【原文地址】https://docs.mongodb.com/manual/
MongoDB CRUD操作(一)
主要内容:CRUD操作简介,插入文档,查询文档。
CRUD操作包括创建、读取、更新和删除文档。
创建操作
执行创建或者插入操作可向集合中添加文档。如果集合不存在,插入操作会创建此集合。
MongoDB提供下列方法向集合中插入文档:
在MongoDB中,插入操作的目标是一个集合。所有的写操作在单文档级别具有原子性。

读操作
读操作是指在一个集合中查找文档;例如查询一个集合中的所有文档。MongoDB提供了下面的方法来读取集合中的文档:
db.collection.find()
你可以指定查询过滤器或准则来确定要返回的文档。

更新操作
更新操作是指修改集合中已存在的文档。MongoDB提供下列方法来执行更新操作:
- db.collection.update()
- db.collection.updateOne() New in version 3.2
- db.collection.updateMany() New in version 3.2
- db.collection.replaceOne() New in version 3.2
在MongoDB中,更新操作的目标是一个集合。所有的写操作在单文档级别具有原子性。
你能够指定准则或者过滤器来确定要更新的文档。更新操作所使用的过滤器和读操作所使用的过滤器具有相同的句法规则。

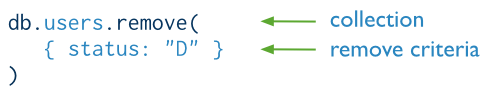
删除操作
删除操作是指从集合中移除文档。MongoDB提供下列操作来实施删除操作:
- db.collection.remove()
- db.collection.deleteOne() New in version 3.2
- db.collection.deleteMany() New in version 3.2
在MongoDB中,删除操作的目标是一个集合。所有的写操作在单文档级别具有原子性。
你能够指定准则或者过滤器来确定要删除的文档。删除操作所使用的过滤器和读操作所使用的过滤器具有相同的句法规则。
批量写入操作
MongoDB 提供了批量写入文档功能。
1 插入操作
1.1 插入方法
为向集合中插入文档,MongoDB提供下列方法:
- db.collection.insertOne()
- db.collection.insertMany()
- db.collection.insert()
这章提供了一些可在mongo shell中执行的例子:
1.2 插入行为
集合的创建
如果集合不存在,插入操作会创建集合。
_id字段
在MongoDB中,存储在集合中的文档需要一个_id字段作为主键。如果没有指定_id字段,MongoDB会使用ObjectIds 作为_id字段的默认值。例如,待插入文档不包含顶级_id字段,MongoDB会添加一个默认值为ObjectIds 的_id字段。
另外,如果mongod接受一个不包含_id字段的待插入文档(例如,通过一个带有更新设置选项的更新操作),mongod会添加一个默认值为ObjectIds 的_id字段。
原子性
在MongoDB中,写操作在单文档级别具有原子性。
1.3 db.collection.insertOne()
3.2版本中新增
db.collection.insertOne():向集合中插入一个文档。
下面的例子为向集合users 中插入一个新文档。新文档有三个字段:name, age, 和 status,因为文档没有指定_id字段,MongoDB会添加一个值为ObjectIds 的_id字段。
db.users.insertOne(
{
name: "sue",
age: 19,
status: "P"
})
方法返回执行结果文档中包含操作的状态:
{
"acknowledged" : true,
"insertedId" : ObjectId("5742045ecacf0ba0c3fa82b0")
}
为了查询已插入的文档,指定关于_id的查询过滤器:
db.users.find( { _id: ObjectId("5742045ecacf0ba0c3fa82b0") } )
1.4 db.collection.insertMany()
3.2版本中新增
db.collection.insertMany():向一个集合中插入多个文档。
下面的例子演示了向集合users 中插入三个文档,每个文档都有三个字段:name, age,和status,因为文档没有指定_id字段,MongoDB会添加一个值为ObjectIds 的_id字段。
db.users.insertMany(
[
{ name: "bob", age: 42, status: "A", },
{ name: "ahn", age: 22, status: "A", },
{ name: "xi", age: 34, status: "D", }
]
)
方法返回执行结果文档中包含操作的状态:
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("57420d48cacf0ba0c3fa82b1"),
