如果觉得不错,请给博主点个赞呗!!! 谢谢
如果觉得不错,请给博主点个赞呗!!! 谢谢
如果觉得不错,请给博主点个赞呗!!! 谢谢
1、概览
Spark Streaming 是核心 Spark API 的扩展,它支持对实时数据流进行可伸缩的、高吞吐量的、容错的流处理。数据可以从 Kafka、 Kinesis 或 TCP sockets 等许多来源获取,也可以使用 map、 reduce、 join 和 window 等高级函数表示的复杂算法进行处理。最后,可以将处理过的数据推送到文件系统、数据库和实时仪表板。事实上,您可以将 Spark 的机器学习和图形处理算法应用于数据流。

在内部,它的工作原理如下。Spark Streaming 接收实时输入数据流并将数据分批,然后由 Spark 引擎处理以批量生成最终结果流。

Spark Streaming 提供了一种称为离散化流(discreated stream)或 DStream 的高级抽象,它表示一个连续的数据流。可以从 Kafka 和 Kinesis 等源的输入数据流创建 DStreams,也可以对其他 DStreams 应用高级操作。在内部,DStream 表示为 rdd 序列。
本指南向您展示如何开始使用 DStreams 编写 Spark Streaming 程序。您可以用 Scala、 Java 或 Python (在 Spark 1.2中引入)编写 Spark Streaming 程序,所有这些在本指南中都有介绍。您将在本指南中找到可以在不同语言的代码片段之间进行选择的选项卡。
注意: 在 Python 中有一些 api 是不同的或者不可用的。在本指南中,您将发现 pythonapi 标记突出显示了这些差异。
2、一个简单的例子
在我们详细介绍如何编写自己的 Spark Streaming 程序之前,让我们快速了解一下简单的 Spark Streaming 程序是什么样的。假设我们要计算从侦听 TCP 套接字的数据服务器接收的文本数据中的字数。你所需要做的就是:。
首先,我们将 Spark Streaming 类的名称和 StreamingContext 中的一些隐式转换导入到环境中,以便将有用的方法添加到我们需要的其他类中(如 DStream)。 Streamingcontext 是所有流功能的主要入口点。 我们用两个执行线程创建一个本地 StreamingContext,批处理间隔为1秒。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ // 从Spark 1.3开始就没有必要了
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
// b. 传递SparkConf对象,构建流式上下文对象, TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context: StreamingContext = new StreamingContext(sparkConf, Seconds(BATCH_INTERVAL))
使用这个context,我们可以创建一个 DStream,它表示来自 TCP 源的流数据,指定为主机名(如 localhost)和端口(如9999)。
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
这个DStream类型的 lines 表示将从数据服务器接收的数据流。此 DStream 中的每个记录都是一行文本。接下来,我们要将行按空格字符拆分为单词。
// Split each line into words
val words = lines.flatMap(_.split(" "))
flatMap 是一个一对多的 DStream 操作,它通过从源 DStream 中的每个记录生成多个新记录来创建一个新的 DStream。在这种情况下,每一行将被分割为多个单词,单词流将表示为单词 DStream。接下来,我们要统计这些单词。
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
words DStream 进一步被映射(一对一的转换)到一个(word,1)的 pairs DStream,然后将其简化以获得每批数据中单词的频率。最后,wordCounts.print () 将每秒打印一些生成的计数。
请注意,当这些行被执行时,Spark Streaming 只设置它在启动时将执行的计算,而且还没有真正的处理开始。要在设置完所有转换之后启动处理,我们最后调用
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
如下是完整的代码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
// scalastyle:off println
package org.apache.spark.examples.streaming
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Counts words in UTF8 encoded, '
' delimited text received from the network every second.
*
* Usage: NetworkWordCount <hostname> <port>
* <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data.
*
* To run this on your local machine, you need to first run a Netcat server
* `$ nc -lk 9999`
* and then run the example
* `$ bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999`
*/
object NetworkWordCount {
def main(args: Array[String]): Unit = {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create a socket stream on target ip:port and count the
// words in input stream of
delimited text (e.g. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
// scalastyle:on println
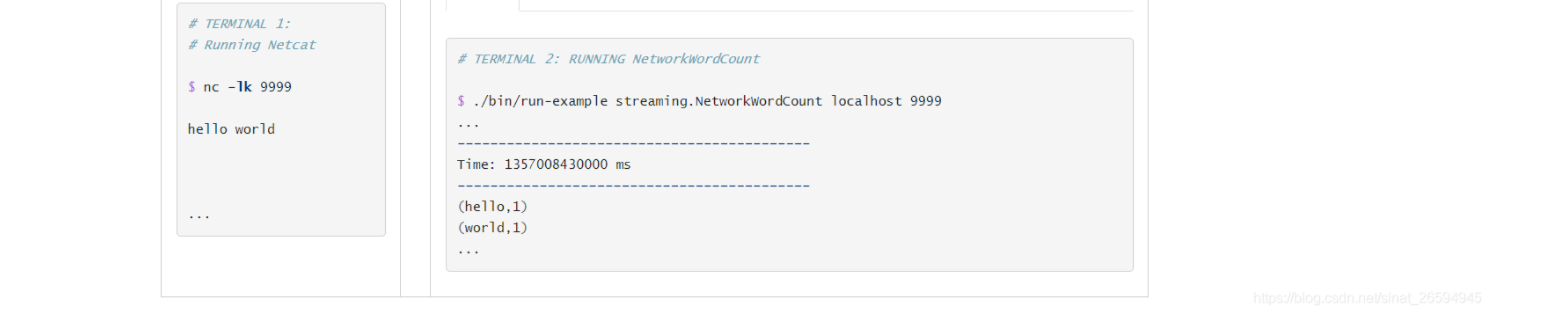
如果您已经下载并构建了 Spark,则可以按照以下方式运行此示例。首先需要使用以下命令将 Netcat (大多数类 unix 系统中的一个小实用程序)作为数据服务器运行
$ nc -lk 9999
然后,在另一个终端中,您可以使用
$ ./bin/run-example streaming.NetworkWordCount localhost 9999
然后,在运行 netcat 服务器的终端中键入的任何行都将计数并每秒钟在屏幕上打印一次。它看起来像下面这样。