转载请标明出处http://www.cnblogs.com/haozhengfei/p/82c3ef86303321055eb10f7e100eb84b.html
PIC算法 幂迭代聚类
PIC算法全称Power iteration clustering 幂迭代聚类
1.谱聚类
幂迭代聚类的前身--谱聚类,基于图论的计算方法。(可以用点来表示对象,对象之间的关系用连线表示,Neo4j 图数据库,用来做用户与用户之间的关系,它可以存两个对象之间的关系,它是半开源的单机版免费,集群版收费,它的规模不是很大,也就是几千万级别,如果数据量很大,也可以用Spark中的图计算Graphx)
2.谱聚类分割方法
相似度与权重:
将每条数据当做图中的每个点,数据与数据之间的相似度为点和点的边的权重

谱聚类的分割方法:
最优分割的原则是使子图内部边的权重之和最大,子图之间的边的权重之和最小。
距离越小,相似度越高,那么权重之和越大
– Mcut(最小割集)
– Ncut (规范割集)一般使用Ncut多一些,既考虑最小化cut边又划分平衡。避免出现很多个单点离散的图
谱聚类的实现方式和步骤_NCut规范格局(如果是Mcut采用倒数第二小的特征即为所求):
1.构建相似度矩阵(相似度矩阵可用邻接矩阵表示),指定聚类个数K;
2.利用相似度矩阵构建拉普拉斯矩阵L
3.计算标准化之后的拉普拉斯矩阵L的K个特征向量,并按照特征值升序排序
4.对由K个特征向量组成的矩阵按照每行进行Kmeans聚类
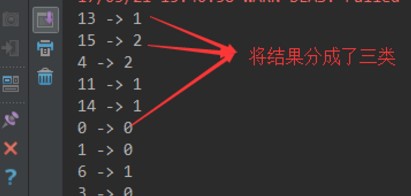
5.将聚类结果的各个簇分别打上标记,对应上原数据,输出结果
补充:
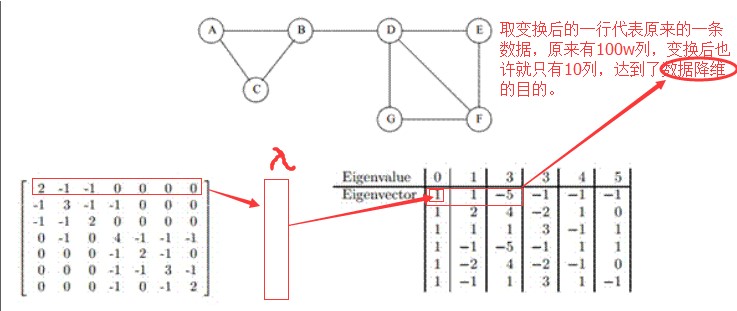
点与点之间关联的邻接矩阵
拉普拉斯矩阵 = 度矩阵 - 邻接矩阵 (度矩阵:无向图中的度指的是连接一个点的边有多少,有向图中有出入度的概念,出度和入度,可以用邻接矩阵中每一行相加求出 度矩阵)

矩阵M * 向量L = 向量L,但是如果矩阵M * 向量L = 向量L * 数值a,那么L就是M的特征向量,a就是相应的特征值。(一个矩阵不一定会有特征向量,也可能有很多的特征向量。一个特征向量会有一个特征值,二者是成对出现的)
矩阵的特征值和特征向量,矩阵中的每一行*一个特征向量相当于将矩阵中的一行映射到向量中指定的某一点,这种方式从某种角度上做到了降维。
3.PIC算法VS谱聚类
PIC和谱聚类算法类似,都是通过将数据嵌入到由相似矩阵映射出来的低维子空间中,然后直接或者通过kmean算法得到聚类结果
它们的不同点在于如何嵌入及产生低维子空间
– 谱聚类是通过拉普拉斯矩阵产生的最小向量构造的
– Pic利用数据规范化的相似度矩阵,采用截断的快速迭代法
4谱聚类code
train
PowerIterationClustering_new


1 import org.apache.log4j.{Level, Logger} 2 import org.apache.spark.rdd.RDD 3 import org.apache.spark.{SparkConf, SparkContext} 4 import org.apache.spark.mllib.clustering.PowerIterationClustering 5 6 /** 7 * Created by hzf 8 */ 9 object PowerIterationClustering_new { 10 // E:IDEA_Projectsmlibdatapic rainpic_data.txt E:IDEA_Projectsmlibdatapicmodel 3 20 local 11 def main(args: Array[String]) { 12 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR) 13 if (args.length < 5) { 14 System.err.println("Usage: PIC <inputPath> <modelPath> <K> <iterations> <master> [<AppName>]") 15 System.exit(1) 16 } 17 val appName = if (args.length > 5) args(5) else "PIC" 18 val conf = new SparkConf().setAppName(appName).setMaster(args(4)) 19 val sc = new SparkContext(conf) 20 val data: RDD[(Long, Long, Double)] = sc.textFile(args(0)).map(line => { 21 val parts = line.split(" ").map(_.toDouble) 22 (parts(0).toLong, parts(1).toLong, parts(2)) 23 }) 24 25 val pic = new PowerIterationClustering() 26 .setK(args(2).toInt) 27 .setMaxIterations(args(3).toInt) 28 val model = pic.run(data) 29 30 model.assignments.foreach { a => 31 println(s"${a.id} -> ${a.cluster}") 32 } 33 model.save(sc, args(1)) 34 } 35 }
设置运行参数
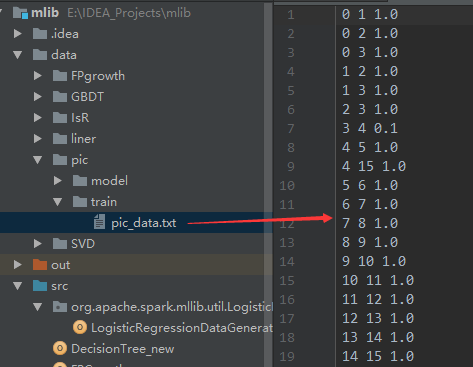
E:IDEA_Projectsmlibdatapic rainpic_data.txt E:IDEA_Projectsmlibdatapicmodel 320 local