段落1. 百度百科char
char用于C或C++中定义字符型变量,只占一个字节,取值范围为 -128 ~ +127(-2^7~2^7-1)
知识点:负数在计算机中以补码存储,而正数以原码存储。
为什么负数在计算机中以补码存储呢?
因为所以科学道理,可以看这篇知乎文章:https://www.zhihu.com/question/335614901/answer/755608419
不看也可以,只要知道负数在计算机中有用补码来存储的必要性就行了,而且这个必要性是有科学道理的。
段落2. 求正数在计算机中存储的二进制值
请问 char j = 5 这句代码中, j 在计算机中存的二进制值是多少?
正数以原码存储,5的原码是0b0000 0101. 所以 j 在计算机中存的二进制值是 0b0000 0101 。
段落3. 求负数在计算机中存储的二进制值
请问 char j = -12这句代码中, j 在计算机中存的二进制值是多少?
负数以补码存储
先找对该负数对应的正数,即12。 12 的原码是 0b0000 1100 .
我们将上述原码的最高位置为1, 得到0b1000 1100.
然后再求补码:
0b1000 1100 , 符号位不变,其余各位取反 =》0b11110011 再加1 =》得到0b11110100 。
我们最终理论计算得到0b11110100, 这等价于0xF4。
但是写代码验证的时候还是有所区别,在%s、%c、%d、%x等这些输出格式选项中,我们只能使用%x来打印出其十六进制的内存值。
而且%x会打印出4字节,并非只有1字节哦,所以,我们只需关注最低一个字节就行了。
下面是代码:
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <stdlib.h>
#include <unistd.h>
int main(){
char j = -12;
printf("%x
", j);
return 0;
}
root@lmw-virtual-machine:/home/lmw/桌面/C_Text# ./ab
fffffff4
root@lmw-virtual-machine:/home/lmw/桌面/C_Text#
可以看到,最低字节是F4。
上面提到可以先找到该负数对应的正数12, 那么12的原码可不仅仅是0b0000 1100 , 还可以是0b 0000 0000 0000 0000 0000 0000 0000 1100 (32位, 合计4字节),
相同的操作手法我们再来一遍,
我们将上述原码的最高位置为1, 得到0b1000 0000 0000 0000 0000 0000 0000 1100 .
然后再求补码:
符号位不变,其余各位取反 =》0b1111 1111 1111 1111 1111 1111 1111 0011, 再加1 =》得到 1111 1111 1111 1111 1111 1111 1111 0100 。
我们最终得到的0b1111 1111 1111 1111 1111 1111 1111 0100 则等价于 0xFFFFFF4。
0b1111 1111 1111 1111 1111 1111 1111 0100 和 0b11110100 都可以表示 -12 的计算机存储值啊 , 那什么时候是前者,什么时候是后者呢?
取决于我们希望用什么方式去访问这片内存。
如果是使用%x访问, %x一定会访问到4字节内容并以十六进制显示, 那么得到的就是4字节的0xFFFFFFF4,
对应的是4字节的0b1111 1111 1111 1111 1111 1111 1111 0100,
即使用%x访问时,12的原码应该按照4字节来分析。
段落4. 超限处理
如果赋值的数是超过char类型的上限值的,那么先减去256的倍数, 再根据上面方法计算其在计算机中存储的二进制值。

例如上图,我们要计算500赋值给char,那么只需要计算500-256=244, 发现244还是大于char的取值上限,
那么再次244-256 = -12, 发现-12 在char类型范围内,所以我们只需要计算-12在计算机中的存储值即可,
这样我们也能够可以分析出使用%x打印变量a会得到怎样的十六进制值了。
换句话说,这基于一个观点: char a = 500; 等价于 char a = -12;
段落5. 不同符号类型数做加法时
知识点:当有符号数与无符号数一起运算时,会将有符号数转换为无符号数!
