spark批处理模式:
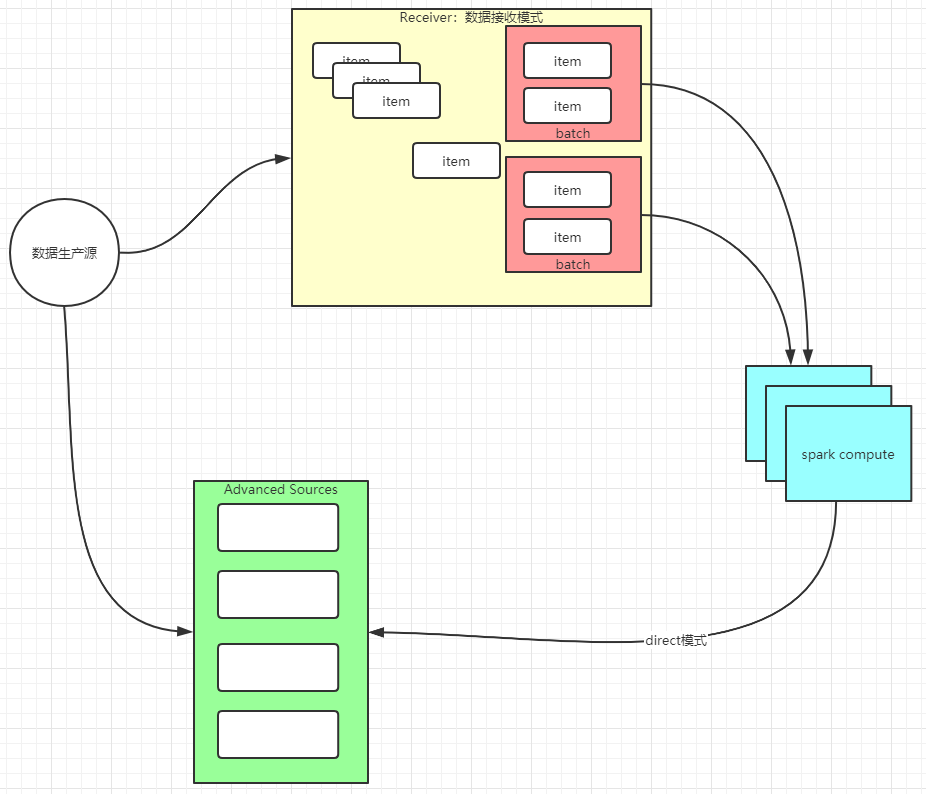
receiver模式:接收数据流,负责数据的存储维护,缺点:数据维护复杂(可靠性,数据积压等),占用计算资源(core,memory被挤占)
direct模式:数据源由三方组件完成,spark只负责数据拉取计算,充分利用资源计算
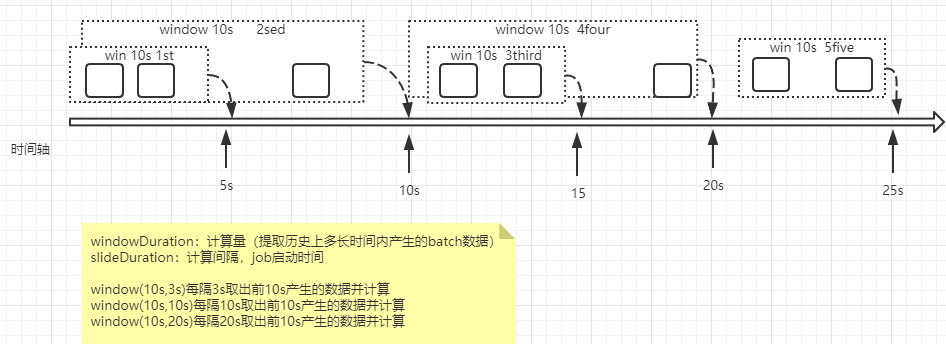
window计算:
def windowApi(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("sparkstream").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Duration(1000))
ssc.sparkContext.setLogLevel("ERROR")
val resource: ReceiverInputDStream[String] = ssc.socketTextStream("localhost",8889)
val format: DStream[(String, Int)] = resource.map(_.split(" ")).map(x=>(x(0),1))
//统计每次看到的10s的历史记录
//windowDuration窗口一次最多批次量,slideDuration滑动间隔(job启动间隔),最好等于winduration
val res: DStream[(String, Int)] = format.reduceByKeyAndWindow(_+_,Duration(10000),Duration(1000))//每一秒计算最后10s内的数据
res.print()
ssc.start()
ssc.awaitTermination()
}
window处理流程:
执行流程:
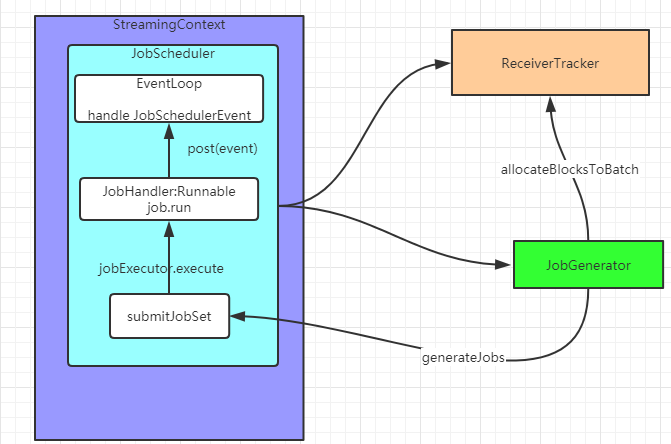
说明:Receiver模式下,接收器创建数据块,每间隔blockInterval 时间产生新的数据块,块的个数N = batchInterval/blockInterval。这些数据块由当前executor的BlockManager发送到其它executor的BlockManager,driver追踪块的位置为下一步计算准备
1,JobScheduler通过EventLoop消息处理机制处理job事件(jobStart,jobCompletion,jobError对job进行标记)使用ThreadPoolExecutor为每个job维护一个thread执行job.run
2,JobGenerator负责job生成,执行checkpoint,清理DStream产生的元数据,触发receiverTracker为下一批次数据建立block块的标记
stream合并与转换:
每个DStream对应一种处理,对于数据源有多种特征需要多个DStream分别处理,最后将结果在一起处理,val joinedStream = windowedStream1.join(windowedStream2)
