昨天晚上爬完安心的躺在床上,一想不对劲,我爬的只是小图,点进去之后会有高清图,怎么能放过? 好 今天换个口味 制服美女吧
let's do it
神清气爽
由于图片比较多,然后一个图集爬完,切另一个会有些开销。就用一下多线程,对主站上的30位佳丽,并发爬区,可大大加快速度。引入多线程的库。(里面也有多进程)
from concurrent import futures
由于用多线程,即使有睡眠,可能请求还是会过于频繁,我可不想被封ip,于是我找了几个浏览器的User-Agent,存在一个list里,每次请求图片随机选择User-Agent,这样可以一定程度上避免被搞。
# 收集到的常用Header my_headers = [ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14", "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)", 'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11', 'Opera/9.25 (Windows NT 5.1; U; en)', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)', 'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)', 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12', 'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9', "Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7", "Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 " ]
准备工作差不多了,下一步就是获得进入每个图集的url,注意这个与上一篇的src是不一样的, 上一篇src是封面小图的图片数据,这次要获取的是进入链接。
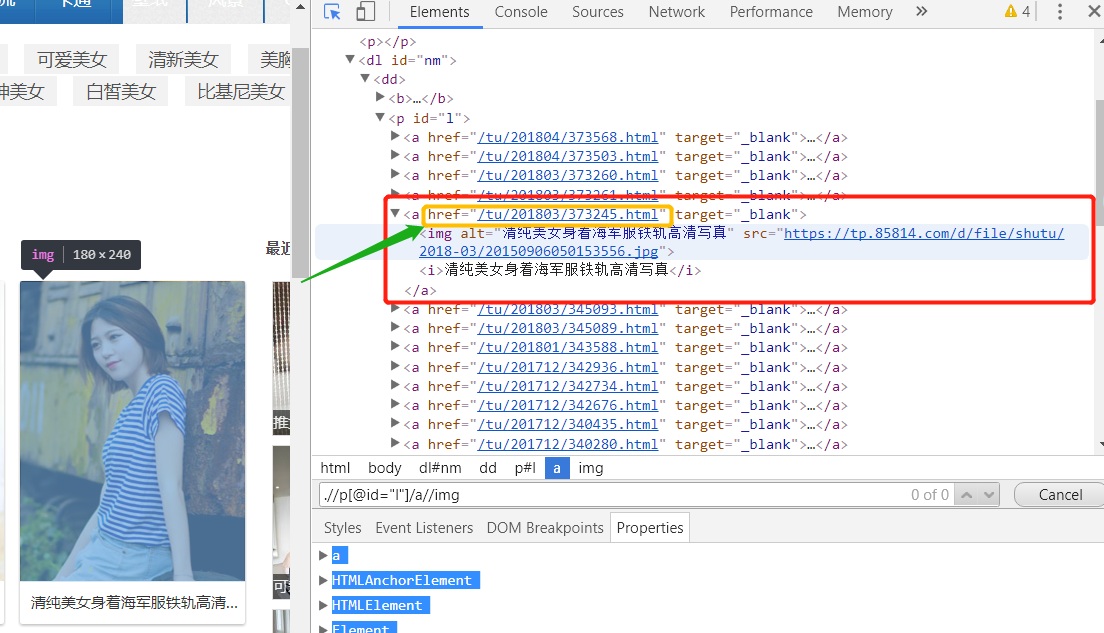
每个封面都是在一个a标签里,而href字段就是我们要的链接,其实它不是一个真正的链接 https都没有。 先点击下左边的图片
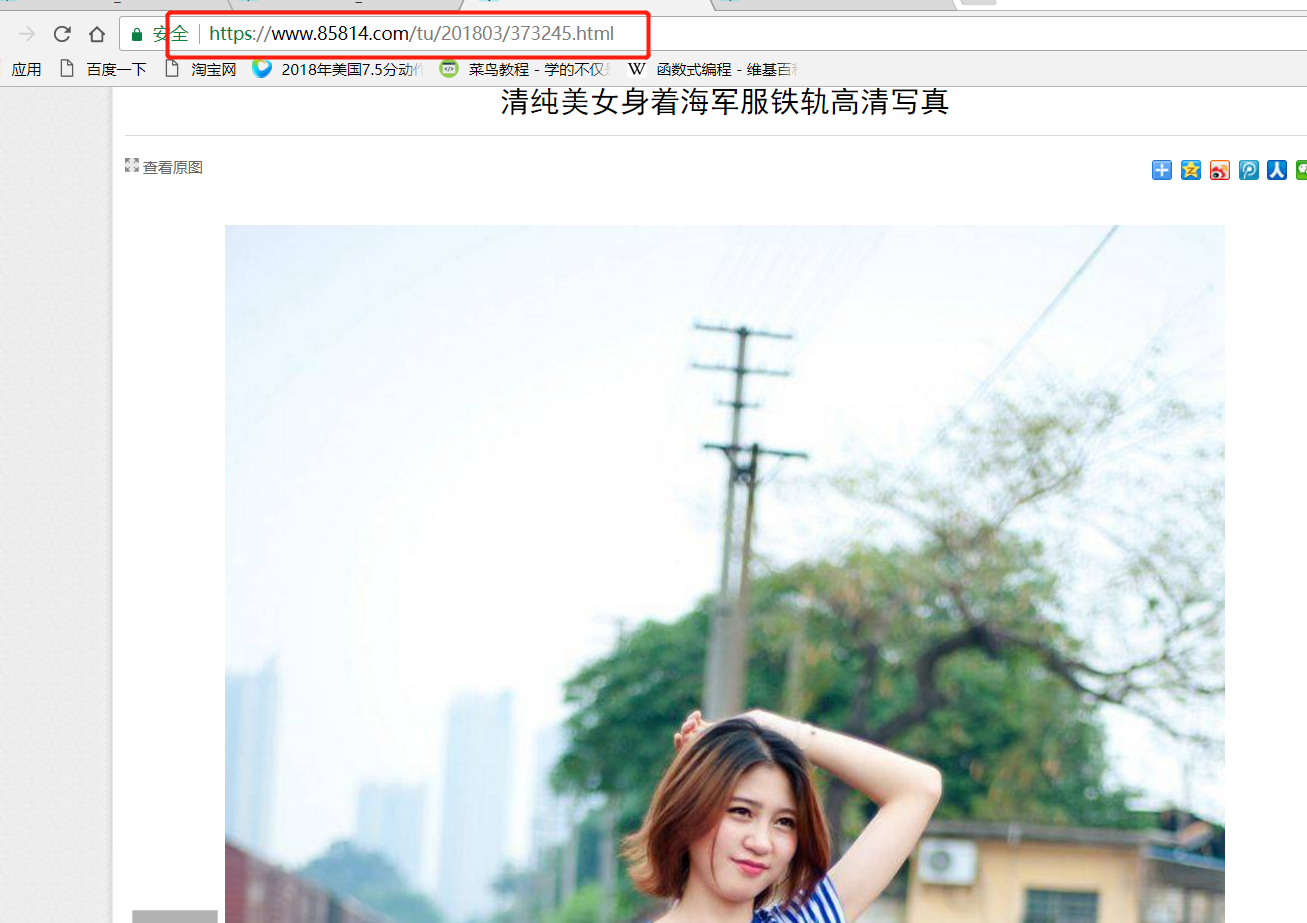
可以发现上面的href字段正好是接在主网站后面的,所以一会哪这个链接进行下字符串处理就行了。
url = 'https://www.85814.com/meinv/zhifumeinv/' link_base ='https://www.85814.com/'
xpath里面填的相信看过上一篇的应该都清楚怎么找了这里就不详细说了,附上一篇链接 https://www.cnblogs.com/hao11/p/11706502.html
我们先写主函数, 然后对每个图集分别调用download函数,只要传url和存放地址就行了(不同图集分开存放)
