整体思路和之前的一篇博客爬虫豆瓣美女一致,这次加入了图片分类,同时利用tkinter模块做成GUI程序
效果如下:
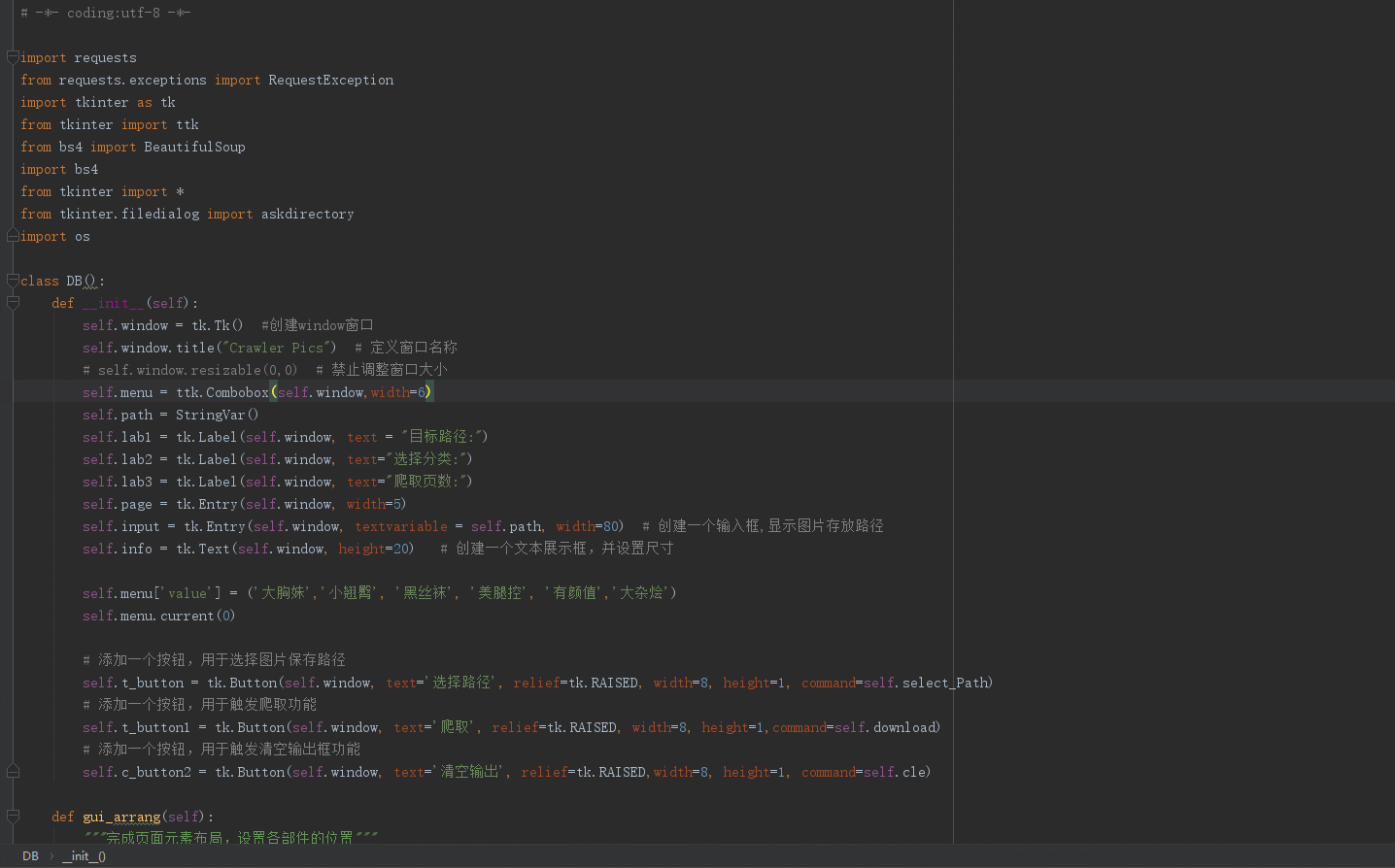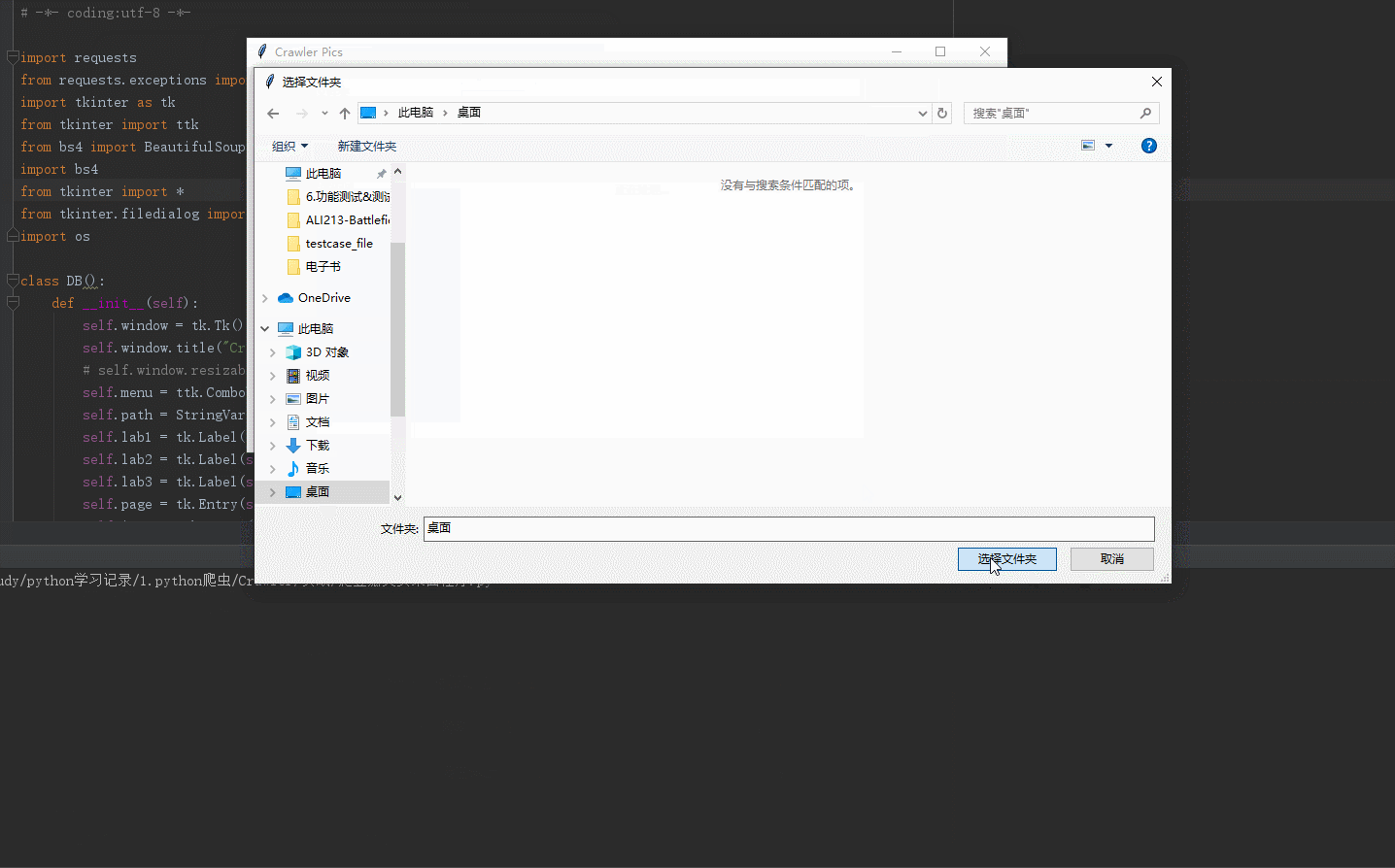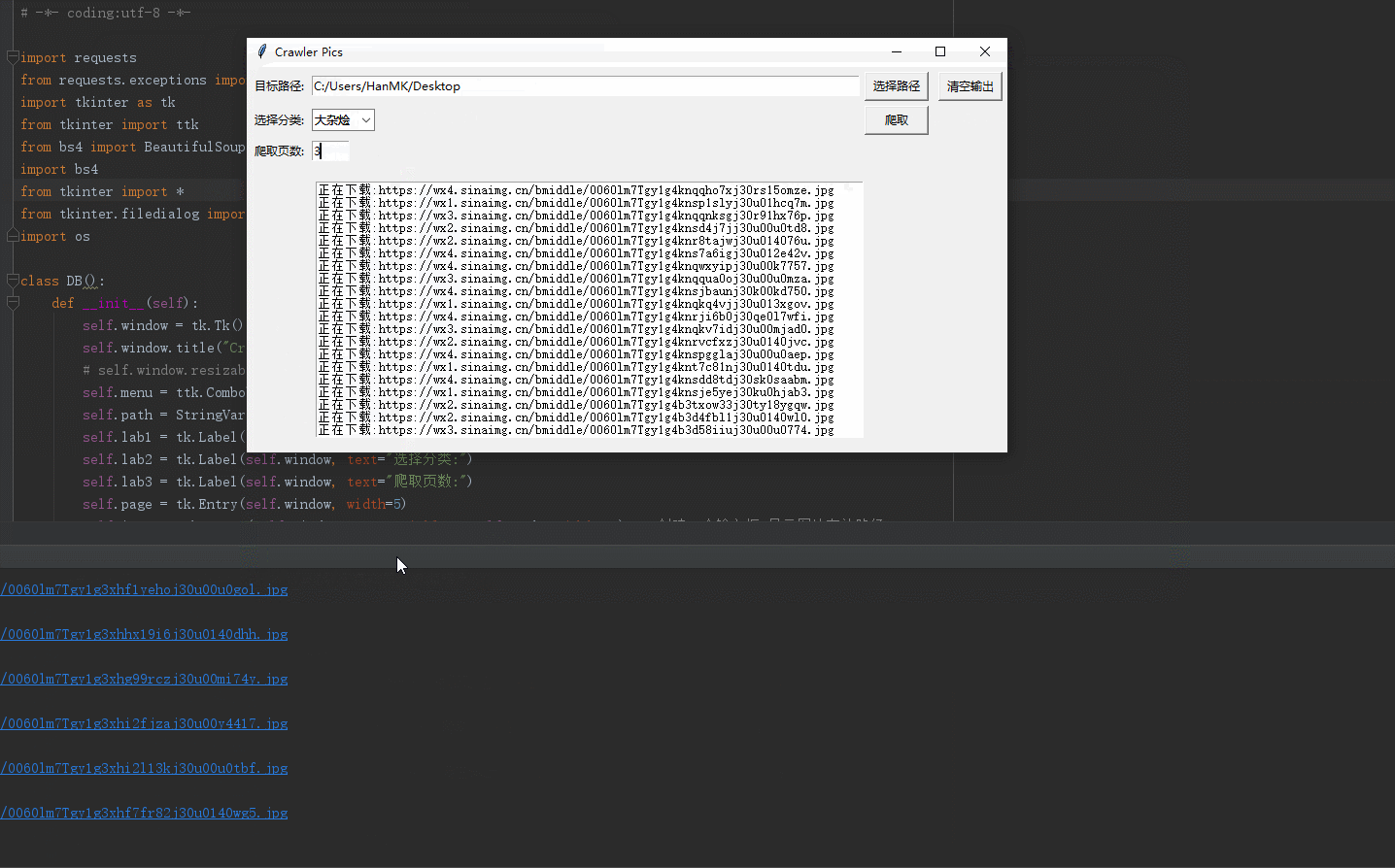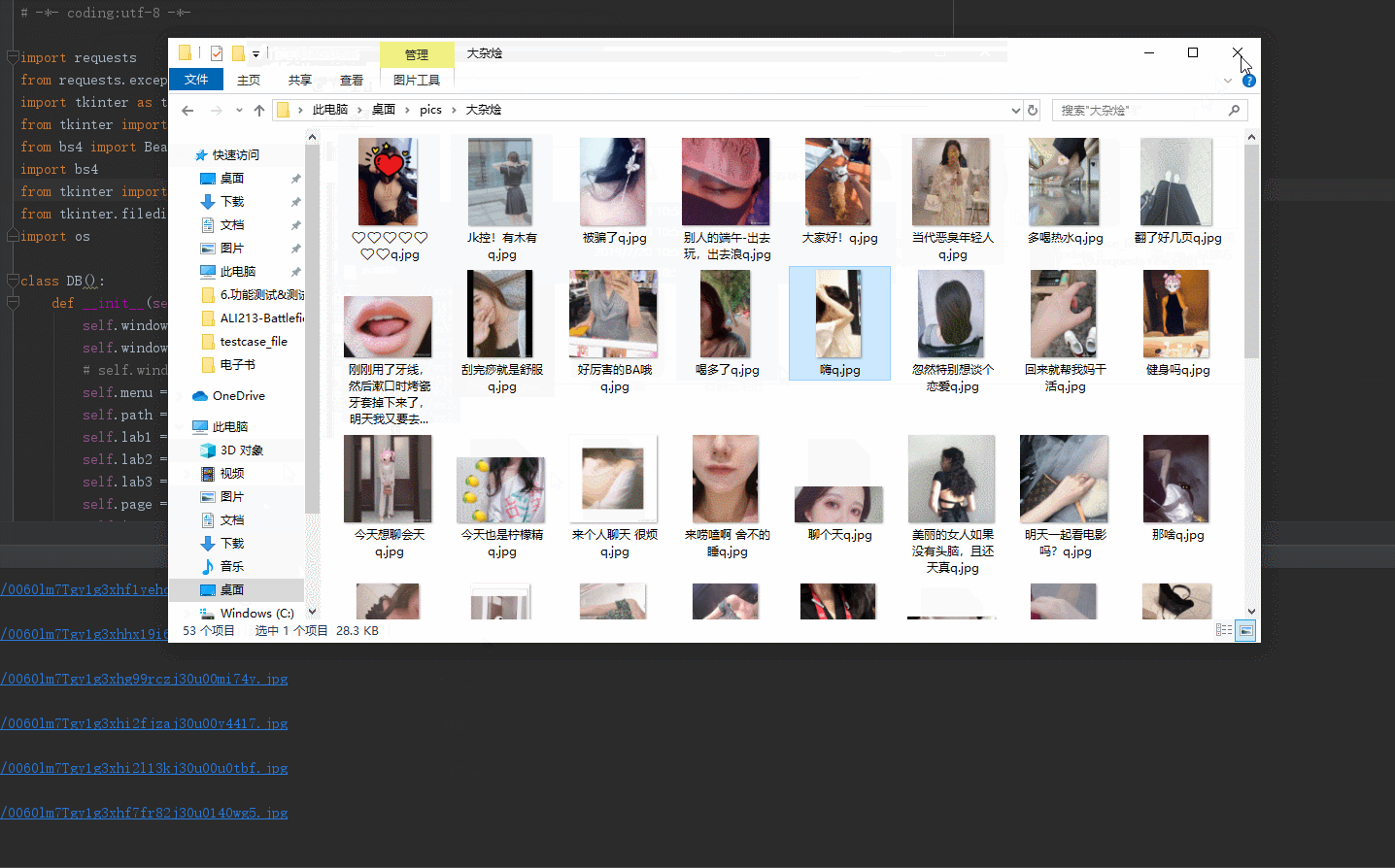
整体代码如下:
1 # -*- coding:utf-8 -*- 2 3 import requests 4 from requests.exceptions import RequestException 5 import tkinter as tk 6 from tkinter import ttk 7 from bs4 import BeautifulSoup 8 import bs4 9 from tkinter import * 10 from tkinter.filedialog import askdirectory 11 import os 12 13 class DB(): 14 def __init__(self): 15 self.window = tk.Tk() #创建window窗口 16 self.window.title("Crawler Pics") # 定义窗口名称 17 # self.window.resizable(0,0) # 禁止调整窗口大小 18 self.menu = ttk.Combobox(self.window,width=6) 19 self.path = StringVar() 20 self.lab1 = tk.Label(self.window, text = "目标路径:") 21 self.lab2 = tk.Label(self.window, text="选择分类:") 22 self.lab3 = tk.Label(self.window, text="爬取页数:") 23 self.page = tk.Entry(self.window, width=5) 24 self.input = tk.Entry(self.window, textvariable = self.path, width=80) # 创建一个输入框,显示图片存放路径 25 self.info = tk.Text(self.window, height=20) # 创建一个文本展示框,并设置尺寸 26 27 self.menu['value'] = ('大胸妹','小翘臀', '黑丝袜', '美腿控', '有颜值','大杂烩') 28 self.menu.current(0) 29 30 # 添加一个按钮,用于选择图片保存路径 31 self.t_button = tk.Button(self.window, text='选择路径', relief=tk.RAISED, width=8, height=1, command=self.select_Path) 32 # 添加一个按钮,用于触发爬取功能 33 self.t_button1 = tk.Button(self.window, text='爬取', relief=tk.RAISED, width=8, height=1,command=self.download) 34 # 添加一个按钮,用于触发清空输出框功能 35 self.c_button2 = tk.Button(self.window, text='清空输出', relief=tk.RAISED,width=8, height=1, command=self.cle) 36 37 def gui_arrang(self): 38 """完成页面元素布局,设置各部件的位置""" 39 self.lab1.grid(row=0,column=0) 40 self.lab2.grid(row=1, column=0) 41 self.menu.grid(row=1, column=1,sticky=W) 42 self.lab3.grid(row=2, column=0,padx=5,pady=5,sticky=tk.W) 43 self.page.grid(row=2, column=1,sticky=W) 44 self.input.grid(row=0,column=1) 45 self.info.grid(row=3,rowspan=5,column=0,columnspan=3,padx=15,pady=15) 46 self.t_button.grid(row=0,column=2,padx=5,pady=5,sticky=tk.W) 47 self.t_button1.grid(row=1,column=2) 48 self.c_button2.grid(row=0,column=3,padx=5,pady=5,sticky=tk.W) 49 50 def get_cid(self): 51 category = { 52 'DX': 2, 53 'XQT': 6, 54 'HSW': 7, 55 'MTK': 3, 56 'YYZ': 4, 57 'DZH': 5 58 } 59 cid = None 60 if self.menu.get() == "大胸妹": 61 cid = category["DX"] 62 elif self.menu.get() == "小翘臀": 63 cid = category["XQT"] 64 elif self.menu.get() == "黑丝袜": 65 cid = category["HSW"] 66 elif self.menu.get() == "美腿控": 67 cid = category["MTK"] 68 elif self.menu.get() == "有颜值": 69 cid = category["YYZ"] 70 elif self.menu.get() == "大杂烩": 71 cid = category["DZH"] 72 return cid 73 74 def select_Path(self): 75 """选取本地路径""" 76 path_ = askdirectory() 77 self.path.set(path_) 78 79 def get_html(self, url, header=None): 80 """请求初始url""" 81 response = requests.get(url, headers=header) 82 try: 83 if response.status_code == 200: 84 # print(response.status_code) 85 # print(response.text) 