函数的基础概念
1、函数是python为了代码最大程度的重用和最小化代码冗余而提供的基本程序结构;
2、函数是一种设计工具,它能让程序员将复杂的系统分解为可管理的部件;
3、函数用于将相关功能打包并参数化;
4、在python中可以创建4中函数:
- 全局函数:定义在模块中
- 局部函数:嵌套于其他函数中
- lambda(匿名)函数:表达式
- 方法:与特定数据类型关联的函数,并且只能与数据类型关联一起使用(定义在类中的函数)
5、python提供了很多内置函数
def是一个语句;lambda是一个表达式,可以出现在任意表达式出现的地方
函数和过程的区别:函数都有return返回值,在python中,通常都有返回对象
创建函数
1、语法:
def functionName(parameters):
suite
2、一些相关的概念
- def 是一个可执行的语句
- 因此可以出现在任何能够使用语句的地方,甚至可以嵌套于其他语句,例如 if 或 while 中
- def 创建了一个对象并将其赋值给一个变量名(即函数名)
- return用于返回结果对象,其为可选;无return语句的函数自动返回None对象;
- 返回多个值时,彼此间用逗号隔开,且组合为元组形式返回一个对象;
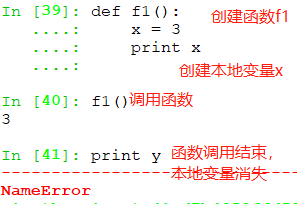
- def语句运行之后,可以在程序中通过函数后附件括号进行调用,比如f1()
例如:printName 就是一个函数,printName()就是函数调用

函数:名称空间
一个变量所能够生效的范围,就叫做变量的作用域,这个作用域通常称之为名称空间
函数作用域
1、python创建、改变或查找变量名都是在名称空间中进行;
2、在代码中变量名被赋值的位置决定了其能被访问到的范围
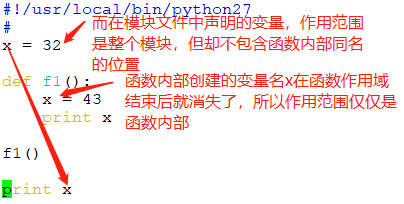
3、函数定义了本地作用域,而模块定义了全局作用域
- 每个模块都是一个全局作用域,因此,全局作用域的范围仅限于单个程序文件;
- 每次对函数的调用都会创建一个新的本地作用域,赋值的变量除非声明为全局变量,否则均为本地变量;
- 所有的变量名都可以归纳为本地、全局或内置的(由__bulitin__模块提供)


变量名解析:LEGB原则
变量名引用分三个作用域进行:首先是本地、之后是函数内、接着是全局,最后是内置
作用域越小,变量的优先级越高



Python闭包:
在函数嵌套时,如果直接返回内层函数的话,同时如果内层函数调用了外层函数的变量,内层函数会自动记忆外层函数的变量,这种机制就叫做函数的闭合,也就是所谓的工厂函数
闭包法则:
定义在外层函数内,但是却由内层函数引用的变量,在外层函数返回时,如果外层函数直接返回了内层函数作为返回结果,再次调用内层函数可以直接使用外层函数原有的变量,内层函数实现记忆的效果



参数传递
1、参数的传递是通过自动将对象赋值给本地变量实现的
2、不可变参数通过“值”进行传递
- 在函数内部改变形参的值,只是让其引用了另一个对象
3、可变参数通过“指针”进行传递
- 在函数内部改变形参的值,将直接修改引用的对象
4、有两种方式可避免可变参数被函数修改:
- 直接传递可变对象的副本:testFunc(A,B[:])
- 在函数内部创建可变参数的副本:B=B[:]


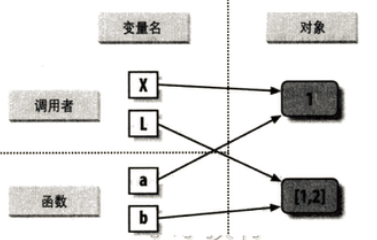
定义变量 m = 3,然后定义变量 x = m,此时 x 的指针指向内存中 3 的地址,
由于数值是不可变对象,当 x -= 1 时,这是 x 指向的对象就是 2 了,所以 x 又指向了内存中 2 的地址;
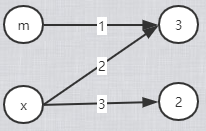
列表是可以原处修改的,l1 是执行列表的内存地址,x也同样指向列表的内存地址(这里是浅复制),他们指向同一个列表的内存地址
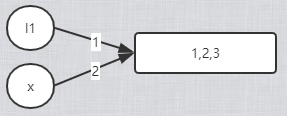
尽可能不要在函数内部修改传递过来的可变对象,使用对象复制可以避免,l1[:] 做切片,这里是使用了列表的值,而不是列表本身

参数匹配模型
1、默认情况下,参数通过其位置进行传递,从左至右,这意味着必须精确的传递和函数头部一样多的参数;
2、但也可以通过关键字参数、默认参数或参数容器等改变这种机制
- 位置: 从左至右
- 关键字参数: 使用 “name=value” 的语法通过参数名进行匹配
- 默认参数: 定义函数时使用 “name=value” 的语法直接给变量一个值,从而传入的值可以少于参数个数
- 可变参数: 定义函数时使用 * 开头的参数,可用于收集任意多基于位置或关键字的参数
- 可变参数解包:调用函数时,使用 * 开头的参数,可用于将参数集合打散,从而传递任意多基于位置或关键字的参数
参数传递形式
位置参数:从左向右
关键字参数:按关键名称匹配