ObjectId("57420d48cacf0ba0c3fa82b2"),
ObjectId("57420d48cacf0ba0c3fa82b3")
]
}
为了查询已插入的文档,指定关于_id的查询过滤器:
db.users.find(
{ _id:
{ $in:
[
ObjectId("57420d48cacf0ba0c3fa82b1"),
ObjectId("57420d48cacf0ba0c3fa82b2"),
ObjectId("57420d48cacf0ba0c3fa82b3")
]
}
}
)
1.5 db.collection.insert()
db.collection.insert():向集合中插入一个或多个文档。若要插入一个文档,给方法传递一个文档;若要插入多个文档,给方法传递一个文档数组。
下面的例子为向集合users 中插入一个新文档。新文档有三个字段:name, age, 和 status,因为文档没有指定_id字段,MongoDB会添加一个值为ObjectIds 的_id字段。
db.users.insert(
{
name: "sue",
age: 19,
status: "P"
}
)
方法返回包含了操作执行状态的WriteResult对象。成功插入操作的返回结果如下:
WriteResult({ "nInserted" : 1 })
nInserted字段指出了已插入文档的数量。如果操作发生错误,WriteResult 对象中会包含错误信息。
下面的例子为向集合users 中插入多个新文档,因为文档没有指定_id字段,MongoDB会为每一个文档添加一个值为ObjectIds 的_id字段。
db.users.insert(
[
{ name: "bob", age: 42, status: "A", },
{ name: "ahn", age: 22, status: "A", },
{ name: "xi", age: 34, status: "D", }
]
)
方法返回包含了操作执行状态的BulkWriteResult对象。成功插入操作的返回结果如下:
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 3,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]}
)
1.6 其他方法
下面的方法也能向集合中插入新文档:
- db.collection.update() :当更新设置选项为true时
- db.collection.updateOne() :当更新设置选项为true时
- db.collection.updateMany(): 当更新设置选项为true时
- db.collection.findAndModify() :当更新设置选项为true时
- db.collection.findOneAndUpdate() :当更新设置选项为true时
- db.collection.findOneAndReplace() :当更新设置选项为true时
- db.collection.save().
- db.collection.bulkWrite().
2 查询文档
2.1查询方法
MongoDB提供了db.collection.find()来读取集合中的文档。db.collection.find()方法返回用于匹配文档的游标(cursor )。
db.collection.find( <query filter>, <projection> )
可以为db.collection.find()指定下面的参数字段:
- 查询过滤器(query filter)确定要返回的文档。
- 查询投影器(projection)确定返回匹配文档中的哪些字段,查询投影器限制了从MongoDB服务器返回给客户端的数据量。
你可以选择性地增加一个游标修改器(cursor modifier)来限制查询获得的文档数量,跳过一定条数的文档,或者对查询结果排序。查询返回结果中,文档的顺序是不确定的,除非使用sort()指定。
2.2 示例集合
这页的例子可在mongo shell中使用db.collection.find() 方法检索。在mongo shell中如果一个游标没有赋给一个var变量,那么游标自动迭代20次以打印查询结果中的前20个文档。
为了填充示例集合,在mongo shell中运行:
注意:
如果在集合users 中,已有文档的_id字段值和待插入文档的_id字段值相同,那么要先将users 集合删除(db.users.drop())。
db.users.insertMany(
[
{
_id: 1,
name: "sue",
age: 19,
type: 1,
status: "P",
favorites: { artist: "Picasso", food: "pizza" },
finished: [ 17, 3 ],
badges: [ "blue", "black" ],
points: [
{ points: 85, bonus: 20 },
