首先,先了解一下数据库的基本概念要点:
数据库是数据存储的集合,表示数据结构化的信息
列存储表中的信息
行存储表的明细
主键是表中的唯一标识
主键不具备业务意义
在实际操作中,对表的主键不做强制性要求,但是建议设立
主键必须唯一
每行必须有一个主键,不可为空
主键的值不可被修改
主键值被删除后不可重用
表A的主键,可以作为表B的字段,此时不受约束
数据库的基本类型(最基础的):char--文本 int--整数 float--小数点 date--到日的日期 timestamp--精确到秒或者毫秒
数据库的实际操作:
MySQL的安装略,直接按照网上教学视频逐步安装即可。(这里面写到几个本人安装踩到的比较低级的坑,对我一个嘎嘎新的小新手来说是坑,就是在装win7的本的时候一次完成,基本没什么,在装台式机的win10的时候,第一次装的时候没有workbench,重装之后发现依然部分报错,原因是没有将原有文件删除干净,再后来装的时候,仔细看了一下每一步,确定有workbench的时候,就正常装好了。)接下来打开workbench进行操作。

点击新建数据库

创建一个表,对表进行命名,建议养成好的习惯在注释的地方进行备注,以便日后表多的时候或者别人使用的时候更好的了解内容。
数据编码先择UTF8形式的
将需要的字段输入进区,并调整字段的值类型,可设置主键。
再将表格导入数据库表内(建议.csv格式的,前面提到过为什么,因为Excel本身会有很多形式)
此时在导入数据的时候有2中方法:
1.用workbench界面直接导入,有点是交互性强易掌握,缺点是速度会慢需要等待。
2.直接写代码的形式,有点是运行很快,缺点是代码需要自己一点点写进去。(在数据量较大多行的情况下,建议直接用代码形式加载)
【注意】加载数据是别的编码例如jbk形式的,导入进去的时候就会出现乱码的情况,当数据库选择的是UTF8的时候,导入的数据也应是utf8才可。
解决方式:将Excel另存为utf8形式的.csv文件导入即可。
导入的过程中会直接把表头导入进去,直接选择删除行即可。
需要注意的是:
有的时候文本过长~长出了文本限定的45,这时候将需要进行修改将45变大,否则会报错。
导入后检查无误建表保存。
【MySQL语句】
1.核心:select查询语句
select*form data.表名称
*为通配符,代表全部
2.limit 100 限制搜索100条数据,查找100行
执行两条sql语句的话,结束时用“;”进行结束
点击保存,可将查找出来的数据进行导出生成。
3.order by 字段 desc
将字段进行升序排列
加desc为降序排列
4.过滤功能where命令
where 字段=过滤字段
逻辑关系符号“=”“>”"<"
between 数值 and 数值:在两个数值之间
in(“字段”,“字段”)特定的条件筛选两个字段的内容
“!=”不等于
“<>”不等于
not in (“字段”,“字段”)过滤掉两个字段的内容
多条件查找 加and 链接 and 字段=“”
or 或者
多重嵌套
where city=“上海”
and education=“本科”
or work=“1-3年”
【注意】条件顺序
where city=“上海”
and (eudcation="本科"
or work =“1-3年”)
执行逻辑为()内进行优先进行
模糊查找
where
字段 like “%模糊词%”:过滤包含模糊次的
%模糊词:以模糊词结尾的
模糊词%:以模糊词开头的
进行分组
group by 字段
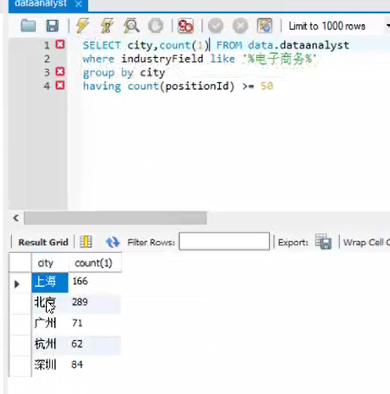
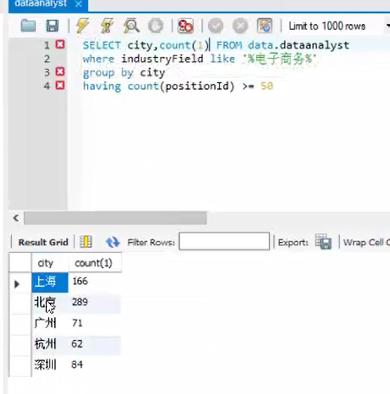
【实例应用】
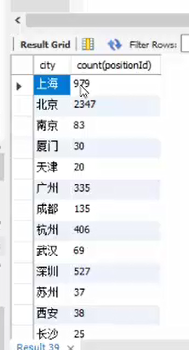
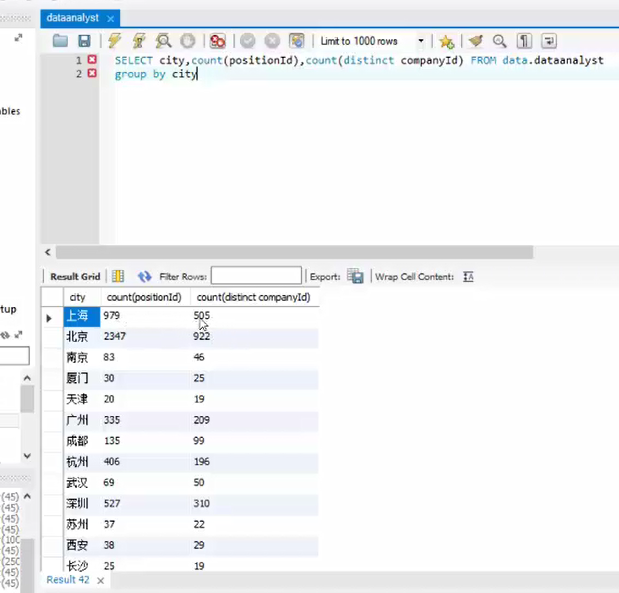
select 城市 ,count(城市ID)form data.表名
group by 城市
运行后:城市分组对应的城市ID进行计数的数量和
distinct去重

