paper地址:arxiv.org/pdf/2007.08113.pdf
code地址:https://github.com/vinthony/depth-distillation
1. Contribution
1. 使用预先训练好的网络作为正则化深度蒸馏,同时学习离焦图(defocus map)。
2. 设计一个监督引导的注意块(SAB: Supervision-guided Attention Block),用于对每个侧边输出特征的每一层重新加权。
3. 在每个解码器中设计选择性接收域块(SRFB: Selective Reception Field Block), SRFB能提取更大的感受野,用于构建更丰富的特征金字塔,并使用全局选择注意力去加权重要的特征。
4. 通过将深度估计引入到离焦模糊检测(DBD), 以及设计相关模块(2,3),使提出的方法比其他的方法具有更高的性能。
以上属于个人总结出来的,下面放出了原文。

2. Introduction
离焦模糊,在摄影中也被称为散景效果,在日常照片中得到了广泛的应用。对焦区域强调突出的物体,而失焦模糊可以保护出现在照片中的人的隐私。此外,检测这种模糊也是至关重要的,因为检测到的离焦区域可能在执行任务时有用。这些任务包括自动重对焦[1]、显著目标检测[14]和图像重定位[15]。
传统方法聚焦在设计新颖的手工特征,比如说梯度特征或频率特征。然而,这些方法提取的特征有限,缺乏高层次的语义信息。因此,在场景复杂的情况下,很难通过特定的特征来区分离焦区域。
近年来,基于深度学习的方法在各种计算机视觉任务和离焦模糊检测中表现出了优异的性能。例如Park等[27]训练CNN,对图像中每个局部patch的锐度进行分类。将DBD视为场景分割,提出了更深层次的全卷积方法[45,43,44,34]。