本文旨在将迁移学习训练好的模型基于tensorflow工具进行量化。
环境配置及迁移学习部分可参考博文[https://www.cnblogs.com/hayley111/p/12887853.html]。
- 首先使用如下workflow理解模型部署的过程,本文主要描述的是quant这一步。
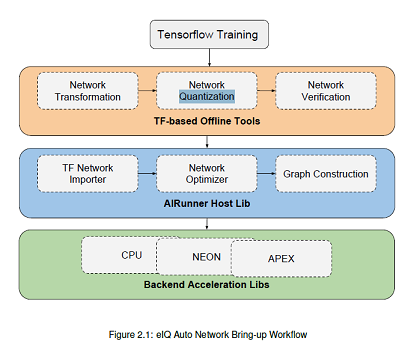
1. 环境准备:
安装bazel
bazel是一个开源的构造和测试工具,在EIQ中指定用tf配套版本的bazel进行构建。参照如下官方指导链接
[https://docs.bazel.build/versions/3.2.0/install-ubuntu.html#step-1-add-bazel-distribution-uri-as-a-package-source]
注意这里使用oracle的JDK,在官方指南中安装open JDK的部分替换参考如下博文安装oracle JDK:
[https://www.cnblogs.com/hayley111/p/13024148.html]
安装完毕后使用我们将使用bazel对已完成训练的模型进行构建。
在tensorflow文件夹下执行
bazel build tensorflow/python/tools:freeze_graph
出现以下信息表示bazel-bin编译成功:

2.使用transform_graph tool,对模型量化参数进行配置:
使用bazel对已完成训练的model进行配置,参考EIQ指南:
bazel build tensorflow/tools/graph_transforms:transform_graph
这一步可能会需要几分钟,出现如下表示信息表示成功:

接下来对input和output参数进行配置,参考指南,路径设置为自己存放model的路径:
bazel-bin/tensorflow/tools/graph_transforms/transform_graph
--in_graph="frozen_inference_graph.pb"
--out_graph="frozen_inference_graph_ssd_part.pb"
--inputs="Preprocessor/sub"
--outputs="concat,concat_1"
--transforms='strip_unused_nodes(type=float, shape="1,300,300,3") remove_nodes(op=Identity,op=CheckNumerics) fold_constants(ignore_errors=true)'
出现以下信息表示配置完成:

3.使用tf toco对模型量化进行优化配置:
这里使用tensorflow lite工具,相关材料详见tf官网.
注意The toco target has been moved from //tensorflow/contrib/lite/toco to //tensorflow/lite/toco, 根据tf版本确认好你的toco文件夹位置。
bazel build tensorflow/lite/toco:toco
bazel run -c opt //tensorflow/lite/toco:toco --
--input_file=$/mnt/d/tensorflow-1.14.0/frozen_inference_graph_ssd_part.pb
--input_format=TENSORFLOW_GRAPHDEF
--output_format=TENSORFLOW_GRAPHDEF
--output_file=frozen_inference_graph_ssd_part_float.pb
--input_arrays=Preprocessor/sub
--output_arrays=concat,concat_1
--drop_control_dependency
执行成功出现以下信息:
4.最后使用eiq的脚本完成模型的量化。
首先完成环境配置:
export PYTHONPATH=$PYTHONPATH:/your/path/to/s32v234_sdk/tools
将以上步骤中得到的frozen_inference_graph.pb和frozen_inference_graph_ssd_part_float.pb放入对应的文件夹中:
cp frozen_inference_graph.pb your_path/s32v234_sdk/tools/eiq_auto_data/models/tf/mssdv2deployment
EIQ已经写好了量化的py脚本。按照eIQ Auto User Guide P12中的脚本进行量化:
cd eiq_auto_data/models/tf/mssdv2/workspace
python quantize_graph.py
执行成功返回如下信息:

回到eiq_auto_data/models/tf/mssdv2/deployment下能够看到量化的模型已经生成:

实际上NXP根据自己的芯片特性,使用tf的lite工具完成了量化脚本的编写(即本步用到的quantize_graph)。
下面看看这个脚本都做了哪些工作:
import os
import copy
import math
import numpy as np
from eiq_auto.analyze import runner
import tensorflow as tf
from .quantize import Quantize, minmax_scale, MIN_SUFFIX, MAX_SUFFIX
from tensorflow.core.framework import attr_value_pb2
from tensorflow.core.framework import graph_pb2
from tensorflow.core.framework import node_def_pb2
from tensorflow.python.framework import dtypes
from tensorflow.python.framework import tensor_util
from abc import ABC, abstractmethod
OPS = ['Conv2D', 'DepthwiseConv2dNative', 'Relu6', 'BiasAdd', 'Relu', 'FusedBatchNorm', 'Add', 'MaxPool', 'AvgPool','BatchNormWithGlobalNormalization', 'MatMul', 'Conv2DBackpropInput', 'Mul']
def create_node(op, name, inputs):
new_node = node_def_pb2.NodeDef()
new_node.op = op
new_node.name = name
for input_name in inputs:
new_node.input.extend([input_name])
return new_node
def create_constant_node(name, value, dtype, shape=None):
node = create_node("Const", name, [])
set_attr_dtype(node, "dtype", dtype)
set_attr_tensor(node, "value", value, dtype, shape)
return node
def set_attr_bool(node, key, value):
try:
node.attr[key].CopyFrom(attr_value_pb2.AttrValue(b=value))
except KeyError:
pass
def set_attr_int(node, key, value):
try:
node.attr[key].CopyFrom(attr_value_pb2.AttrValue(i=value))
except KeyError:
pass
def set_attr_tensor(node, key, value, dtype, shape=None):
try:
node.attr[key].CopyFrom(
attr_value_pb2.AttrValue(tensor=tensor_util.make_tensor_proto(
value, dtype=dtype, shape=shape)))
except KeyError:
pass
def set_attr_dtype(node, key, value):
try:
node.attr[key].CopyFrom(
attr_value_pb2.AttrValue(type=value.as_datatype_enum))
except KeyError:
pass
class TfNodeQuantize(ABC):
@abstractmethod
def match(self, node):
pass
@abstractmethod
def get_minmax(self, node, graph, graph_def):
pass
class TfConcatQuantize(TfNodeQuantize):
def match(self, node):
if node.op == 'ConcatV2':
return True
return False
def get_minmax(self, node, graph, graph_def):
res = []
op = graph.get_operation_by_name(node.name)
for input_tensor in op.inputs:
if input_tensor.op.type == 'Const' and 'axis' not in input_tensor.op.name:
const_node = next((n for n in graph_def.node if n.name == input_tensor.op.name), None)
res.append((const_node, -1, 0))
return res
class TfBoxPredictorQuantize(TfNodeQuantize):
def match(self, node):
if 'BoxPredictor' in node.name and node.op in OPS:
return True
return False
def get_minmax(self, node, graph, graph_def):
res = []
res.append((node, 0, 16))
return res
CustomNodeQuantize = []
CustomNodeQuantize.append(TfConcatQuantize())
CustomNodeQuantize.append(TfBoxPredictorQuantize())
class TfQuantize(Quantize):
def __init__(self, model_file):
super(TfQuantize, self).__init__(model_file)
def annotate_minmax(self, input_data, **kwargs):
helper_graph = runner.make_res_gen(self.model_file)
graph_def = helper_graph.get_runner().graph_def
graph = helper_graph.get_runner().graph
# nodes to be monitored
probe_points = []
tempBN = None
for node in graph_def.node:
if node.op in OPS:
#add fake quant node after fusedbatchnorm if there is no relu that follows
if node.op == "FusedBatchNorm":
tempBN = node
continue
if tempBN != None and node.op != "Relu" and node.op != "Relu6":
probe_points.append(tempBN.name)
if node.op == "Relu" or node.op == "Relu6":
tempBN = None
probe_points.append(node.name)
helper_graph.set_intermediate_result_probes(probe_points)
# run inference
raw_results = helper_graph.run(input_data, **kwargs)
# create new model adding FakeQuant nodes
self.output_graph_def = graph_pb2.GraphDef()
node_added = []
for node in graph_def.node:
# special cases
for c in CustomNodeQuantize:
if c.match(node):
for tup in c.get_minmax(node, graph, graph_def):
node_added.append(tup[0].name)
self._create_quant_node(*tup)
# default case
if node.name in probe_points and node.name not in node_added:
node_added.append(node.name)
calc_result = raw_results[helper_graph.get_output_names().index(node.name + ':0')]
min_value = np.min(calc_result)
max_value = np.max(calc_result)
self._create_quant_node(node, min_value, max_value)
for node in graph_def.node:
if node.name not in node_added:
output_node = node_def_pb2.NodeDef()
output_node.CopyFrom(node)
self.output_graph_def.node.extend([output_node])
# return original output results
return raw_results[:1]
def _create_quant_node(self, node, min_value, max_value):
original_node = node_def_pb2.NodeDef()
original_node.CopyFrom(node)
original_node.name = node.name + "_original"
min_name = node.name + MIN_SUFFIX
max_name = node.name + MAX_SUFFIX
min_value, max_value = minmax_scale(min_value, max_value)
amplitude = max(abs(min_value), abs(max_value))
amplitude = pow(2, math.ceil(math.log(amplitude, 2)))
min_value = -amplitude
max_value = amplitude-1
if 'dtype' in node.attr:
datatype = dtypes.as_dtype(node.attr["dtype"].type)
else:
datatype = dtypes.as_dtype(node.attr["T"].type)
min_const_node = create_constant_node(min_name, min_value, datatype, None)
max_const_node = create_constant_node(max_name, max_value, datatype, None)
# Add a downsteam node to attach min/max quant information.
downstream_node = create_node("FakeQuantWithMinMaxVars", node.name, [
original_node.name, min_const_node.name,
max_const_node.name ])
set_attr_int(downstream_node, "num_bits", 8)
set_attr_bool(downstream_node, "narrow_range", False)
self.output_graph_def.node.extend([original_node, min_const_node, max_const_node, downstream_node])
def export_model(self, dir_path = os.curdir, basename = None):
if not os.path.isdir(dir_path):
print(dir_path + " does not exist!\n")
dir_path = os.curdir
if basename == None:
basename = basename
model_path = dir_path + os.sep + basename + "_quant.pb"
with tf.gfile.GFile(model_path, "wb") as f:
f.write(self.output_graph_def.SerializeToString())
print("Model exported: " + model_path)