下面的demo可以作为面试题使用。如果面试者只能解释到34-12=22这种地步,那么显然是非常错误的。
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <stdlib.h>
#include <unistd.h>
int main(){
char j = -12; // 0xFFFFFFF4
unsigned char x = 34; // 0xFFFFFFF4 + 0x22(十进制的34) ,得到0x1 0000 0016
printf("%x
", j+x); // 0x1 0000 0016 超过了4字节了,截断得到 0x00000016, 即0x16
unsigned int sum = j+x;
printf("sum = %d
", sum); // 0x16,即 22
return 0;
}
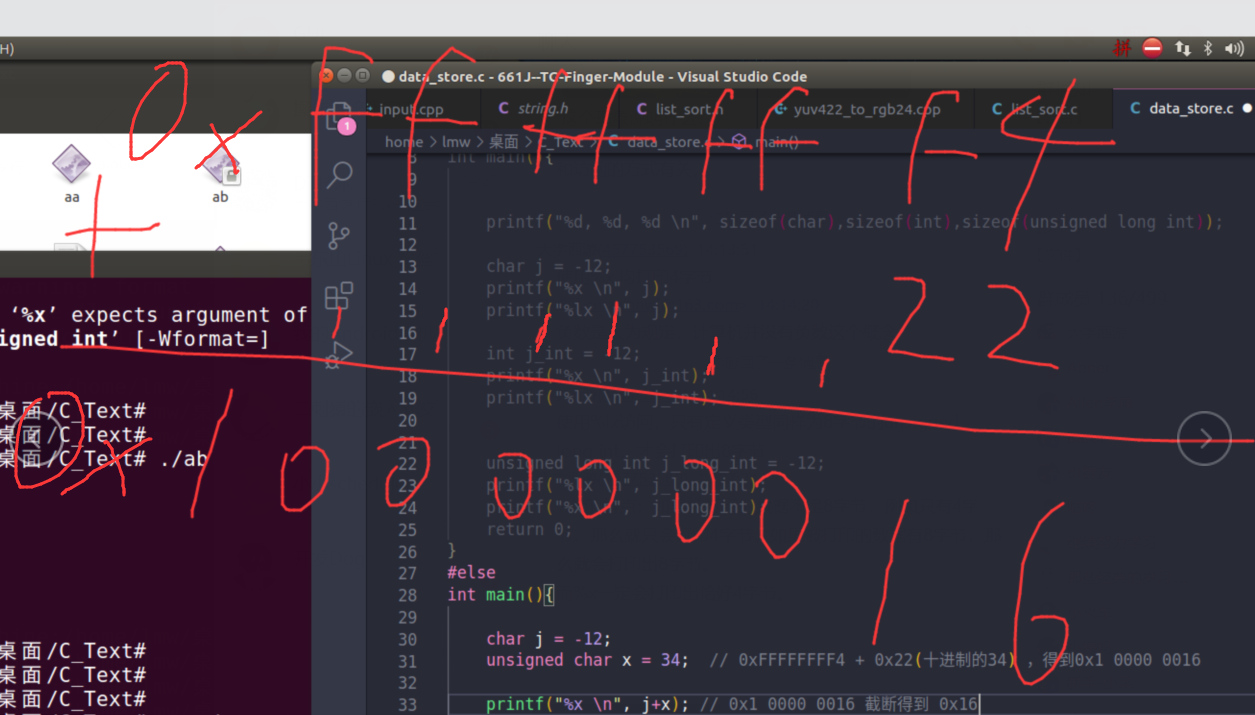
补充点:
补充一个%x 和 %lx的实验
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <stdlib.h>
#include <unistd.h>
int main(){
printf("%d, %d, %d
", sizeof(char),sizeof(int),sizeof(unsigned long int));
char j = -12;
printf("%x
", j);
printf("%lx
", j);
int j_int = -12;
printf("%x
", j_int);
printf("%lx
", j_int);
unsigned long int j_long_int = -12;
printf("%lx
", j_long_int);
printf("%x
", j_long_int);
return 0;
}
root@lmw-virtual-machine:/home/lmw/桌面/C_Text# ./ab
1, 4, 8
fffffff4
fffffff4
fffffff4
fffffff4
fffffffffffffff4
fffffff4
root@lmw-virtual-machine:/home/lmw/桌面/C_Text#
结论:
%lx的特点:如果被打印的数据不足8字节,例如只有4字节或1字节,那么就只会打印4字节。如果被打印的数据有8字节,那么就会打印出8字节。
而%x一定会打印出恰好刚好4字节。
.