虽然这些方法强调了图像尺度在DBD中的重要性,但它们仍然是从二维的角度考虑DBD,并且仅仅依赖于数据集和神经网络的力量。本文从摄影中散焦模糊产生的原因入手。如图1(a)所示,由于相机只拍摄一定深度范围内的清晰照片,所以形成了sharp focus region,也称为depth- offfield (DOF[35])。当光波在成像平面的后方或前方相交时(图1(a)中的红绿线),其产生的区域在最终图像中会变得模糊。由于DBD中的均匀区域通常包含多个目标,且很难被边缘或语义特征检测到,因此摄像机与场景目标之间的距离(深度)为分类提供了较强的先验性。然而,无约束深度估计是一个不适定问题。为了评估现有的DBD数据集,并与之前的方法进行公平的比较,我们提出使用预先训练好的网络[3]作为正则化深度蒸馏,同时学习离焦图。此外,我们设计了一个监督引导的注意块(SAB),用于根据每个水平的侧输出重新加权学习特征。最后,模糊置信度是相对的,这意味着当我们放大一个尖锐的patch时,我们可以认为它是模糊的,反之亦然。虽然以前的方法[43,44,34]已经讨论了多流或跨层融合网络,但我们认为在每个解码器中设计选择性接收域块(SRFB)是一种有效的方法。我们的块提取更大的接收字段来构建更丰富的特征金字塔,并使用全局选择性注意力来加权有用特征的重要性。通过在DBD和所提出的块中加入深度估计,我们的网络在散焦检测方面优于其他方法。如图1 (b)-(i)所示,之前的DBD方法对颜色比较敏感,而在我们的网络中,DBD和深度估计任务是相互建立的,并能很好地预测结果。
3. Methods
我们将DBD定义为一个有监督的基于像素的二分类问题,并以DOF为关注对象。提出方法的算法为:
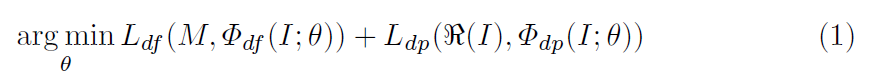
其中,I和M为输入源图像和对应的DOF标签,Φdf(I;Θ)和Φdp