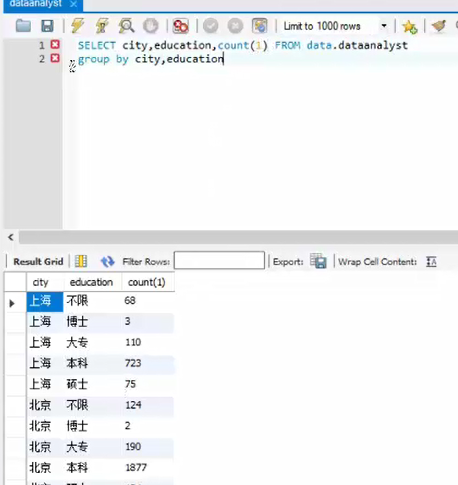
【group by 分组的高级用法】
having单纯针对分组的过滤
添加占比
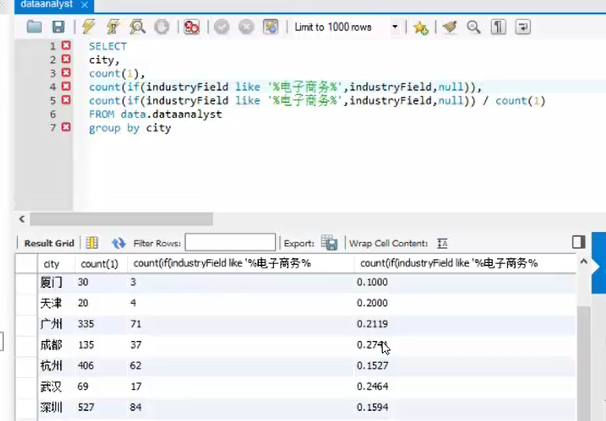
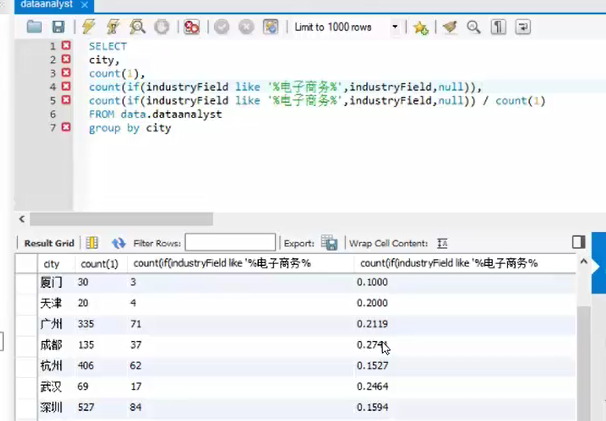
as 字段别名化将过长复杂的代码进行替代
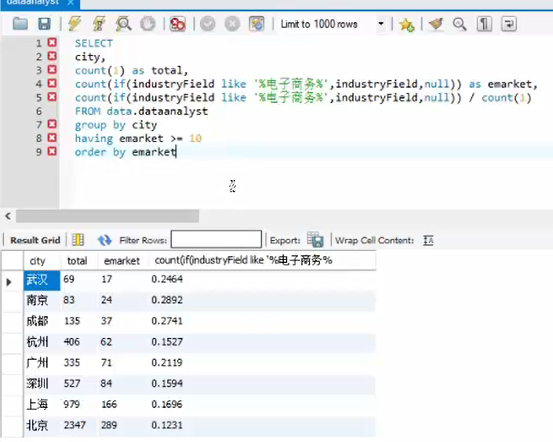
结果是一样的,但是,不能用于逻辑出发的运算,因为不能识别,不能直接用于select,但是可以在where,group by 的层面进行使用
【函数】
1.拆分技巧
left与Excel基本一致
locate()与Excel里面的find一样


