简述:redis 单实例,单进程,当线程处理用户请求数据,基于内存对数据处理。Redis默认分为0-16号库,每个库互相隔离(数据不共享)
基础复习:
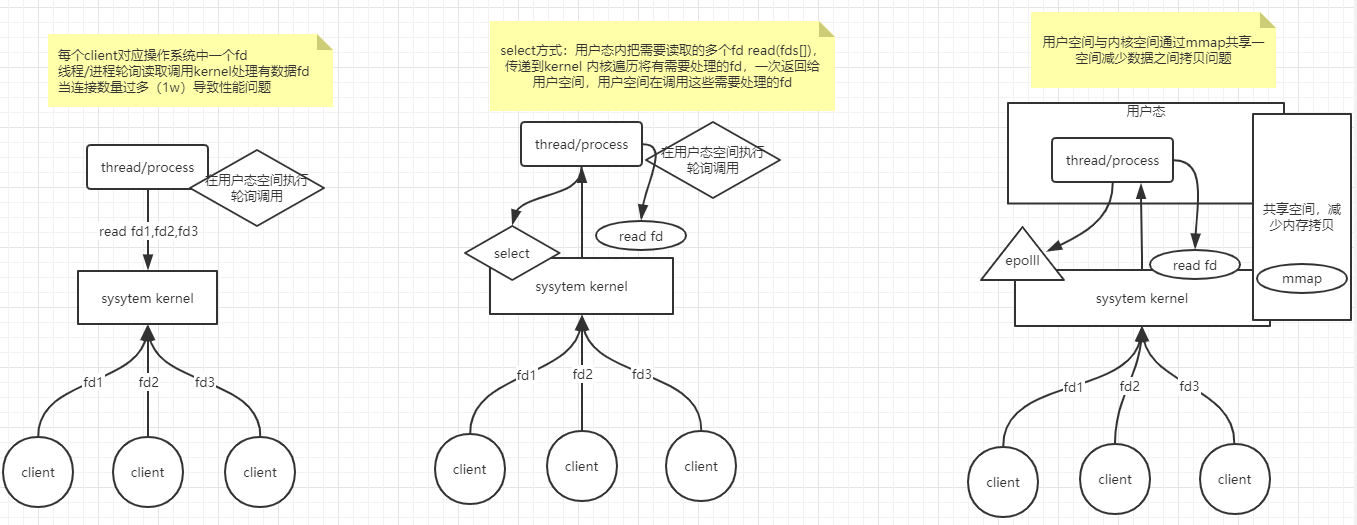
1,系统中的每个进程对应有一个fd,通过网卡连接系统的每个连接会产生一个fd
2,一个进程会有自己内存工作空间称之为用户空间,kernel工作空间称为内核空间,进程和kernel交互会发生内存拷贝
系统内核Nio处理的发展历程:
Redis快速原因:
1,基于内存,避免了磁盘IO性能影响
2,使用kernel epoll机制,减少内核态用户态之间频繁调用
3,单线程“顺序”处理client请求避免多线程锁的问题
Redis Value Type:
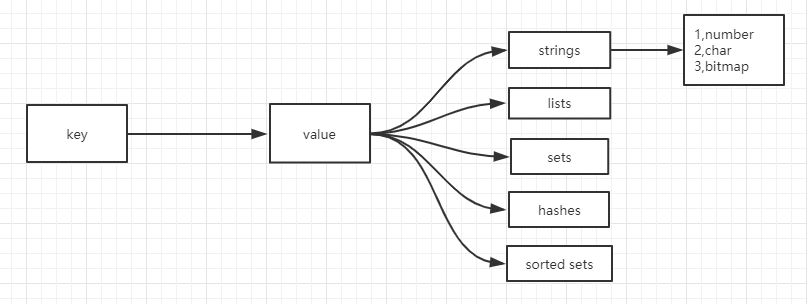
Strings,基本操作 set ,get,append,strlen,setrange,getrange
(1)set k1 val1 [nx/xx] //nx不存在才能创建,已存在则失败 ,xx已存在才更新value
(2)string包含数值类,可以对数值类value进行直接操作 incr k (+1),incrby k 50(+50) decr k2(-1) decrby 3(-3)
(3)mset k1 v1 k2 v2 //批量创建 mget k1 k2 //批量获取
(4)expire k1 5 //设置key有效时间5s set k1 20 ex 5 //创建时指定key的时间 ttl k1 //查询k1剩余时间
(5)getrange k1 2 5 //取出索引2-5的内容 setrange k1 5 tatata //指定索引范围设置内容
bitmap: setbit k1 [position] [bitvalue]
bitpos k1 [bitvalue] [start][end]//在指定字符范围查找,bitvalue首次出现位置
bitcount k1 [start][end]//在指定字符范围查找1 count
案例:一,统计用户登录400bit,1bit 1day
setbit k1 [day], 1 count k1
二,统计活跃用户(去重处理)日期key,按位或计算处理
set 20190101 1 1 , set 20190101 7 1 ,set 20190102 1 1
bitop or destkey 20190101 20190103