3. 1 Depth Distillation
一般来说,知识蒸馏[9,24]的目的是将知识转移到网络结构优化中。具体来说,如图2(a)所示,除了使用预测的离散硬目标传递知识外,他们在连续软标签(Softmax的输出)空间中使用更大的(教师)网络对紧凑(学生)模型进行正则化。

有趣的是,我们发现DBD(discrete, classification task)和深度估计(continuous, regression task)与知识蒸馏中硬标签和软标签之间的关系相似。在摄影中,锐焦区域(DOF)在数学上被定义上面公式,其中N分别是镜头的f个数,C是模糊圈,f是焦距。深度D是唯一一个不是相机参数。
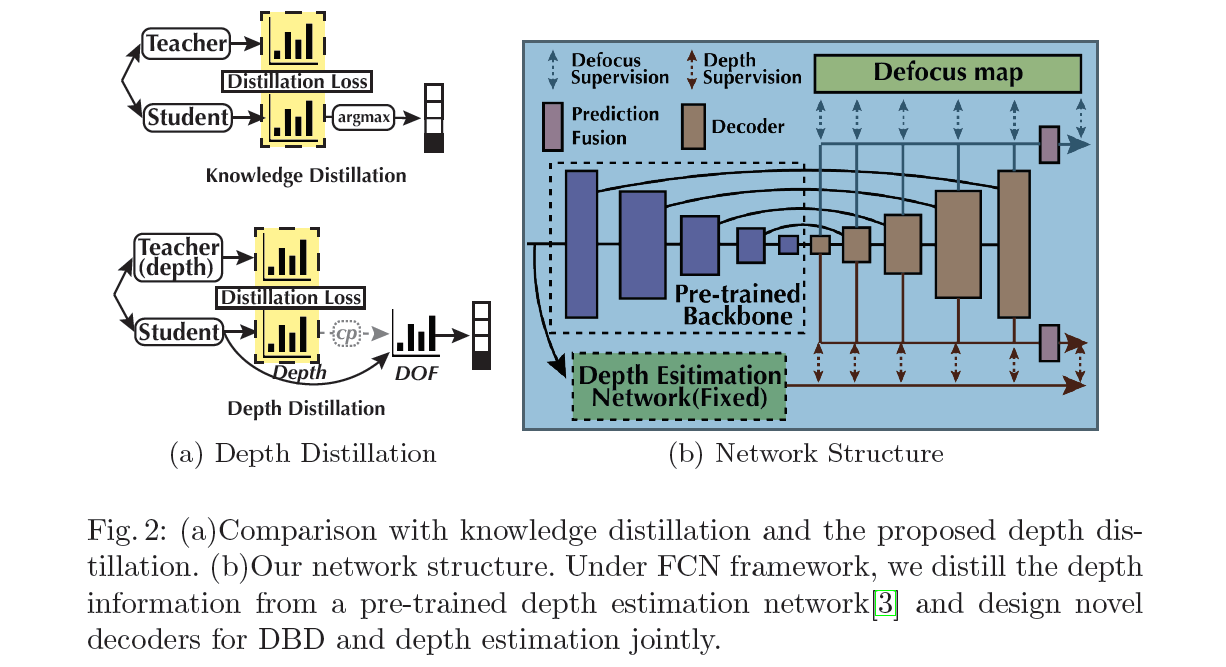
如图2(a)所示,我们提出深度蒸馏来帮助离焦模糊检测。详细地说,我们认为深度是近似软标签,并从预先训练好的网络中提取深度信息作为DBD的正则化。由于相机参数不可用,该网络可以预测离焦和提取深度,而不是直接从深度图计算DOF,再通过知识蒸馏推断离焦。深度蒸馏和知识蒸馏的结构虽然相似,但目标完全不同:我们的目标是将三维信息融入到DBD任务中,而不是从教师网络中提取一个紧凑的模型。为了实现,我们设计了一个简单而有效的框架来实现前面的分析。如图2(b)所示,我们生成多个深度估计输出,这些输出由一个预先训练好的网络监督。然后,通过fusion (1x1 Conv.)块融合所有侧输出以获得最终深度。然而,单幅图像的深度估计是病态的,因为稠密的深度很难采集,尤其是在无约束的情况下。因此,我们选择相对深度网络(Chen et al.[3])作为教师网络。具体来说,它们旨在学习场景对象之间的关系,而不是精确的深度值。因此,他们将800对点之间的空间关系(如点A,点B具有相同的深度,点A比点B更靠近摄像机,点B更靠近摄像机)作为监督标记为前图像。然后,利用大规模训练样本,神经网络可以预测密集相对深度。