写嵌套的时候,建议一步一步写,分步骤走
支持中间截取函数substr
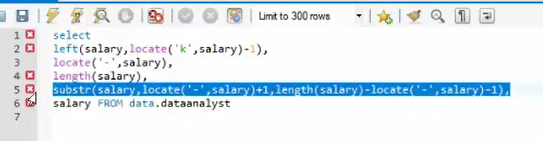
效果等同于上面求出薪资的上线和下线,但是“8K以上”这样的数据就无法进行处理。
子查询
上案例可视为一个tab进行查询
可以进行嵌套,给表添加别名
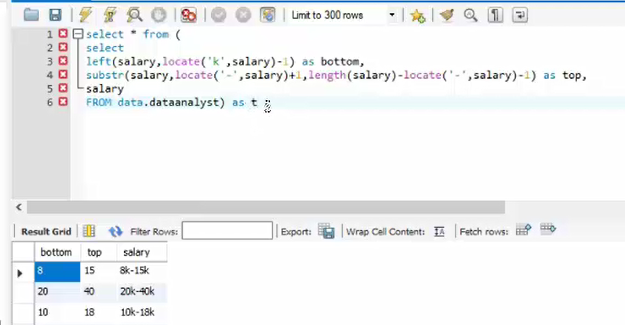
就可以直接引用别名 bottom top 等等
数据清洗
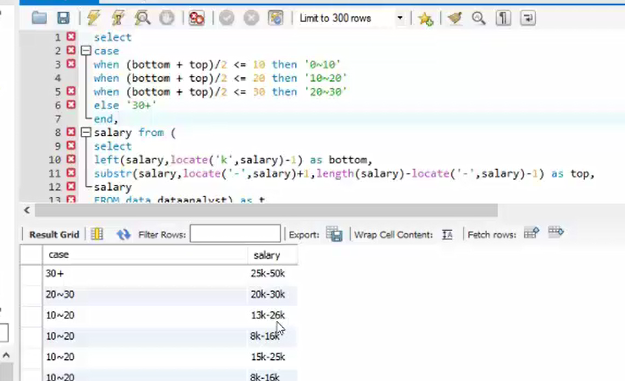
计算为顺序计算