bitcount destkey 0 -1
Lists,基本操作 rpush, lpush,lrange,rpop,可作为栈,队列,数组,阻塞/插队
(1)rpush k1 a,b,c lpush first //左边为head,右边为tail,(first a b c)
(2)lrange k1 0 -1 //正序输出 rrange //倒序输出
(3)ltrim k1 [start] [end] //保留前N条数据,剔除老数据
(4)brpop k1 [seconds]//阻塞提取元素,0为一只等待,其它超时返回
Hashes,基本操作 hmset hmget hget hincby,用于点赞,收藏,详情
(1)hmset person:100 name tom sex man birth 1998-01-01
(2)hget person:100 name//获取单一属性值 hgetall //获取全部属性名和值
hmget person:100 name sex birth //只获取属性值
Sets, 无序唯一,随机,用于抽奖,打标签
(1)sadd k1 v1 v2 v3 //添加元素 smembers k1//查询元素 sismember k1元素是否存在
(2)sinterstore kdest k1 k2 //存储交集结果,减少io输出(sinte会产生IO结果输出)
sunionrestore //并集合结果存储
srandmember //整数,取出去重结果(范围内)负数,重复结果集满足数量
Sorted set,唯一且按score排序 如:a.score>b.score 则 a>b 若score相同则按key的字典序处理
常用操作,
zadd k1 score v1 //添加 zrange k1 0 -1//正序 zrevrange k1//倒序
zrange k1 0 -1 withscores//带score值输出
zrangebyscore k1 //筛选匹配区间元素
zremrangebyscore k1 [start score][end score]//移除区间内的元素
索引:redis支持正向索引与反向索引,反向-1表示最后,-2表示最后一位-1
redis过期判定:
1,被动判定:当过期key达到过期后暂不清理,client下次访问这key在处理
2,主动判定:每隔一段时间随机抽取20,发现已过期key删除,如此次已过期的key超过样本量的25%,则继续重新随机,查找,删除,直到样本内过期key低于25%