val conf: SparkConf = new SparkConf().setAppName("sparkstream").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Duration(1000))
ssc.sparkContext.setLogLevel("ERROR")
val resource: ReceiverInputDStream[String] = ssc.socketTextStream("localhost",8889)
val format: DStream[(String, Int)] = resource.map(_.split(" ")).map(x=>(x(0),1))
//transform 加工转换处理
val res: DStream[(String, Int)] = format.transform( //返回值是RDD
(rdd ) =>{
val rddres: RDD[(String, Int)] = rdd.map(x => (x._1, x._2 * 10))//做转换
rddres
}
)
//末端处理
format.foreachRDD( //StreamingContext 有一个独立的线程执行while(true)下面的代码是放到执行线程去执行
(rdd)=>{
rdd.foreachPartition { partitionOfRecords =>
// val connection = createNewConnection()
// to redis or mysql
// partitionOfRecords.foreach(record => connection.send(record))
// connection.close()
}
}
)
Caching / Persistence
在使用window统计时(reduceByWindow ,reduceByKeyAndWindow,updateStateByKey)Dstream会自动调用persist将结果缓存到内存(data serialized)
Checkpointing 保存两种类型数据存储
Metadata:driver端需要的数据
Configuration: application配置信息conf
DStream operations: 定义的Dstream操作集合
Incomplete batches:在队列内还没计算完成的bactch数据
Data checkpointing:已经计算完成的状态数据
设置checkpoint
val ssc = new StreamingContext(...) ssc.checkpoint(checkpointDirectory) dstream.checkpoint(checkpointInterval). ...... // Get StreamingContext from checkpoint data or create a new one val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _) context.
checkpoint依赖外存储,随着batch处理间隔的变短,会使吞吐量显著降低,因此存储间隔要合理设置,系统默认最少10s调用一次,官方建议5s-10s