一 栈的简介
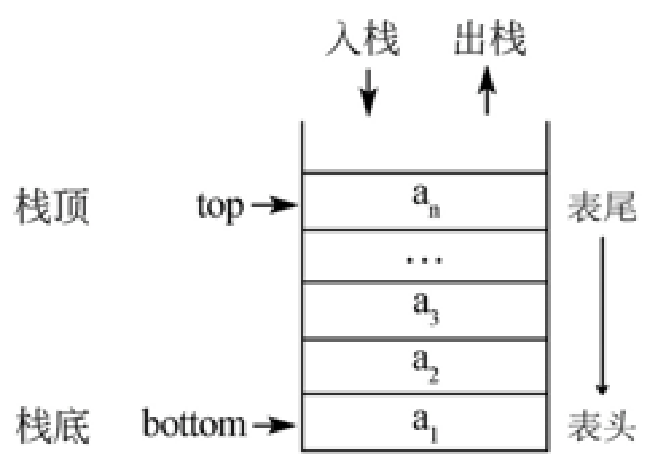
栈是一个数据集合,可以理解为只能在一段进行插入或删除操作的列表
栈的特点:后进先出
栈的概念:栈顶,栈底
栈的操作:
- 进栈(压栈):push
- 出栈:pop
- 取栈顶:gettop
使用一般的列表结构可实现栈
- 进栈: li.append
- 出栈: li.pop
- 取栈顶: li[-1]
Python代码实现栈:
class stack: def __init__(self): self.stack = [] def push(self, element): self.stack.append(element) def pop(self): return self.stack.pop() def get_top(self): if len(self.stack) > 0: return self.stack[-1] else: return None def is_empty(self): return len(self.stack) == 0 sta = stack() sta.stack = [1, 2] sta.push(5) print(sta.pop()) print(sta.pop()) print(sta.pop()) print(sta.is_empty())
二 栈的应用示例 —— 括号匹配问题
括号匹配问题: 给一个字符串,其中包括小括号,中括号,大括号,求该字符串中的括号是否匹配
例如:
- ()()[]{} 匹配
- ([{()}]) 匹配
- []( 不匹配
- [(]) 不匹配
def brace_match(s): match = {'}': '{', ']': '[', ')': '('} stack = Stack() for ch in s: if ch in {'(', '[', '{'}: stack.push(ch) else: if stack.is_empty(): return False elif stack.get_top() == match[ch]: stack.pop() else: # stack.get_top() != match[ch] return False return '匹配成功' print(brace_match(["{", "(", ")", "}"]))
三 队列的简介
- 队列是一个数据集合,仅允许在列表的一端进行插入,另一端进行删除,
- 进行插入的一端称为队尾(rear),插入动作称之为进队或入队
- 进行删除的一端称之为对头(front),删除动作称为出队
- 队列的性质:先进先出
双向队列:对列的两端都允许进行进队和出队操作
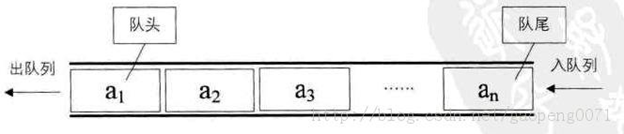
队列的实现
队列能否简单用列表实现?为什么?
- 初步设想:列表+两个下标指针
- 创建一个列表和两个变量,front变量指向队首,rear变量指向队尾。初始时,front和rear都为0。
- 进队操作:元素写到li[rear]的位置,rear自增1。
- 出队操作:返回li[front]的元素,front自减1。
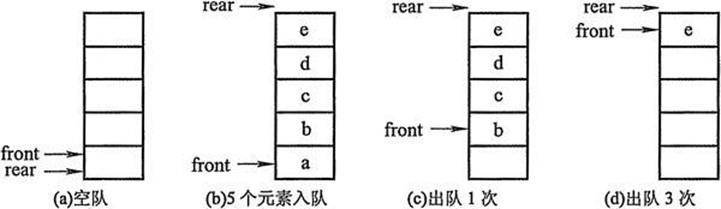
队列的实现原理-----环形对列
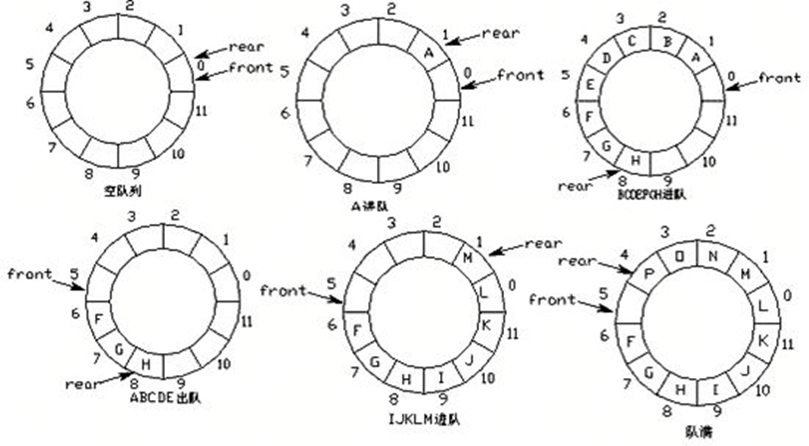
环形队列:当队尾指针front == Maxsize + 1时,再前进一个位置就自动到0。
- 实现方式:求余数运算
- 队首指针前进1:front = (front + 1) % MaxSize
- 队尾指针前进1:rear = (rear + 1) % MaxSize
- 队空条件:rear == front
队列实现代码
class Queue: def __init__(self, size=100): self.queue = [0 for _ in range(size)] self.rear = 0 # 队尾指针 self.front = 0 # 队首指针 self.size = size def push(self, element): if not self.is_filled(): self.rear = (self.rear + 1) % self.size self.queue[self.rear] = element else: raise IndexError('Queue is filled') def pop(self): if not self.is_empty(): self.front = (self.front + 1) % self.size return self.queue[self.front] else: raise IndexError("Queue is empty") # 判断队列是否是空的 def is_empty(self): return self.rear == self.front # 判断队满 def is_filled(self): return (self.rear+1) % self.size == self.front q = Queue(5) for i in range(4): q.push(i) print(q.is_filled()) print(q.pop()) q.push(5) print(q.pop()) print(q.pop()) print(q.pop()) print(q.pop())
对列的内置模块
from collections import deque queue = deque()#创建队列 queue.append('first') queue.append('second') queue.append('third') print(queue.popleft()) print(queue.popleft()) print(queue.popleft())#出队,,先进先出 print([i for i in queue]) #查看队列里的元素 queue.appendleft('one')#双向队列队首进队 queue.appendleft('two')#双向队列队首进队 queue.appendleft('five')#双向队列队首进队 print(queue.pop()) print(queue.pop())#双向队列从队尾出队 print([i for i in queue]) #单向队列 from queue import Queue q = Queue() q.put('a') q.put('b') q.put('c') print(q.get()) #a
四 栈和队列的应用----- 迷宫问题