像深度蒸馏一样将深度信息利用到DBD有很多好处。首先,深度蒸馏帮助我们的网络更好地理解场景,除了二元分类(类似于知识蒸馏中的关系)。输入的模糊区域也给出了图3所示的解码器的详细结构,其中红色箭头分别表示离焦监督和深度蒸馏。
对相对深度估计的密集提示。最后,通过深度蒸馏,我们在测试中不需要预先训练的深度网络,这也有助于建立一个高效的算法。从相对深度网络中提取也很关键。由于DBD的训练数据集只有600张图像,因此预先训练好的相对深度网络(野外421K训练图像)从更大规模的数据集到我们的网络和任务中包含了更精确的3D特征。此外,我们发现Chen等人的网络能够自动定位突出目标并预测其相对深度。幸运的是,DBD有一个类似的目标,因为摄影师经常使用散焦模糊来强调重要的观点。
3. 2 Network Structure
我们的网络结构是基于全卷积网络(FCN[23])。如图2(b)所示,我们在ImageNet上预先训练的ResNeXt101[38]中,在每个MaxPooling层之前提取多尺度特征(共5层)。这些多尺度特征既包含高层次语义特征,又包含低层细节,以便进一步检测。在每个解码器中,如图3所示,我们使用带有卷积的上采样层代替反卷积层(或转置卷积层),以避免棋盘格伪影[18,26]。然后,在考虑尺度在DBD中的重要性的基础上,从多尺度特征建模和保存的几个方面进行了研究。一方面,我们在解码器的每一级设计辅助分类器,如[10,21,18],以防止过拟合,产生多尺度结果。不同的是,在解码器的每一层,我们分别设计了两个辅助分类器用于DBD和深度蒸馏的监督。每个辅助分类器被定义为一个1x1卷积层用于边预测,我们重用这些边输出作为监督引导的注意块(SAB)用于空间注意(如图3所示)。