1.什么是状态码301
301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
比如,我们访问 http://www.baidu.com 会跳转到 https://www.baidu.com,发送请求之后,就会返回301状态码,然后返回一个location,提示新的地址,浏览器就会拿着这个新的地址去访问。
注意: 301请求是可以缓存的, 即通过看status code,可以发现后面写着from cache。
或者你把你的网页的名称从php修改为了html,这个过程中,也会发生永久重定向。
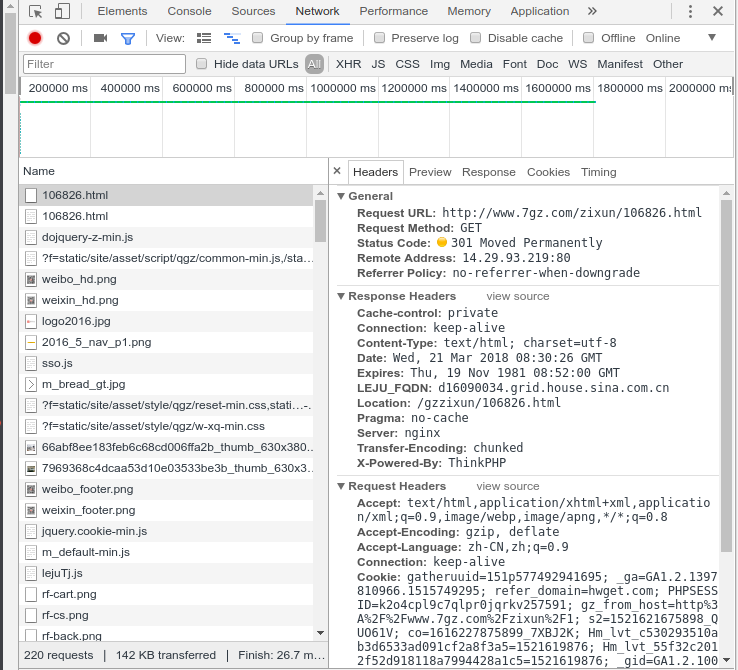
2.如何处理
首先我们可以使用scrapy框架中的 scrapy shell 进行测试
跳转前后的url如果是一致的,我们在终端命令行输入 :
scrapy shell http://www.7gz.com/gzzixun/106826.html
观察到log中信息包含:
[scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.7gz.com/gzzixun/106826.html> (referer: None)
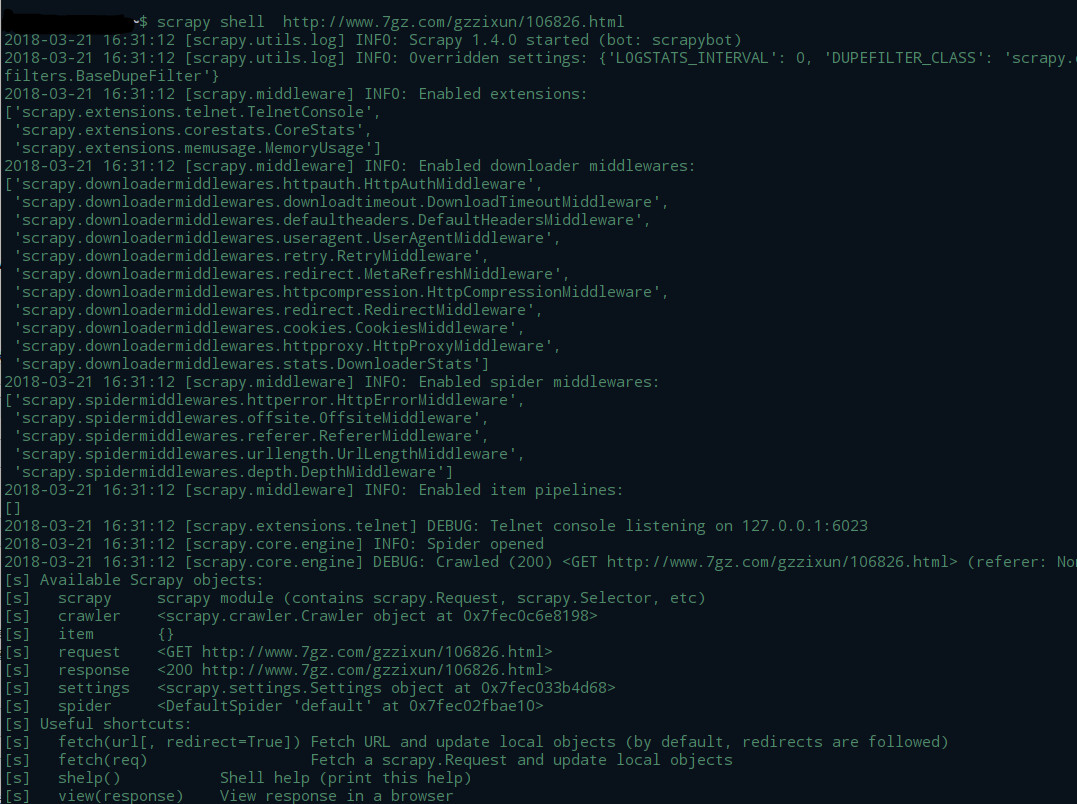
说明我们可以正常访问这个网址,只是跳转网址未改变,状态码是301。
这个时候我们需要在scrapy框架中的 settings.py 文件里添加
HTTPERROR_ALLOWED_CODES = [301]
这样再运行就不会产生301的log信息了,爬虫可以正常运行。