86 return response.text 87 return None 88 except RequestException: 89 print("请求失败") 90 return None 91 92 def parse_html(self, html, list_data): 93 """提取img的名称和图片url,并将名称和图片地址以字典形式返回""" 94 soup = BeautifulSoup(html, 'html.parser') 95 img = soup.find_all('img') 96 for t in img: 97 if isinstance(t, bs4.element.Tag): 98 # print(t) 99 name = t.get('alt') 100 img_src = t.get('src') 101 list_data.append([name, img_src]) 102 dict_data = dict(list_data) 103 return dict_data 104 105 def get_image_content(self, url): 106 """请求图片url,返回二进制内容""" 107 print("正在下载", url) 108 self.info.insert('end',"正在下载:"+url+' ') 109 try: 110 r = requests.get(url) 111 if r.status_code == 200: 112 return r.content 113 return None 114 except RequestException: 115 return None 116 117 def download(self): 118 base_url = 'https://www.dbmeinv.com/index.htm?' 119 for i in range(1, int(self.page.get())+1): 120 url = base_url + 'cid=' + str(self.get_cid()) + '&' + 'pager_offset=' + str(i) 121 # print(url) 122 header = { 123 'Accept': 'text/html,application/xhtml+xml,application/xml;q = 0.9, image/webp,image/apng,*/*;q=' 124 '0.8', 125 'Accept-Encoding': 'gzip,deflate,br', 126 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 127 'Cache-Control': 'max-age=0', 128 'Connection': 'keep-alive', 129 'Host': 'www.dbmeinv.com', 130 'Upgrade-Insecure-Requests': '1', 131 'User-Agent': 'Mozilla/5.0(WindowsNT6.1;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/' 132 '70.0.3538.102Safari/537.36 ' 133 } 134 list_data = [] 135 html = self.get_html(url) 136 # print(html) 137 dictdata = self.parse_html(html, list_data) 138 139 140 root_dir = self.input.get() 141 case_list = ["大胸妹", "小翘臀", "黑丝袜", "美腿控", "有颜值", "大杂烩"] 142 for t in case_list: 143 if not os.path.exists(root_dir + '/pics'): 144 os.makedirs(root_dir + '/pics') 145 if not os.path.exists(root_dir + '/pics/' + str(t)): 146 os.makedirs(root_dir + '/pics/' + str(t)) 147 148 149 if self.menu.get() == "大胸妹": 150 save_path = root_dir + '/pics/' + '大胸妹' 151 for t in dictdata.items(): 152 try: 153 # file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg') 154 file_path = save_path + '/' + t[0] + 'q' + '.jpg' 155 if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 156 with open(file_path, 'wb') as f: 157 f.write(self.get_image_content(t[1])) 158 f.close() 159 print('文件保存成功') 160 except FileNotFoundError: 161 continue 162 163 elif self.menu.get() == "小翘臀": 164 save_path = root_dir + '/pics/' + '小翘臀' 165 for t in dictdata.items(): 166 try: 167 # file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg') 168 file_path = save_path + '/' + t[0] + 'q' + '.jpg' 169 if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 170 with open(file_path, 'wb') as f: 171 f.write(self.get_image_content(t[1])) 172 f.close() 173 print('文件保存成功') 174 except FileNotFoundError: 175 continue 176 177 elif self.menu.get() == "黑丝袜": 178 save_path = root_dir + '/pics/' + '黑丝袜' 179 for t in dictdata.items(): 