调试Spark应用性能的时候,首先应该理解spark是如何工作以及你的spark应用需要何种类型的资源。比如说,机器学习相关的spark应用更依赖cpu计算能力,ETL应用更依赖I/O能力,以此进行有针对的优化和配置。
硬件配置
正确的硬件配置要根据实际的情况来看。可以从以下几个方面来考虑:
- 存储系统 由于Spark作业一般都需要从外部存储系统里面读入数据,所以一个重要的原则就是就近计算。直接在HDFS的集群上运行Spark应用,并将Spark应用提交给YARN。实在不行的话,也要保持和HDFS集群在同一个局域网内。对于目标数据存储在HBase这样的低延迟介质中,那么为了避免干扰,最好在不同于HBase集群的节点上进行Spark计算。
- 本地磁盘 虽然Spark可以在内存中执行大量计算,但它仍然使用本地磁盘来存储不适合RAM的数据,并且会保留计算阶段间的中间数据。所以我们建议每个节点4-8个硬盘,不需要组RAID。在Linux操作系统中,以noatiome的选项挂载这些磁盘,同时把这些磁盘目录配置到spark.local.dir属性(和HDFS集群相同)
- 内存 Spark应用运行的每台机器的最低内存要求是8GB,当然越高越好。另外,建议最多将每台机器总内存的75%分配给Spark应用,剩余部分留给系统操作和缓存区缓存。每个Spark应用会消耗不同的内存,为了准确知道一个应用需要多少内存,可以加载一部分数据到Spark RDD中,然后在Spark的监控页面中页面
http: //<driver-node>:4040查看内存大小。 - 网络 当数据在内存当中的时候,很多Spark应用都是和网络绑定,所以保证一个至少10GB带宽的网络是很有必要的。同样,可以在Spark的监控页
http: //<driver-node>:4040中查看有多少数据通过网络来进行Spark shuffle的操作。 - Cpu核心 至少保证每台机器8-16个核心,根据应用的情况,适当增加cpu核心。
submit 参数详解
Executor的内存分为3块:
第一块:用于task执行代码,默认占executor总内存的20%
第二块:task通过shuffle过程拉取上一个stage的task的输出后,进行聚合等操作时使用,默认也是占20%
第三块:让RDD持久化时使用,默认占executor总内存的60%
Task的执行速度和每个executor进程的CPU Core数量有直接关系,一个CPU Core同一时间只能执行一个线程,每个executor进程上分配到的多个task,都是以task一条线程的方式,多线程并发运行的。如果CPU Core数量比较充足,而且分配到的task数量比较合理,那么可以比较快速和高效地执行完这些task线程。具体参数如下:
- num-executors:该作业总共需要多少executor进程执行,每个作业运行一般设置5-~100个左右较合适。
- executor-memory:设置每个executor进程的内存,设置4G~8G较合适。 num-executors* num-executors代表作业申请的总内存量(尽量不要超过最大总内存的1/3~1/2)
- executor-cores:每个executor进程的CPU Core数量,该参数决定每个
executor进程并行执行task线程的能力,设置2~4个较合适。num-executors* executor-cores代表作业申请总CPU core数(不要超过总CPU Core的 1/3~1/2 ) - driver-memory:设置Driver进程的内存。通常不用设置,一般1G就够了,若出现使用collect算子将RDD数据全部拉取到Driver上处理,就必须确保该值足够大,否则OOM内存溢出。
- spark.default.parallelism:每个stage的默认task数量。设置500~1000较合适,默认一个HDFS的block对应一个task,Spark默认值偏少,这样导致不能充分利用资源
- spark.storage.memoryFraction:设置RDD持久化数据在executor内存中能占的比例,默认0.6,即默认executor 60%的内存可以保存持久化RDD数据。若有较多的持久化操作,可以设置高些,超出内存的会频繁gc导致运行缓慢
- spark.shuffle.memoryFraction:聚合操作占executor内存的比例,默认0.2。若持久化操作较少,但shuffle较多时,可以降低持久化内存占比,提高shuffle操作内存占比。
应用代码编写原则
- 避免创建重复的RDD。对同一份数据,只应该创建一个RDD,不能创建多个RDD来代表同一份数据,极大浪费内存。
- 尽可能复用同一个RDD。比如:一个RDD数据格式是key-value,另一个是单独value类型,这两个RDD的value部分完全一样,这样可以复用RDD达到减少算子执行的次数。
- 对多次使用的RDD进行持久化处理。每次对一个RDD执行一个算子操作时,都会重新从源头处理计算一遍,计算出那个RDD出来,然后进一步操作,这种方式性能很差。对多次使用的RDD进行持久化,借助cache()和persist()方法将RDD的数据保存在内存或磁盘中,避免重复劳动。
- persist持久化级别

- 避免使用shuffle类算子。在spark作业运行过程中,最消耗性能的地方就是shuffle过程。将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合和join处理,比如groupByKey、reduceByKey、join等算子,都会触发shuffle。
- 使用map-side预聚合的shuffle操作。一定要使用shuffle的,无法用map类算子替代的,那么尽量使用map-site预聚合的算子。类似MapReduce中的Combiner。可能的情况下使用reduceByKey或aggregateByKey算子替代groupByKey算子,因为reduceByKey或aggregateByKey算子会使用用户自定义的函数对每个节点本地相同的key进行预聚合,而groupByKey算子不会预聚合。
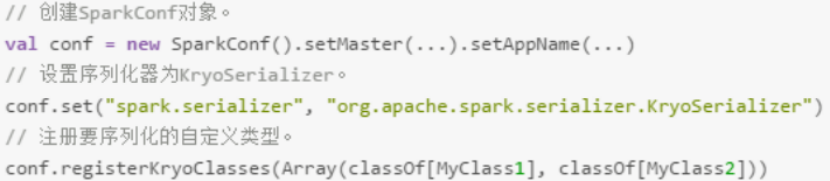
- 使用Kryo优化序列化性能。Kryo是一个序列化类库,来优化序列化和反序列化性能。Spark默认使用Java序列化机制(ObjectOutputStream/ ObjectInputStream API)进行序列化和反序列化。Spark支持使用Kryo序列化库,性能比Java序列化库高很多,10倍左右。
查看应用状态信息
如果某个应用很长时间没有结束,我们可以通过yarn命令来获取更多的信息。使用yarn application –list 命令可以列出所有的应用及应用id。另外可以在应用代码中对RDD使用toDebugString()来查看RDD的详细信息以及依赖关系。也可以对DataFrame使用explain()方法查看查询计划信息。
作业完成后从spark 历史服务器web页面或者yarn的web页面来查看spark作业的历史信息。也可以使用命令行查看yarn logs -applicationId <app_id>。
从这些信息中或许能观察到某些优化线索。