1 def main(): 2 url = 'https://www.85814.com/meinv/zhifumeinv/' 3 link_base ='https://www.85814.com/' 4 rootdirnames = url.split('/')[-2] + '/' 5 if not os.path.exists(rootdirnames): #根路径,路径不存在的话自动创建 需要import os 6 os.makedirs(rootdirnames) 7 #请求主站 8 resp = requests.get(url, headers=headers,timeout=10,verify=False) 9 html = etree.HTML(resp.text) 10 #获取主页面中,进入个人图集的路径 11 Inner_Link = html.xpath('.//p[@id="l"]/a/@href') 12 # 多线程,开50个,对主页面中30个图片进行并发处理下载 13 ex = futures.ThreadPoolExecutor(max_workers=30) 14 num = 1 #用来给路径命名 15 #对每一个图集分别处理 16 for url_inner in Inner_Link: 17 time.sleep(0.2) 18 #拼接出单个图集的url 19 url = link_base +url_inner 20 dirname = '{}/{}/'.format(rootdirnames,str(num)) 21 if not os.path.exists(dirname): 22 os.makedirs(dirname) 23 #多线程 第一个参数是函数名,后面接收的是第一个传入函数的参数表,此处只是提交线程 24 ex.submit(download_pack, url, dirname) 25 #download_pack(url, dirname) #单线程模式,注释多线程,开单线程可以比较下速度 26 num = num + 1