然后,将所有多尺度的中间输出图合并,以1x1卷积层作为图2(b)中的预测融合块,得到最终的离焦和深度图。另一方面,我们在解码器的每一层对多尺度接收域进行建模,并提出选择性接收域块(Selective reception Field Block, SRFB)来有效地选择和合并多环境下的特征。接下来,我们提供建议区块的细节。
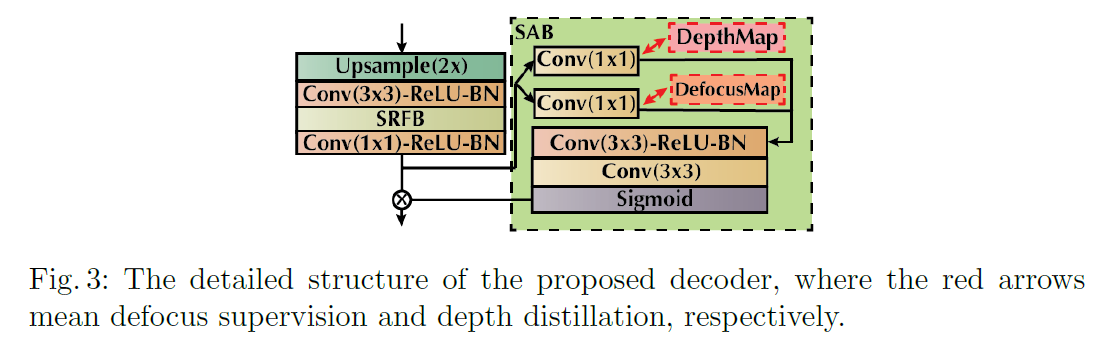
受最近提出的注意机制的启发[11,36],我们利用注意块增加了网络的非线性。具体来说,我们从侧边输出生成注意力地图,因为它也有更强的先验知识,以进一步的特征加权。如图3所示,在监督辅助分类器之后,我们再次将DBD和depth的辅助输出反馈给网络。然后利用两个卷积块和一个Sigmoid函数生成空间注意。最后,我们将原始特征与生成的注意力地图相乘。这些注意事项在下一个解码器之前对特征空间进行重新缩放。
由于DBD需要仔细处理尺度,以往的工作[43,44,34]采用多尺度输入合并多个网络,或递归交叉融合多尺度特征。然而,这些网络仍然是沉重的和计算效率低下。我们没有设计多流网络或跨层融合,而是设计了一个高效的多分支块,用于提取每个解码器中的多个接收域。
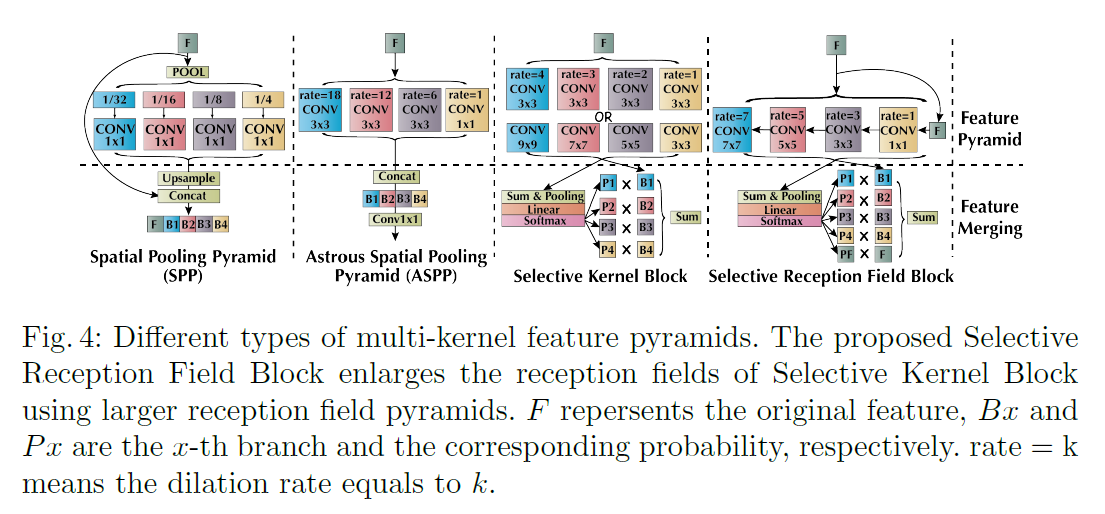
这是使用不同内核大小提取多尺度特征的自然方法。例如,广泛使用的(atrous)空间池金字塔(SPP[42]或ASPP[2])在语义分割和其他相关任务中都取得了成功[41,31]。最近,选择性核网络(SK-Block[19])被提出用于在图像分类中对多个核进行加权。如图4所示,我们发现sk块的作用与(a)SPP类似。因此,我们通过将这些块建模为两个阶段的过程,即特征金字塔和特征合并,给出了一个通用的公式。