1,动态数据加载的处理
- 图片懒加载概念:
- 图片懒加载是一种页面优化技术.图片作为一种网络资源,在被请求时也与静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面首屏加载时间,为了解决这些问题,通过前后端配合,是图片仅在浏览器当前窗口出现时才加载给图片,达到减少首屏图片请求数的技术叫做"图片懒加载"
- 网站一般如何实现图片懒记载技术?
- 在网页源码中,img标签中 首先会使用一个"伪属性"(通常使用src2,original......)去存放真正的图片连接,而并非是直接存放在src属性中,当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的记载
2,selenium
- 什么是selenium:是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作
- 环境搭建:
- 安装selenium: pip install selenium
- 获取某一款浏览器的驱动程序(以谷歌浏览器为例)
- 谷歌浏览器下载驱动地址: http://chromedriver.storage.googleapis.com/index.html
- 下载驱动程序必须和浏览器的版本统一,大家可以根据以下版本对照下载:
- http://blog.csdn.net/huilan_same/article/details/51896672
- 效果展示:
from selenium import webdriver
from time import sleep
# 后面是你的浏览器驱动位置,记得前面加r'','r'是防止字符转义的
driver = webdriver.Chrome(r'驱动程序路径')
# 用get打开百度页面
driver.get("http://www.baidu.com")
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text('设置')[0].click()
sleep(2)
# # 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text('搜索设置')[0].click()
sleep(2)
# 选中每页显示50条
m = driver.find_element_by_id('nr')
sleep(2)
m.find_element_by_xpath('//*[@id="nr"]/option[3]').click()
m.find_element_by_xpath('.//option[3]').click()
sleep(2)
# 点击保存设置
driver.find_elements_by_class_name("prefpanelgo")[0].click()
sleep(2)
# 处理弹出的警告页面 确定accept() 和 取消dismiss()
driver.switch_to_alert().accept()
sleep(2)
# 找到百度的输入框,并输入 美女
driver.find_element_by_id('kw').send_keys('美女')
sleep(2)
# 点击搜索按钮
driver.find_element_by_id('su').click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text('美女_百度图片')[0].click()
sleep(3)
# 关闭浏览器
driver.quit()
代码详解:
- 导包: from selenium import webdriver
- 创建浏览器对象,通过该浏览器对象可以操作浏览器:browser = webdriver.Chrome("驱动路径")
- 使用浏览器发起指定请求
- browser.get(url)
- 使用下面方法,查找指定的元素进行操作
- find_element_by_id 根据id中节点
- find_elements_by_name 根据name找
- find_elements_by_xpath 根据xpath查找
- find_elements_by_yag_name 根据标签名查找
- find_elements_by_calss_name 根据class名字查找
3,phantomJS
- phantomJS是一款无界面的浏览器,其自动化操作流程和上述操作胡歌浏览器是一致的,有于是无界面的,为了能够展示自动化操作流程,phantomJS为用户提供了一个截屏功能,使用save_screenshot实现
from selenium import webdriver
import time
bro = webdriver.PhantomJS(executable_path="D:PhantomJSphantomjs-2.1.1-windowsinphantomjs.exe")
# 请求的发送
bro.get(url="https://www.baidu.com")
# 截图
bro.save_screenshot("./1.jpg")
# 根据find系列的函数定位到指定的标签
my_input = bro.find_element_by_id("kw")
# 向标签中录入指定的标签
my_input = bro.send_keys("美女")
# 知道百度一下的按钮
my_button = bro.find_element_by_id("su")
my_button.click()
# 获取浏览器当前的页面源码
page_text = bro.page_source
bro.save_screenshot("./2.png") # 截图
print(page_text)
bro.quit()
from selenium import webdriver
import time
# 伪装一个谷歌浏览器(实例化一个谷歌浏览器的对象)
bro = webdriver.Chrome(executable_path=r"D:chromechromedriver.exe")
# 发送的请求
bro.get(url="https://www.baidu.com")
time.sleep(3)
# 根据find系列的函数定位到指定的标签(这个是输入框的标签)
my_input = bro.find_element_by_id("kw")
# 向标签中录入指定的数据
my_input.send_keys("美女")
time.sleep(3)
# 获取到点击按钮(百度一下)
my_button = bro.find_element_by_id("su")
# 点击搜索
my_button.click()
time.sleep(3)
# 获取到当前浏览器显示的页面的页面源码
page_text = bro.page_source
print(page_text)
# 退出
bro.quit()
qq空间登录的代码:
from lxml import etree
bro = webdriver.Chrome(executable_path=r"D:chromechromedriver.exe")
url = "https://qzone.qq.com/"