调整一下让代码优雅一些,并且有别名运行起来效果较好。

子查询的字段要保持一致,否则会报错
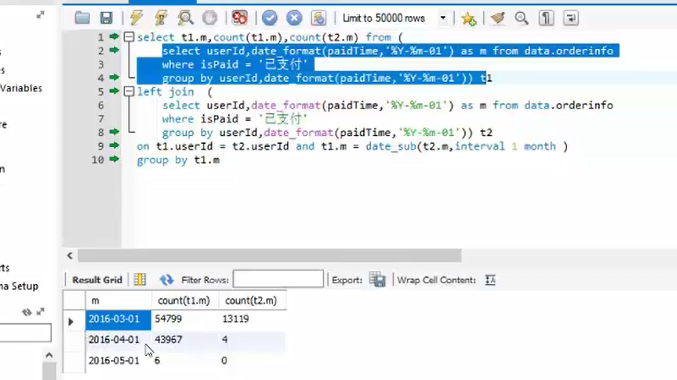
跨表分析,使用子查询
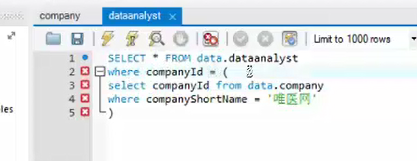
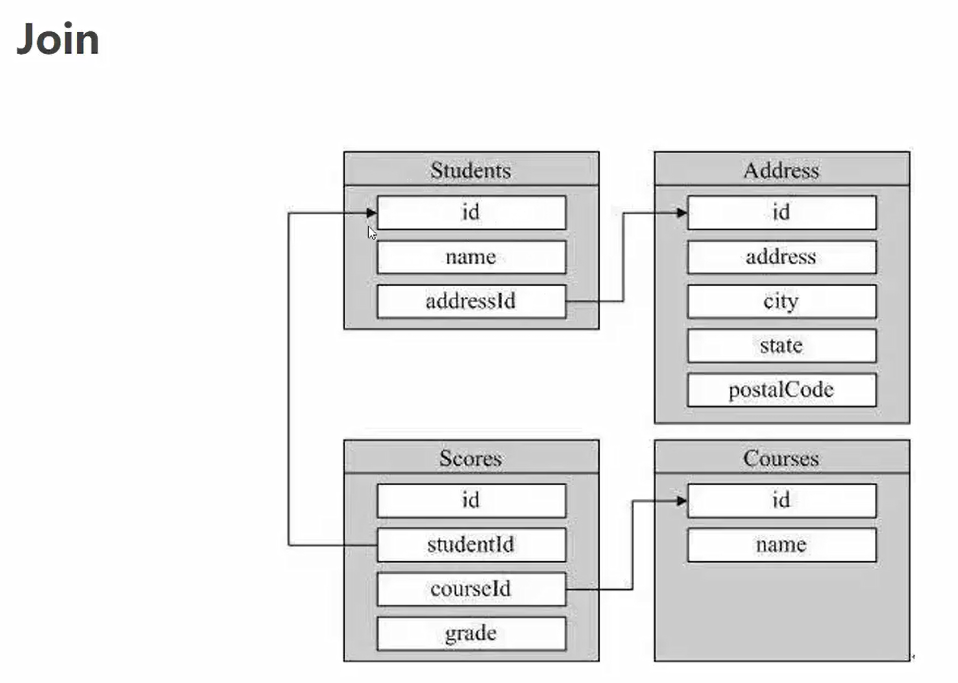
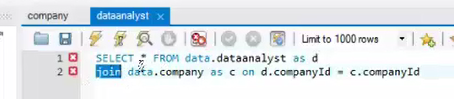
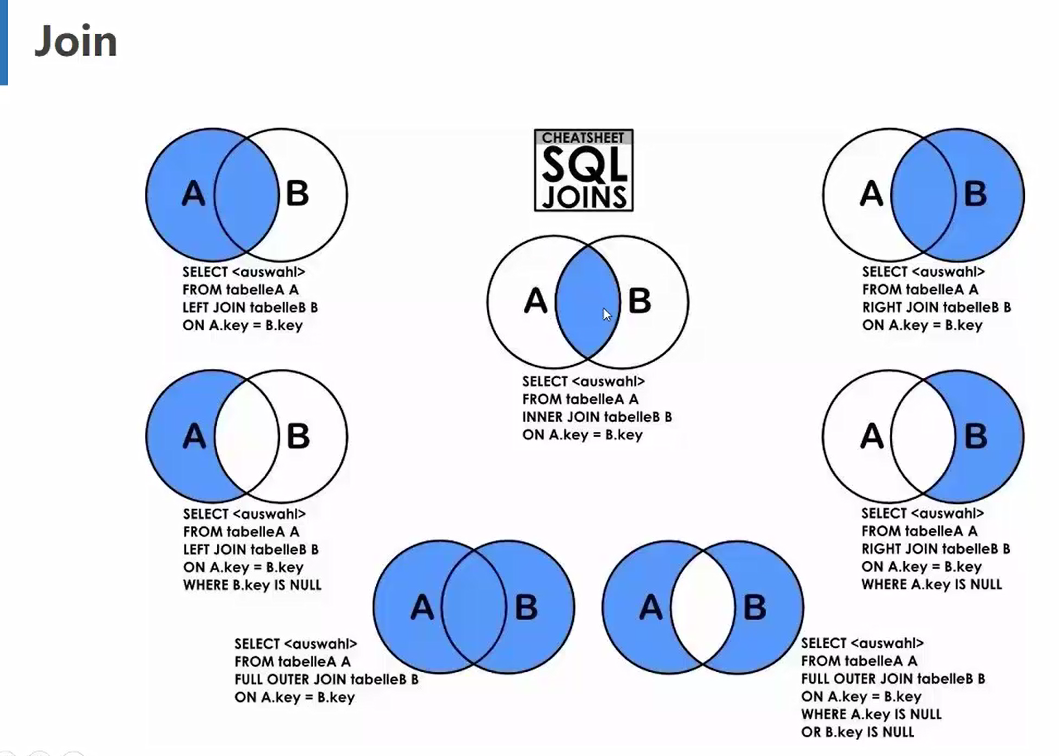
得到的并不是全部的明细字段,通过用jion可以将两张表进行关联。
加载万条以上的数据需要使用命令行的方式:
打开MySQL 5.7 Command Line Client