SPP通过pooling或expanded convolution提取多上下文特征,然后与convolutional block合并。相反,SK-Block使用不同的卷积核(或不同膨胀率的卷积)来模拟多上下文特征。然后,利用全局注意力生成每个分支的概率,并利用该概率对每个核进行加权。
但是,如果直接插入sk块到FCN中,接收域仍然是局部的,扩大接收域需要更多的内存。因此,受(A)SPP的启发,我们设计了选择性接收字段块,对sk块进行了以下改进:首先,我们将原始特征添加到特征金字塔中并进行合并。通过引入原始特征,其他分支将尝试学习输入的残差。另一方面,我们的目标是在特征金字塔中创造更丰富、更大的接受域。具体来说,我们使用了一系列卷积层,卷积层的扩张和卷积核一起作为特征金字塔,这是受到了接收域块(RFB)[22]的启发。注意,RFB被提议作为一种类似刺激的结构用于对象检测。相比之下,我们建立了特征金字塔,这是受到他们的意图的启发,并使用这些块作为FCN框架中的解码器。因此,我们大幅度地扩大了SK-Block的接收域,该接收域包含多尺度的加权和选择功能。例如,当块中有4个支路时(如图4所示),sk块的接收场为11(9×9或3×3扩张=4),而我们的接收场为43(7×7扩张=7)。
4. Loss Function

Ldefocus:前一项计算的是最后输出的defocus map(Mf)与ground truth defocus map(M)之间的损失,后一项计算的是decoder的每一层输出M'k与ground truth defocus map(M)之间的损失。
Ldepth:前一项计算的是最后输出的depth map(Φd)与ground truth defocus map(Φrd)之间的损失,后一项计算的是decoder的每一层输出(Φkd)与ground truth defocus map(Φrd)之间的损失。