{ points: 85, bonus: 10 }
]
},
{
_id: 2,
name: "bob",
age: 42,
type: 1,
status: "A",
favorites: { artist: "Miro", food: "meringue" },
finished: [ 11, 25 ],
badges: [ "green" ],
points: [
{ points: 85, bonus: 20 },
{ points: 64, bonus: 12 }
]
},
{
_id: 3,
name: "ahn",
age: 22,
type: 2,
status: "A",
favorites: { artist: "Cassatt", food: "cake" },
finished: [ 6 ],
badges: [ "blue", "red" ],
points: [
{ points: 81, bonus: 8 },
{ points: 55, bonus: 20 }
]
},
{
_id: 4,
name: "xi",
age: 34,
type: 2,
status: "D",
favorites: { artist: "Chagall", food: "chocolate" },
finished: [ 5, 11 ],
badges: [ "red", "black" ],
points: [
{ points: 53, bonus: 15 },
{ points: 51, bonus: 15 }
]
},
{
_id: 5,
name: "xyz",
age: 23,
type: 2,
status: "D",
favorites: { artist: "Noguchi", food: "nougat" },
finished: [ 14, 6 ],
badges: [ "orange" ],
points: [
{ points: 71, bonus: 20 }
]
},
{
_id: 6,
name: "abc",
age: 43,
type: 1,
status: "A",
favorites: { food: "pizza", artist: "Picasso" },
finished: [ 18, 12 ],
badges: [ "black", "blue" ],
points: [
{ points: 78, bonus: 8 },
{ points: 57, bonus: 7 }
]
}
]
)
2.3 查找一个集合中的所有文档
指定查询过滤器文档(query filter document)为空({}),则可查询一个集合中的所有文档:
db.users.find( {} )
省略查询过滤器文档等价于指定查询过滤器(query filter)文档为空({})。例如下面的操作:
db.users.find()
2.4指定查询过滤器条件
指定相等条件
查询过滤器文档使用<field>:<value> 表达式指定相等条件,筛选出所有字段<field>的值为<value>的文档。
{ <field1>: <value1>, ... }
下面的例子从集合users 中筛选出字段status值为“A”的所有文档。
db.users.find( { status: "A" } )
使用查询操作符指定条件
查询过滤器文档可以使用查询操作符来指定查询条件
{ <field1>: { <operator1>: <value1> }, ... }
下面的例子从集合users 中筛选出字段status值为“P”或“D”的所有文档。
db.users.find( { status: { $in: [ "P", "D" ] } } )
尽管可以使用 $or操作符来设置上述查询条件,但是当对同一字段实施多个相等检验时使用$in操作符而不是$or。
指定与(AND)条件
复合查询可为多个字段指定条件。毫无疑问地,逻辑与连接词连接了一个复合查询的从句,使得检索出符合多个条件的所有文档。
下面的例子演示了查询集合users 中字段status的值为“A” ,并且字段age 的值小于30的所有文档。
db.users.find( { status: "A", age: { $lt: 30 } } )
指定或(OR)条件
使用$or操作符,指定使用逻辑或连接词连接查询从句的复合查询,可以从集合中筛选出至少匹配一个查询从句的文档。
下面的例子演示了查询集合users 中字段status的值为“A” 或字段age 的值小于30的所有文档。
db.users.find(
{
$or: [ { status: "A" }, { age: { $lt: 30 } } ]
}
)
同时指定与和或条件
使用额外的从句,可以指定精确的查询条件来查询文档。
下面的例子中,指定复合查询条件:字段status值等于“A”并且字段age的值小于30,或者字段status的值等于“A”并且字段type的值等于1的所有文档。
db.users.find(
{
status: "A",
$or: [ { age: { $lt: 30 } }, { type: 1 } ]
}