给一个二维列表, 表示迷宫(0表示通道,1表示围墙)。给出算法,求一条走出迷宫的路径
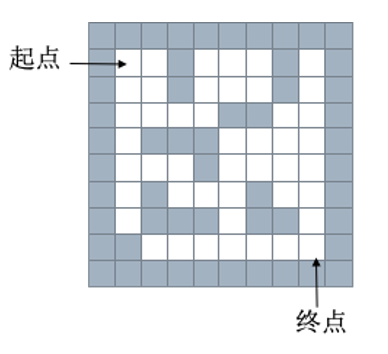
maze = [ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 1, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 0, 0, 0, 1], [1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 1, 0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 1, 1, 0, 1], [1, 1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1] ]
1 栈实现回溯法(深度优先)
思路:从一个节点开始,任意找下一个能走的点,当找不到能走的点时,退回上一个点寻找是否有其他方向的点
使用栈存储当前路径
maze = [ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 1, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 0, 0, 0, 1], [1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 1, 0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 1, 1, 0, 1], [1, 1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1] ] # 四个方向坐标 上x-1,y; 下x+1,y; 左:x, y-1; 右 x,y+1 dirs = [ lambda x, y: (x + 1, y), lambda x, y: (x - 1, y), lambda x, y: (x, y - 1), lambda x, y: (x, y + 1) ] def maze_path(x1, y1, x2, y2): stack = [] stack.append((x1, y1)) while (len(stack) > 0): curNode = stack[-1] # 当前位置 if curNode[0] == x2 and curNode[1] == y2: # 走到终点了: for p in stack: print(p) return True # 四个方向坐标 上x-1,y; 下x+1,y; 左:x, y-1; 右 x,y+1 for dir in dirs: nextNode = dir(curNode[0], curNode[1]) # 下一个节点 # 如果下一个节点能走 if maze[nextNode[0]][nextNode[1]] == 0: stack.append(nextNode) maze[nextNode[0]][nextNode[1]] = 2 # 2表示这个玩位置已经走过 break else: maze[nextNode[0]][nextNode[1]] = 2 stack.pop() else: print('没有出路') return False maze_path(1, 1, 8, 8)
2 队列实现广度搜索
思路:
- 从一个节点开始,寻找所有接下来能继续走的点,继续不断寻找,直到找到出口
- 使用队列存储当前正在考虑的节点
maze = [ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 1, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 0, 0, 0, 1], [1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 1, 0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 1, 1, 0, 1], [1, 1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1] ] dirs = [ lambda x, y: (x + 1, y), lambda x, y: (x - 1, y), lambda x, y: (x, y - 1), lambda x, y: (x, y + 1) ] from collections import deque def print_r(path): real_path = [] # 出去的路径 i = len(path) - 1 # 最后一个节点 print(path) print(i) while i >= 0: # 判断最后一个节点的标记是否为-1,如果是-1说明是起始点,如果不是-1就继续查找 real_path.append(path[i][0:2]) # 拿到并添加节点x,y坐标信息 i = path[i][2] # 这里i[2]是当前节点的前一步节点的标识:path的下标,因此path[i[2]]拿到前一节点 real_path.reverse() # 将列表倒序,将前面生成的从后往前的列表变为从前往后 for node in real_path: print(node) def maze_path_queue(x1, y1, x2, y2): queue = deque() path = [] queue.append((x1, y1, -1)) while len(queue) > 0: # 当队列不空时循环 cur_node = queue.popleft() # 当前节点 path.append(cur_node) if cur_node[0] == x2 and cur_node[1] == y2: # 到达终点 print_r(path) return True for dir in dirs: next_node = dir(cur_node[0], cur_node[1]) # curNode[0],curNode[1]分别是当前节点x、y if maze[next_node[0]][next_node[1]] == 0: # 如果有路可走 queue.append((next_node[0], next_node[1], len(path) - 1)) # 后续节点进队,标记谁让它来的:path最后一个元素的下标 maze[next_node[0]][next_node[1]] = 2 # 设置为2,标记为已经走过 return False maze_path_queue(1, 1, 8, 8)