5. Experiments
我们比较我们的算法和一些先进的方法,包括基于深度学习DBD的方法,如:深和手工制作的特性为基础方法(DHCF [27]), multi-stream bottom-top-bottom (BTB-F [43], BTB-C[44]),网络cross-ensemble (CENet[45])循环和网络功能重用和融合(DFNet[34])。此外,我们还进行了最先进的基于手工特征的方法的实验,包括局部二值模式(LBP[40])和梯度大小的高频多尺度融合和排序变换(HiFST[8])。请注意,所有DBD的预测映射都来自作者的网站或公共实现,推荐使用超参数进行比较。由于很少有基于学习的DBD方法,我们还将我们的方法与4个最先进的基于学习的方法进行了比较。用双向特征金字塔循环注意网络(BDRAR[47])和方向意识注意网络(DSC[13])进行阴影检测,边界意识缺失网络(BAS[30])和级联部分解码器(CPD[37])进行显著目标检测。所有相关任务的网络在我们的框架上训练,输入分辨率和批处理大小相同。
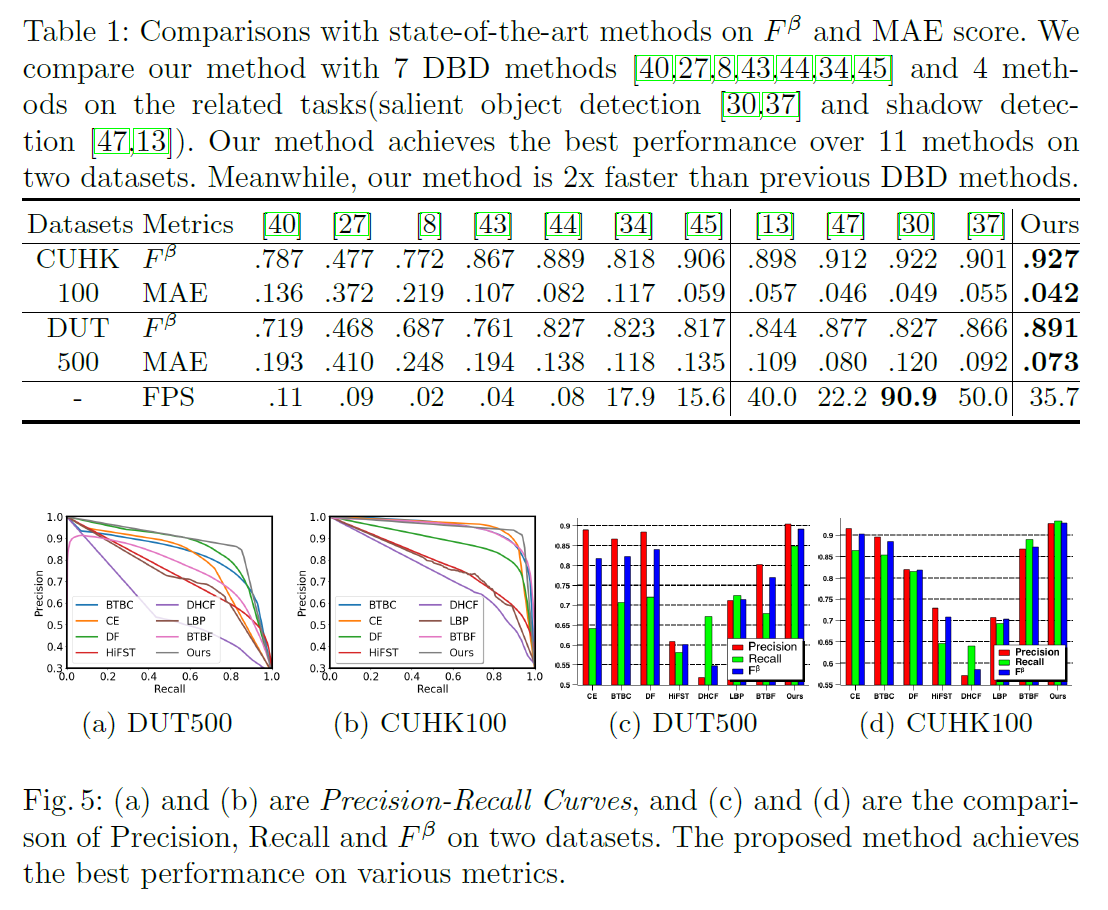
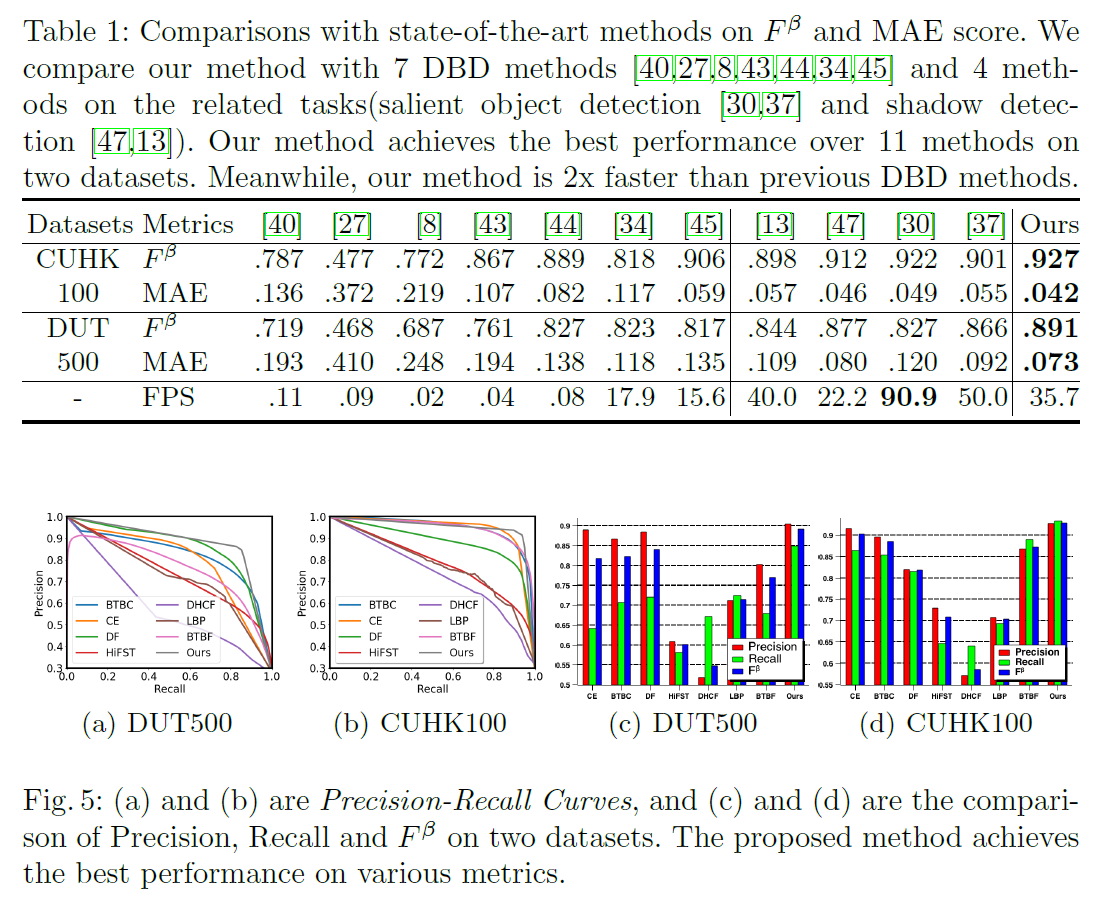
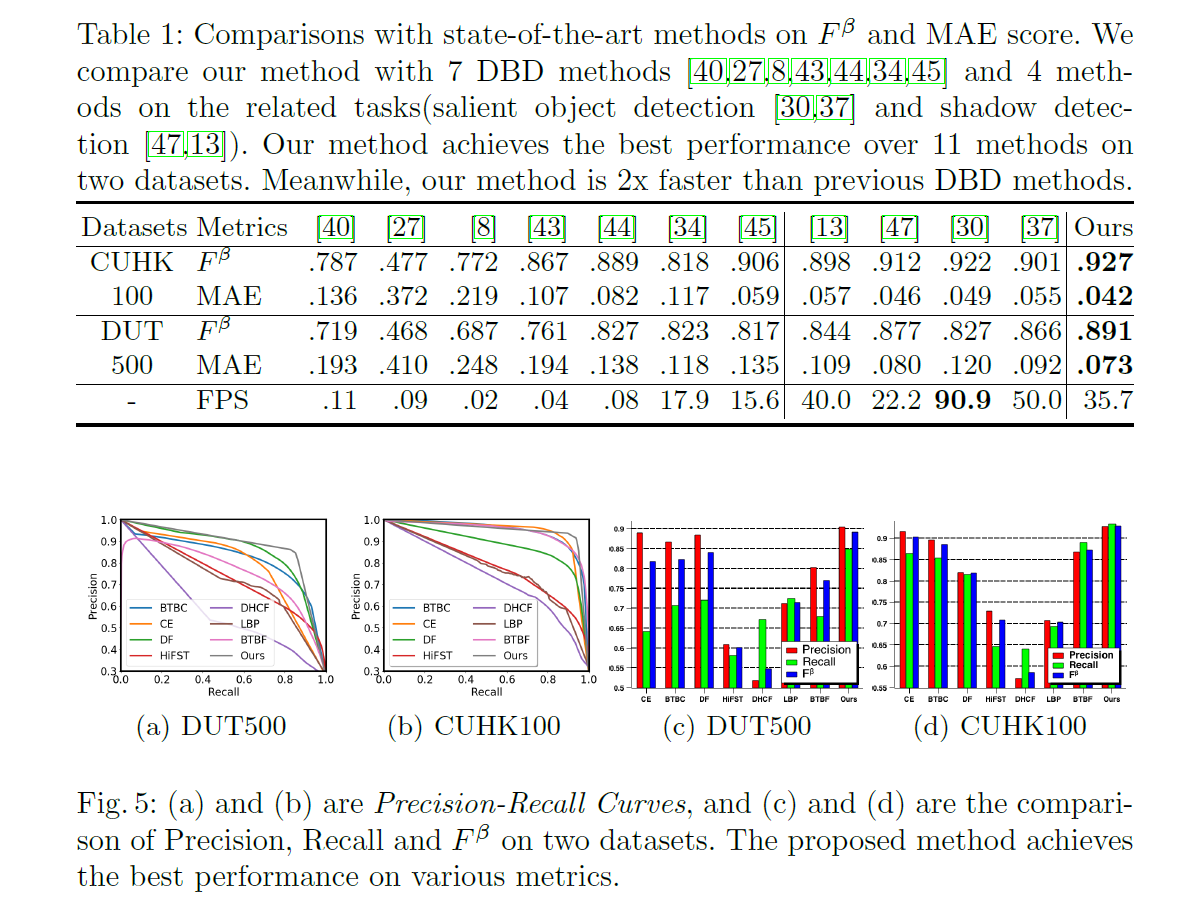
我们在表1和图5两个公开数据集上说明了我们的方法和最新方法的数值比较。很明显,我们的方法在所有数值指标上都优于其他方法,有更大的边际。结果表明,该网络具有深度和多尺度特征,能较好地理解复杂场景。我们还给出了一些可视化示例,以与图6中最新的DBD方法进行比较。我们的方法也显示了优越的视觉质量。我们的网络除了具有良好的目标识别能力外,由于深度蒸馏的作用,还可以很好地预测均匀区域(如第四例中的平面)。