路径可以直接拖拽进去

指定分割符,否则会报错
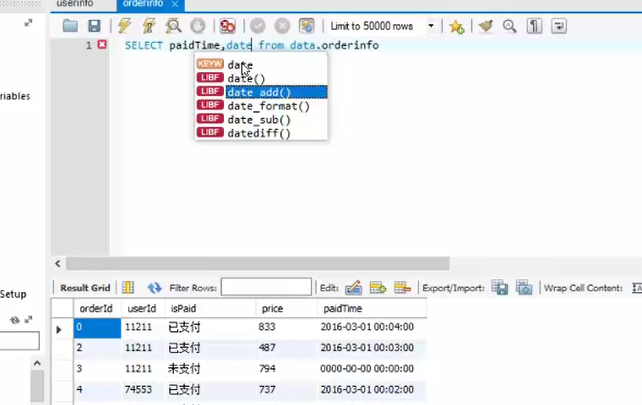
【时间操作】
进行格式的改变


MySQL可链接Power BI 进行使用,在使用的过程中,建议先将语句写好,再在Power BI中运行得出想要添加字段和内容。不建议直接在Power BI上面直接添加进行,因为前者为服务器直接运行后再Power BI中显示结果,后者则是考量自身电脑的性能。
多多结合实际进行练习,或者去课程提供的素材晚上去刷题进行联系。祝看到笔记的所有人都能熟悉掌握MySQL。