主函数已经写好了,接下来 分析每个图集里面是怎么构成的,点进去
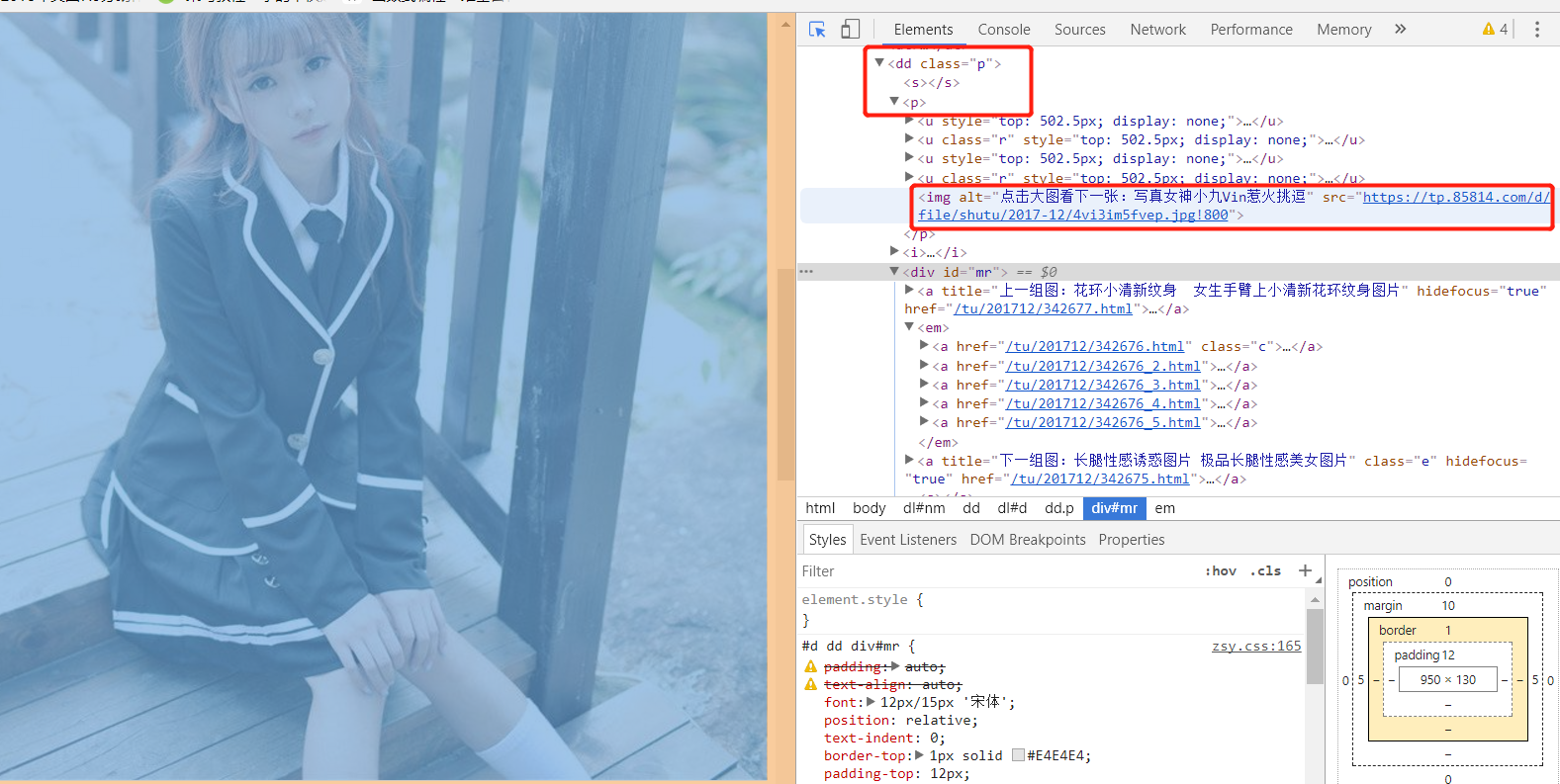
开启元素审查,可以找到高清图的src也就是数据放的地方,图片的xpath为 .//dd[@class="p"]/p/img/@src,好现在能爬一张,但是一个图集有很多张,怎么分别爬去呢,看下面
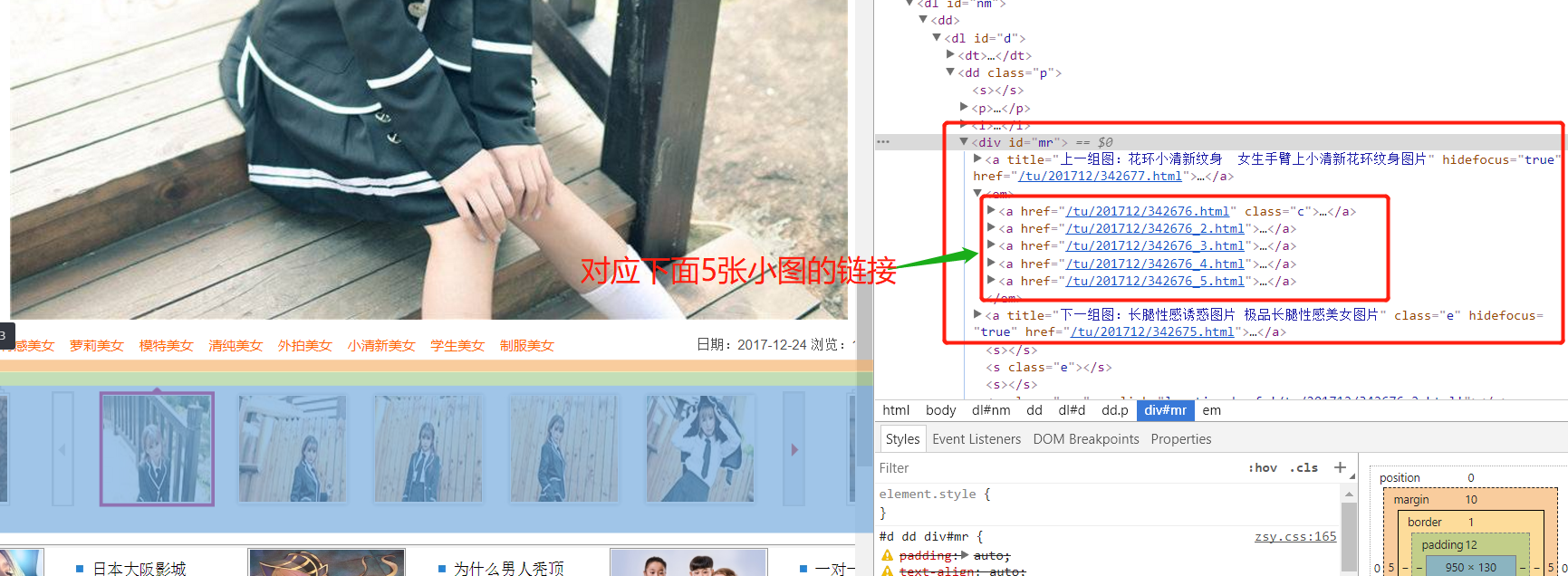
都是有固定套路,第几张后面就接数字,第一张有点不同,代码处理下就ok。用一个num 往上加,知道response 不是200就退出,也就是这个图集爬完了,看代码
def download_pack(url,dirname): #随机选择伪装成的浏览器 headers['User-Agent'] = random.choice(my_headers) cur_num = 2; while url: resp_Inner = requests.get(url, headers=headers,timeout=10,verify=False) if resp_Inner.status_code != 200: print("{} download over!".format(url.split('_')[0])) break html_Inner = etree.HTML(resp_Inner.text) src = html_Inner.xpath('.