为了与相关任务进行比较,表1也给出了清晰的结果。我们的网络在DBD上比边界感知网络BASNet[30]或方向感知网络[13]有更好的性能,因为深度在我们的任务中更为重要。例如,BASNet[30]中的边界损失在CUHK100上是有利的(如表1),但DUT500的情况更糟,因为DUT500中的均匀区域与边缘无关。如图7所示,我们的方法比其他方法的效果要好得多。

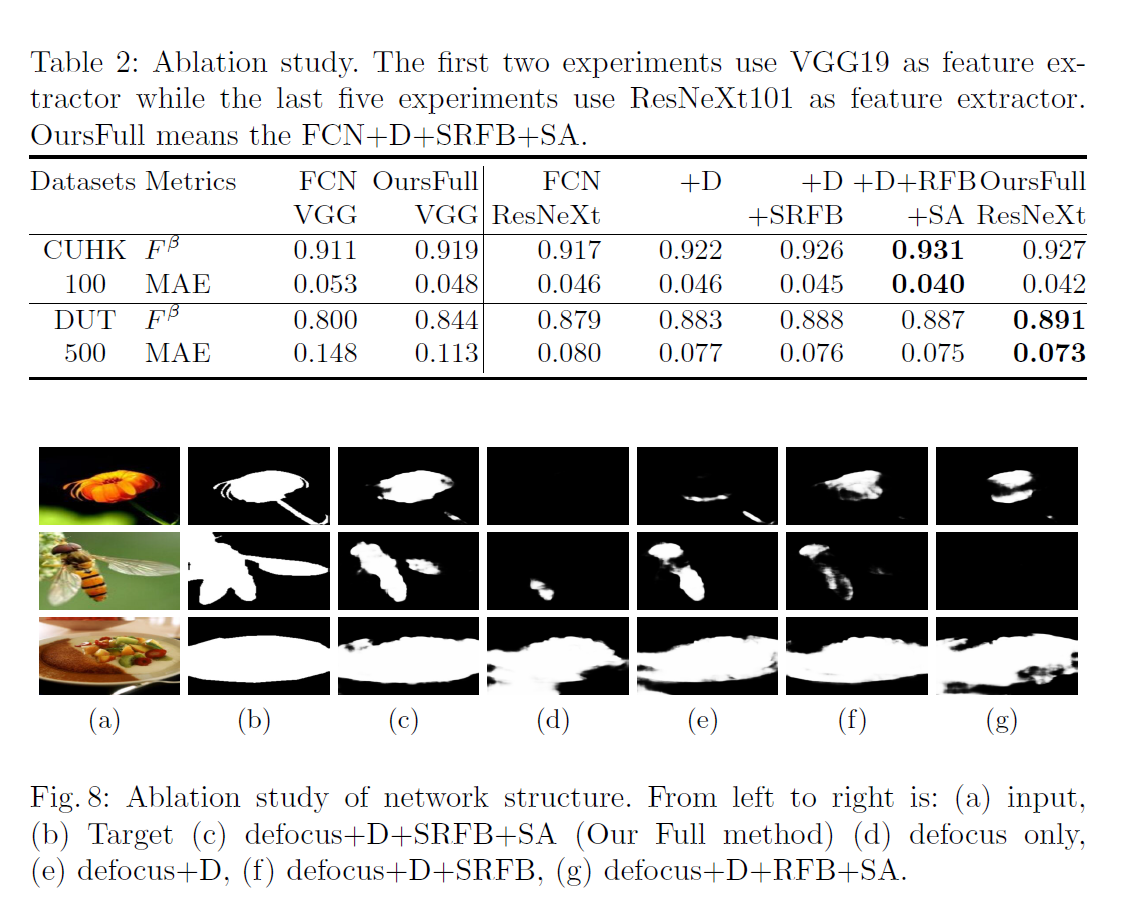
对于我们的网络结构,我们选择了不同的主干网,尤其是在之前的工作和ResNeXt101中广泛使用的VGG19。对于消融研究,我们使用带有辅助输出的FCN[23]和ResNeXt101作为特征提取器,并与表2中我们的主要贡献进行比较。因为CUHK100数据集很小而且很简单,所以这个数据集上的度量差异不是太大。而在DUT500数据集上,ResNeXt101可以提取更丰富的特征,得到更好的结果。与目前最新的DBD方法(7种DBD方法[40,27,8,43,44,34,45]见表1,图8:网络结构的消融研究。从左到右是:(a)输入,(b)目标(c)离焦+D+SRFB+SA(我们的全方法)(D)仅离焦,(e)离焦+D+SRFB, (f)离焦+D+SRFB, (g)离焦+D+RFB+SA。
6. Conclusion
在图8(d)(e)和表2中测试了DBD深度蒸馏的有效性。很明显,在深度的帮助下,我们的网络可以很好地理解场景,并获得更好的结果,因为深度信息为离焦地图检测提供了很强的先验。使用深度蒸馏,我们的网络还可以从单个图像中预测相对深度。虽然它不是我们的主要目标,我们的网络只能预测部分离焦图像的深度,但我们仍然将蒸馏后的深度与补充材料中我们的教师网络(Chen et al.[3])进行比较。