180 try: 181 # file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg') 182 file_path = save_path + '/' + t[0] + 'q' + '.jpg' 183 if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 184 with open(file_path, 'wb') as f: 185 f.write(self.get_image_content(t[1])) 186 f.close() 187 print('文件保存成功') 188 except FileNotFoundError: 189 continue 190 191 elif self.menu.get() == "美腿控": 192 save_path = root_dir + '/pics/' + '美腿控' 193 for t in dictdata.items(): 194 try: 195 # file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg') 196 file_path = save_path + '/' + t[0] + 'q' + '.jpg' 197 if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 198 with open(file_path, 'wb') as f: 199 f.write(self.get_image_content(t[1])) 200 f.close() 201 print('文件保存成功') 202 except FileNotFoundError: 203 continue 204 205 elif self.menu.get() == "有颜值": 206 save_path = root_dir + '/pics/' + '有颜值' 207 for t in dictdata.items(): 208 try: 209 # file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg') 210 file_path = save_path + '/' + t[0] + 'q' + '.jpg' 211 if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 212 with open(file_path, 'wb') as f: 213 f.write(self.get_image_content(t[1])) 214 f.close() 215 print('文件保存成功') 216 except OSError: 217 continue 218 219 elif self.menu.get() == "大杂烩": 220 save_path = root_dir + '/pics/' + '大杂烩' 221 for t in dictdata.items(): 222 try: 223 # file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg') 224 file_path = save_path + '/' + t[0] + 'q' + '.jpg' 225 if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 226 with open(file_path, 'wb') as f: 227 f.write(self.get_image_content(t[1])) 228 f.close() 229 print('文件保存成功') 230 except FileNotFoundError: 231 continue 232 233 def cle(self): 234 """定义一个函数,用于清空输出框的内容""" 235 self.info.delete(1.0,"end") # 从第一行清除到最后一行 236 237 238 def main(): 239 t = DB() 240 t.gui_arrang() 241 tk.mainloop() 242 243 if __name__ == '__main__': 244 main()
关键点:
1.如何使用tkinter调用系统路径
2.构造url,参数化图片分类、抓取页数
3.使用tkinter获取输入参数传给执行代码
下面是练习的时候写的简陋版,不包含tkinter,主要是理清思路:
1 import re 2 import requests 3 import os 4 from requests.exceptions import RequestException 5 6 case = str(input("请输入你要下载的图片分类:")) 7 category = { 8 'DX': 2, 9 'XQT': 6, 10 'HSW': 7, 11 'MTK': 3, 12 'YYZ': 4, 13 'DZH': 5 14 } 15 def get_cid(): 16 cid = None 17 if case == "大胸妹": 18 cid = category["DX"] 19 elif case == "小翘臀": 20 cid = category["XQT"] 21 elif case == "黑丝袜": 22 cid = category["HSW"] 23 elif case == "美腿控": 24 cid = category["MTK"] 25 elif case == "有颜值": 26 cid = category["YYZ"] 27 elif case == "大杂烩": 28 cid = category["DZH"] 29 return cid 30 31 32 33 base_url = 'https://www.dbmeinv.com/index.htm?' 34 url = base_url + 'cid=' + str(get_cid()) 35 r = requests.get(url) 36 # print(r.status_code) 37 html = r.text 38 # print(r.text) 39 # print(html) 40 41 name_pattern = re.compile(r'<img class="height_min".*?title="(.*?)"', re.S) 42 src_pattern = re.compile(r'<img class="height_min".*?src="(.