# 请求的发送
bro.get(url=url)
time.sleep(1)
# 定位到指定的iframe
bro.switch_to.frame("login_frame")
# 找到账号密码登录的标签
bro.find_element_by_id("switcher_plogin").click()
time.sleep(1)
# 找到登录的按钮,并点击登录
# 找到用户名的输入框并输入账号
username = bro.find_element_by_id("u")
username.send_keys("937371049")
# 找到密码并输入
password = bro.find_element_by_id("p")
password.send_keys("13633233754")
# 找到登录按钮点击登录
bro.find_element_by_id("login_button").click()
time.sleep(1)
# 找到js代码,滚轮 向下滚动
js = "window.scrollTo(0, document.body.scrollHeight)"
# 滚轮开始滚动
bro.execute_script(js)
time.sleep(2)
bro.execute_script(js)
time.sleep(2)
bro.execute_script(js)
time.sleep(2)
bro.execute_script(js)
time.sleep(2)
page_text = bro.page_source
time.sleep(3)
# 解析:
# 把 获取到的数据转化成html的格式
tree = etree.HTML(page_text)
div_list = tree.xpath('//div[@class="f-info qz_info_cut"] | //div[@class="f-info"]')
for div in div_list:
text = div.xpath('.//text()')
text = "".join(text)
print(text)
bro.quit()
4,谷歌 无头浏览器
- 由于phantomJS最近已经停止了更新和维护,所以大家使用谷歌无头浏览器
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
# 谷歌无头浏览器
bro = webdriver.Chrome(executable_path=r"D:chromechromedriver.exe", chrome_options=chrome_options)
# 请求的发送
bro.get(url="https://www.baidu.com")
# 根据find系列的函数定位到指定的标签
my_input = bro.find_element_by_id("kw")
# 向标签中录入指定的元素
my_input.send_keys("美女")
my_button = bro.find_element_by_id("su")
# 点击百度
my_button.click()
# 获取当前浏览器显示的页面的页面源码
page_text = bro.page_source
print(page_text)
bro.quit()
5,UA池 和代理池
- 咱们先去官网把scrapy框架的图拿出来see,see
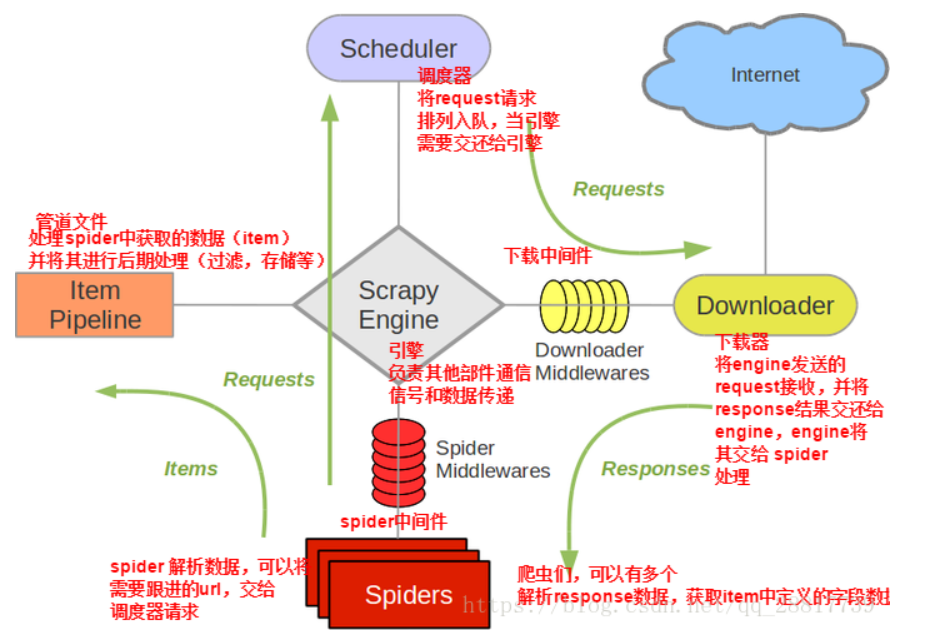
- 下载中间件(Downloader Middlewares)位于引擎和下载器之间的一层组件
- 作用:
- 引擎将请求传递给下载器过程中,下载中间件可以对请求进行一系列处理,比如设置请求的User-Agent,设置代理等
- 在下载器完成将Response传递给引擎中,下载中间件可以对响应进行一系列处理,比如进行gzip解压等
- 我们主要使用下载中间件处理请求,一般会对请求,设置随机的User-Agent,设置随机的代理,目的在于防止爬取网站的反爬虫策略.
UA池:User-Agent池
- 应用:尽可能多的将scrapy工程中的请求伪装成不同类型额度浏览器身份
- 操作流程:
- 在下载中间中拦截请求
- 在拦截到的请求的请求头信息中的UA进行篡改伪装
- 在配置文找中开启下载中间件
- 代码展示:
from scrapy import signals
import random
class CrawlproSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class CrawlproDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
proxy_http = [
"http://113.128.10.121", "http://49.86.181.235", "http://121.225.52.143", "http://180.118.134.29",
"http://111.177.186.27", "http://175.155.77.189", "http://110.52.235.120", "http://113.128.24.189",
]
proxy_https = [
"https://93.190.143.59", "https://106.104.168.15", "https://167.249.181.237", "https://124.250.70.76",
"https://119.101.115.2", "https://58.55.133.48", "https://49.86.177.193", "https://58.55.132.231",
"https://58.55.133.77", "https://119.101.117.189", "https://27.54.248.42", "https://221.239.86.26",
]
# 拦截请求:request参数就是拦截到的请求
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
print("中间件开始下载", request)
if request.url.split(":")[0] == "http":
request.meta["proxy"] = random.choice(self.proxy_http)
else:
request.meta["proxy"] = random.choice(self.proxy_https)
request.header["User-Agent"] = random.choice(self.user_agent_list)
print(request.meta["proxy"], request.heaser["User-Agent"])
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
代理池
- 作用尽可能多的将scrapy工程中的请求的IP设置成不同的
- 操作流程:
- 在下载中间件中拦截请求
- 将拦截到的请求的IP修改成某一代理IP
- 在配置文件中开启下载中间件
- 代码展示:上边代码里有,参考上边代码即可.