误差平方起拟合数据的作用,加入的正则化项起调节过拟合的作用,两者间找到一个平衡。为防止出现过度正则化,正则化参数λ的选择必须合适,不能非常大。当惩罚项的λ设置得过大,会导致偏差特别高,此时的theta值除了theta(0)之外几乎接近于0,出现欠拟合现象。

线性回归的正则化( Regularized linear regression)

线性回归之梯度下降法(正则化)

线性回归之正规方程(正则化)

Logistic回归的正则化(Regularization logistic regression)
Logistic回归之梯度下降法(正则化)
与线性回归的相类似,只是假设函数不一样,具体做法请参考上面线性回归之梯度下降法(正则化)
高级算法(正则化)
具体在Octave做法请参考https://www.cnblogs.com/haifengbolgs/p/9325732.html