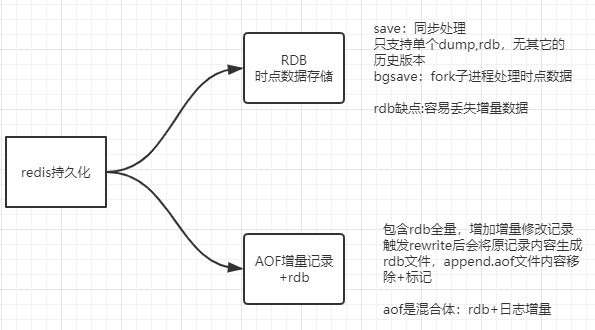
redis持久化:
linux fork机制,父进程,子进程
Redis之穿透,雪崩:
发生前提:发生了大量并发请求
击穿问题:如果大量请求key不在业务范围内且绕过service和Redis到达db,导致db引起压力的问题
雪崩问题:大量的key同时过期或不存在cache,导致请求全部打到db,,导致db引起压力的问题
解决方法:
击穿的解决:增加布隆过滤器,无效的key拦截掉
雪崩的解决:
Redis集群模式:
AKF拆分原则:
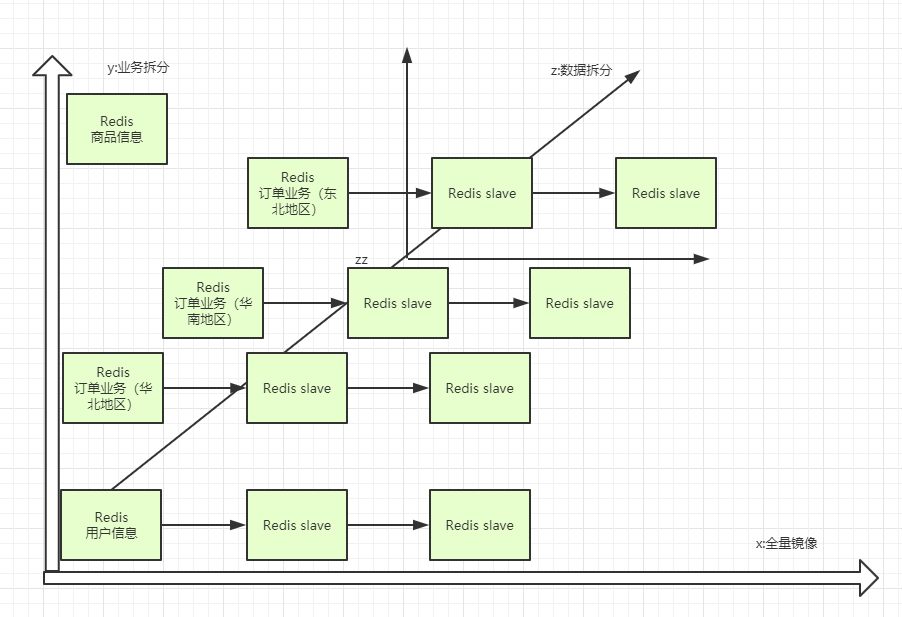
集群模式:
1,主从复制:(master-slave model)
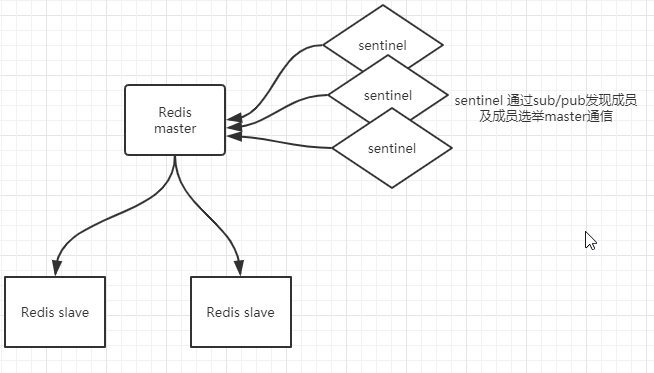
集群中容量问题:当数据业务无法拆分或大一业务数据量过多会导致redis扩容问题
解决方案:
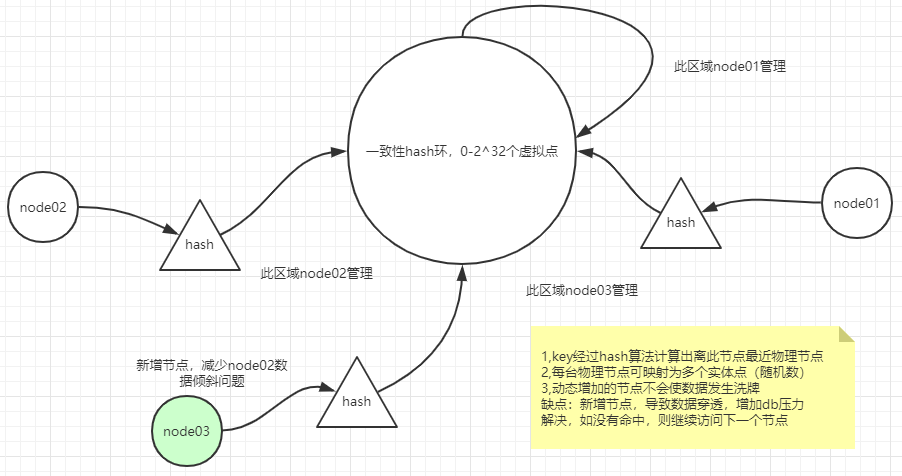
(1)哈希取模,缺点:模数值固定影响扩展
(2)一致性哈希,环形hash,虚拟节点,解决数据倾斜
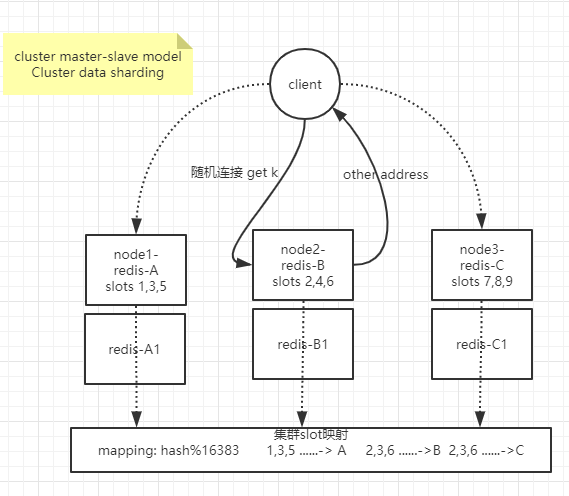
2,无主模型(分片):
(1)data slot:通过hash算法将数据分散到集群中的每个节点上,即数据分制
(2)client随机连接Redis节点,若key在此节点则处理,如果slot在其它节点则redirect到slot节点地址去处理
(3)如集群中某个节点负责的slots无法提供服务则导致整个集群无法对外服务,所以备份节点需要多台
 Redis 延迟问题:
Redis 延迟问题:
不合理使用命令和数据结构:
当数据量达到一定级别时,某些命令的执行就会花费大量时间,比如对一个包含上万个元素的 hash 结构执行 hgetall 操作。对于键值较多的 hash 结构可以使用 scan 系列命令来逐步遍历,而不是直接使用 hgetall 来全部获取。
建议对于键值较多的 hash 结构可以使用 scan 系列命令来逐步遍历,而不是直接使用 hgetall 来全部获取。发现大对象,redis-cli -h {ip} -p {port} --bigkeys 持续采样,实时输出当时得到的 value 占用空间最大的 key 值
持久化阻塞:当我们开启AOF持久化功能时,文件刷盘的方式一般采用每秒一次,后台线程每秒对AOF文件做 fsync 操作。当硬盘压力过大时,fsync 操作需要等待,直到写入完成