*?.jpg)"', re.S) 43 44 name = name_pattern.findall(html) # 提取title 45 src = src_pattern.findall(html) # 提取src 46 data = [name,src] 47 # print(name) 48 # print(src) 49 d=[] 50 for i in range(len(name)): 51 d.append([name[i], src[i]]) 52 53 dictdata = dict(d) 54 # for i in dictdata.items(): 55 # print(i) 56 57 def get_content(url): 58 try: 59 r = requests.get(url) 60 if r.status_code == 200: 61 return r.content 62 return None 63 except RequestException: 64 return None 65 66 root_dir = os.path.dirname(os.path.abspath('.')) 67 68 case_list = ["大胸妹","小翘臀","黑丝袜","美腿控","有颜值","大杂烩"] 69 for t in case_list: 70 if not os.path.exists(root_dir+'/pics'): 71 os.makedirs(root_dir+'/pics') 72 if not os.path.exists(root_dir+'/pics/'+str(t)): 73 os.makedirs(root_dir+'/pics/'+str(t)) 74 75 def Type(type): 76 save_path = root_dir + '/pics/' + str(type) 77 # print(save_path) 78 for t in dictdata.items(): 79 try: 80 #file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg') 81 file_path = save_path + '/' + t[0]+ 'q' +'.jpg' 82 print("正在下载: "+'"'+t[0]+'"'+t[1]) 83 if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 84 with open(file_path, 'wb') as f: 85 f.write(get_content(t[1])) 86 f.close() 87 except FileNotFoundError: 88 continue 89 if case == "大胸妹": 90 Type(case) 91 92 elif case == "小翘臀": 93 Type(case) 94 95 elif case == "黑丝袜": 96 Type(case) 97 98 elif case == "美腿控": 99 Type(case) 100 101 elif case == "有颜值": 102 Type(case) 103 104 elif case == "大杂烩": 105 Type(case)
效果如下
