Flume是Cloudera提供的一个高可用的、高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地。这里的日志是一个统称,泛指文件、操作记录等许多数据。
1、数据流模型
Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume传输的数据的基本单位是Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。Event从Source,流向Channel,再到Sink,本身为一个byte数组,并可携带headers信息。Event代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
2、核心组件
Flume运行的核心是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是source、channel、sink。通过这些组件,Event可以从一个地方流向另一个地方,如图1-1所示,也可以多级agent任一链接组合,如图1-2所示。
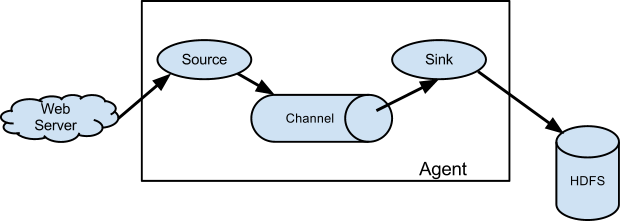
图1-1 flume数据流模型
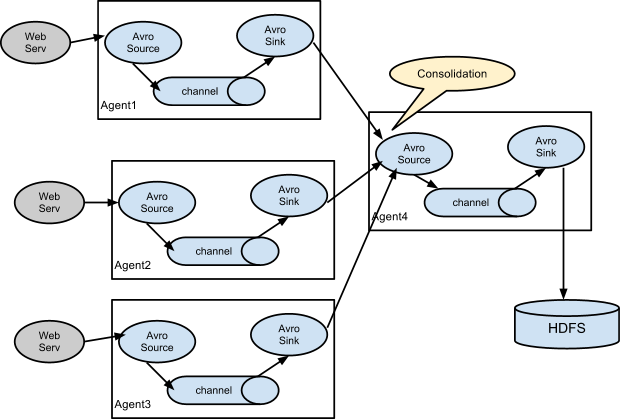
图1-2 多级agent连接模型
1) Source:专用于收集日志,可以处理各种类型各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义等。
▶ Exec Source:以运行 Linux 命令的方式,持续的输出最新的数据,如 tail -F 文件名 指令,在这种方式下,取的文件名必须是指定的。 ExecSource 可以实现对日志的实时收集,但是存在Flume不运行或者指令执行出错时,将无法收集到日志数据,无法保证日志数据的完整性;
▶ Spool Source:监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:拷贝到 spool 目录下的文件不可以再打开编辑;spool 目录下不可包含相应的子目录;
2) Channel:专用于临时存储数据,可以存放在memory、jdbc、file、自定义等。其存储的数据只有在sink发送成功之后才会被删除。
▶ Memory Channel:可以实现高速的吞吐,但是无法保证数据的完整性。Memory Channel 是一个不稳定的隧道,其原因是由于它在内存中存储所有事件。如果 java 进程死掉,任何存储在内存的事件将会丢失。另外,内存的空间也受到RAM大小的限制,与File Channel有差别;
▶ File Channel:保证数据的完整性与一致性。在具体配置FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。File Channel是一个持久化的隧道(channel),它持久化所有的事件,并将其存储到磁盘中。因此,即使 Java 虚拟机当掉,或者操作系统崩溃或重启,再或者事件没有在管道中成功地传递到下一个代理(agent),这一切都不会造成数据丢失。
3) Sink:专用于把数据发送到目的地件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义等。
3、可靠性
Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume使用事务性的方式保证传送Event整个过程的可靠性。Sink必须在Event被存入Channel 后,或者已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把Event从Channel中remove掉。这样数据流里的event无论是在一个agent里还是多个agent之间流转,都能保证可靠,因为以上的事务保证了event会被成功存储起来。而Channel的多种实现在可恢复性上有不同的保证。也保证了event不同程度的可靠性。比如Flume支持在本地保存一份文件channel作为备份,而memory channel将event存在内存queue里,速度快,但丢失的话无法恢复。
1、安装
官网(http://flume.apache.org/download.html)下载flume版本(本实验:apache-flume-1.5.2-bin.tar.gz),解压到/usr/local目录下,进入flume-xx/conf目录中,执行命令:mv flume-env.sh.properties flume-env.sh,然后配置flume-env.sh中的JAVA_HOME路径。
2、一个示例
本示例Source来自Spooling Directory,Sink流向HDFS。监控/root/logs文件目录下的文件,一旦有新文件,就立刻将文件内容通过agent流向HDFS的hdfs://cluster1/flume/%Y%m%d文件中(此处如果找不到cluster1,需要将hadoop的配置文件core-site.xml和hdfs-site.xml拷贝至flume的conf目录中)。
flume目录下新建test目录,新建文件example,内容如下:


#定义agent名, source、channel、sink的名称
agent1.sources = source1
agent1.channels = channel1
agent1.sinks = sink1
#具体定义source
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/logs
agent1.sources.source1.fileHeader = false
#定义拦截器,为消息添加时间戳
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#具体定义channel
#也可以将channel数据放在内存(但是内存容易丢失)中,如
#agent1.channels.c1.type = memory
#agent1.channels.c1.capacity = 10000
#agent1.channels.c1.transactionCapacity = 100
#此处配置为文件中
agent1.channels.channel1.type=file
#备份路径
agent1.channels.channel1.checkpointDir=/root/flume_bak
#数据保存路径
agent1.channels.channel1.dataDirs=/root/flume_tmp
#具体定义sink
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://cluster1/flume/%Y%m%d
agent1.sinks.sink1.hdfs.fileType = DataStream
#存储到HDFS文件名的前缀,格式为20140116-文件名..
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
#不按照条数生成文件
agent1.sinks.sink1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
agent1.sinks.sink1.hdfs.rollSize = 134217728
#HDFS上的文件每60秒去检测
agent1.sinks.sink1.hdfs.rollInterval = 60
#组装source、channel、sink
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
运行该示例,进入/usr/local/flume目录,执行命令:bin/flume-ng agent -n agent1 -c conf -f test/example -Dflume.root.logger=DEBUG,console
其中-n指定agent名称,-c指定配置文件目录,-f指定配置文件,-Dflume.root.logger=DEBUG,console设置日志等级为输出到控制台。