位置和关键字混用,混用上面两种方式时,格式为:所有位置参数,所有的关键字参数
注:非关键字参数不能放在关键字参数后面,这里混用位置参数和关键字参数时,位置参数必须在关键字参数前面


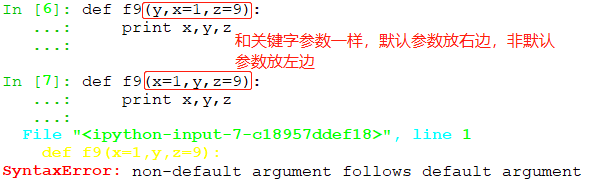
定义函数时使用默认参数:有默认值的参数
混用有默认和无默认值的参数时,无默认值的应该放在前面

调用函数时使用可变参数要求:定义函数时使用
使用*:收集位置参数
使用**:收集关键字参数



可变参数解包:是在调用函数时,这个和上面的可变参数相反,可变参数是定义函数时使用 调用是为了分解,定义是为了整合




当变量、列表和字典混用时,无论是调用函数还是定义函数,一定是按照特定次序的,即次序是位置-->任意位置-->任意关键字

匿名函数lambda (lambda是个无名称的函数)
def 是一个语句;lambda 是一个表达式,可以出现在任意表达式出现的地方
1、lambda运算符
- lambda args:expression
- args:以逗号分割的参数列表
- expression:用到args中各参数的表达式
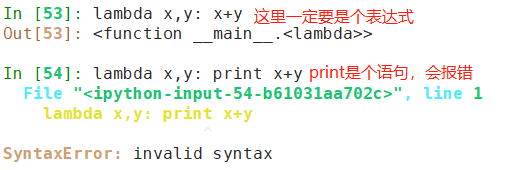
- lambda语句定义的代码必须是合法的表达式,不能出现多条件语句(可使用if的三元表达式)和其他非表达式语句,如for和while等
- lambda的首要用途是指定短小的回调函数
- lambda将返回一个函数而不是将函数赋值给某变量名
2、注意:
- lambda是一个表达式而非语句
- lambda是一个单个表达式,而不是一个代码块

3、def语句创建的函数将赋值给某变量名,而lambda表达式则直接返回函数
4、lambda也支持使用默认参数


可以把每一种处理机制定义成lambda,然后对这个数据对象掉调用lambda
python的函数式是编程内置的几个直接实现将函数应用在其他数据尤其是序列上的机制
python函数式编程
1、函数式编程
也称作泛函编程,是一种编程范型
它将电脑运算视为数学上的函数计算,并且避免状态以及可变数据
函数式编程语言最重要的基础是lambda演算,而且lambda演算的函数可以接受函数当作输入和输出
2、python支持有限的函数式编程功能

把函数当参数传递给另一个参数
filter()
fliter (func,seq):fliter过滤 func函数 seq序列 功能:把func应用在seq的每一个元素上,并返回一个新序列。
func是一个二元函数,也叫布尔函数,seq的值被布尔函数func判断以后,能够识别true或false,
如果seq序列中的值可以使func的结果为真,则返回这个seq序列的值,最后形成一个的元素列表;
过滤器
- filter() 为已知的序列的每个元素调用给定的布尔函数
- 调用中,返回值为非零值的元素将被添加至一个列表中
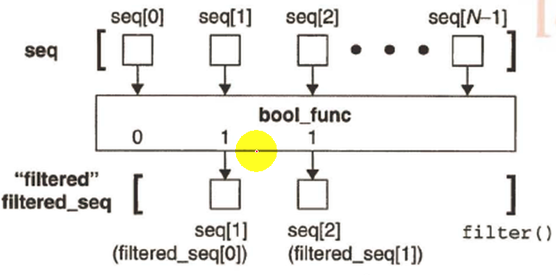

练习:返回/etc/passwd中包含了/bin/bash字串的所有用户名为一个列表
map()
1、映射器
- map()将函数调用“映射”到每个序列的对应元素上,并返回一个含有所有返回的列表
2、带有单个列表的map()

3、带有多个队列的map()
将不同列表的同一个位置的元素整合成一个元组,最后生成一个元组列表,
生成的元组列表是经过map对每个序列同一位置的元素计算过后得到的;
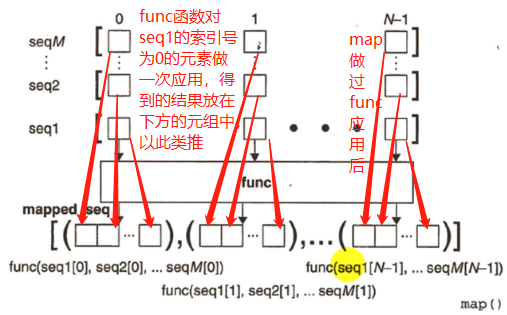
map (func,seq1[,seq2...]) 将函数func应用在给定的序列上,并用一个列表来提供返回值;
如果func为none,则func表现为一个身份函数,返回一个含有每个序列中元素集合的n个元组的列表。
map的目的是做映射,做映射的结果就是生成元组列表
让两个列表快速的构建成元素列表就用map 让每个元素都乘以2并返回这个元素本身


reduce()
reduce (func,seq[,init]) 将二元函数作用于seq序列的元素,每次携带一对(先前的结果以及下一个序列的元素),连续的将现有的结果和下一值作用在获得的随后的结果上,最后减少我们的序列为一个单一的返回值;如果初始值init给定,第一个比较会是init和第一个序列元素而不是序列的头两个元素,即如果由初始值,就计算初始值和第一个元素,如果没有初始值就计算第一个元素和第二个元素。
reduce一定是接受两个参数,返回一个值。