//dd[@class="p"]/p/img/@src') #请求图片 # 通过xpath获得的src是一个list,只有一个值取0就行了 img = requests.get(src[0], headers=headers, timeout=10, verify=False) #可以看下src到底是个什么 .jpg后面接了一个!800 此处去掉 获得文件名 filename = src[0].split('/')[-1].split('!')[0] print(filename) with open('{}/{}'.format(dirname,filename),'wb') as file: file.write(img.content) #下一个url 用cur_num去实现“翻页”。 if 2==cur_num: url = "{}_{}.html".format(url.split('.html')[0],cur_num) else: url = "{}_{}.html".format(url.split('_')[0], cur_num) cur_num=cur_num+1
好 执行main函数 会在当前路径创建一个路径来保存图片。当然还有很多可以改进的地方,比如说翻页可以用上一个图集一直翻,还有文件的名字可以用中文(涉及字符转换,目前对这一块不是很熟,学习后再做),还有可以同用不同的请求头一样用建立一个ip池,代理ip网上还是很多免费的。学习到了再来分享。
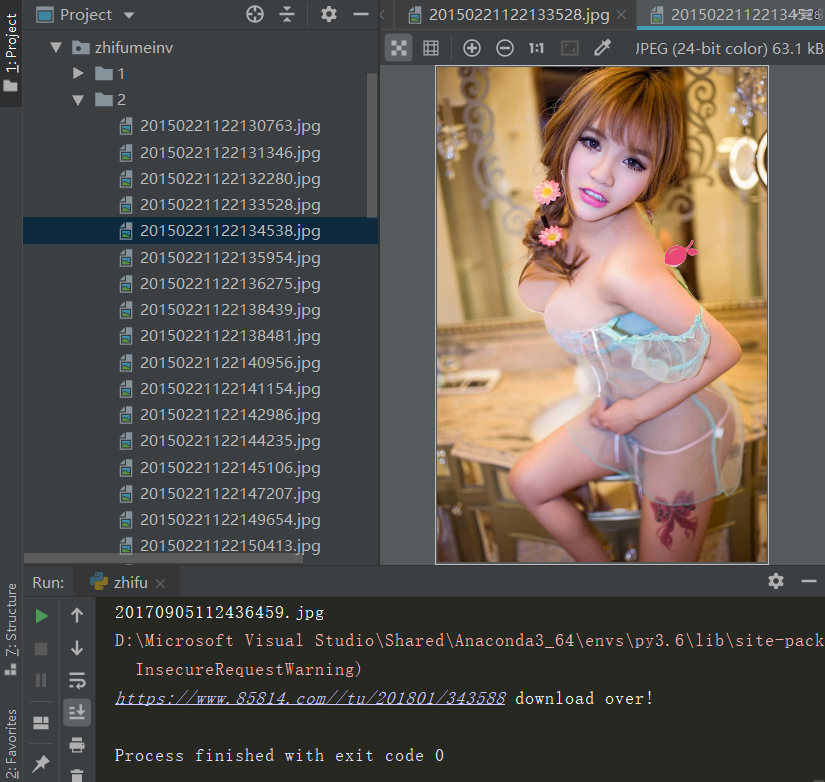
一个简单的爬虫就完成了。
学习尚浅,有错误或不当之处还请指正。