)
2.5查询嵌入式文档
当某一字段值为嵌入式文档时,既可以够指定精确的匹配条件筛选嵌入式文档,又可以使用圆点操作符通过嵌入式文档字段筛选数据。
精确匹配嵌入式文档
使用查询文档{ <field>: <value> } 来指定精确的相等匹配条件筛选出整个嵌入式文档,这里 <value> 是要匹配的文档。相等匹配条件要精确,包括字段顺序。
下面的例子中,筛选出这样的文档:favorites 字段值为嵌入式文档并且favorites只包含artist字段和food字段,artist字段值为“Picasso”,food字段值为“pizza”。
db.users.find( { favorites: { artist: "Picasso", food: "pizza" } } )
嵌入式文档字段的相等匹配
使用圆点操作符通过嵌入式文档字段查询。对于嵌入式文档字段的相等匹配,可以筛选出嵌入式文档字段等于指定值的文档。嵌入式文档可以包含额外的字段。
下面的例子中,查询集合users中favorites的artist字段值等于“Picasso”的所有文档。
db.users.find( { "favorites.artist": "Picasso" } )
2.6 查询数组
当字段值为数组时,可以使用精确的数组匹配条件,或者指定数组中的值。如果数组中包含嵌入式文档,可使用圆点操作符指定嵌入式文档字段。
如果使用$elemMatch 操作符指定多个条件,数组中必须至少有一个元素满足条件。
如果不使用$elemMatch操作符指定多个条件,那么数组中元素的组合而不一定是单个元素必须满足所有条件。例如数组中不同的元素满足不同条件。
2.6.1 精确匹配数组
使用查询文档{ <field>: <value> }指定数组相等匹配条件,这里<value>为要匹配的数组。相等匹配条件要精确,包括元素顺序。
下面的例子查询所有badges字段只包含“blue”和“black”这两个元素的文档。
db.users.find( { badges: [ "blue", "black" ] } )
查询结果为:
{
"_id" : 1,
"name" : "sue",
"age" : 19,
"type" : 1,
"status" : "P",
"favorites" : { "artist" : "Picasso", "food" : "pizza" },
"finished" : [ 17, 3 ]
"badges" : [ "blue", "black" ],
"points" : [ { "points" : 85, "bonus" : 20 }, { "points" : 85, "bonus" : 10 } ]
}
2.6.2 匹配数组元素
相等匹配条件可以指定数组中的一个元素。这样的规范能匹配到数组中至少包含一个给定值的文档。
下面的例子查询所有badges字段值中包含“black”元素的文档。
db.users.find( { badges: "black" } )
查询结果为:
{
"_id" : 1,
"name" : "sue",
"age" : 19,
"type" : 1,
"status" : "P",
"favorites" : { "artist" : "Picasso", "food" : "pizza" },
"finished" : [ 17, 3 ]
"badges" : [ "blue", "black" ],
"points" : [ { "points" : 85, "bonus" : 20 }, { "points" : 85, "bonus" : 10 } ]}{
"_id" : 4,
"name" : "xi",
"age" : 34,
"type" : 2,
"status" : "D",
"favorites" : { "artist" : "Chagall", "food" : "chocolate" },
"finished" : [ 5, 11 ],
"badges" : [ "red", "black" ],
"points" : [ { "points" : 53, "bonus" : 15 }, { "points" : 51, "bonus" : 15 } ]}{
"_id" : 6,
"name" : "abc",
"age" : 43,
"type" : 1,
"status" : "A",
"favorites" : { "food" : "pizza", "artist" : "Picasso" },
"finished" : [ 18, 12 ],
"badges" : [ "black", "blue" ],
"points" : [ { "points" : 78, "bonus" : 8 }, { "points" : 57, "bonus" : 7 } ]}
2.6.3 匹配数组中指定元素
使用园点操作符,为数组中某一元素指定相等匹配条件。
下面的例子中,使用圆点操作符为数组badges的第一个元素指定相等匹配条件。
db.users.find( { "badges.0": "black" } )
查询结果为:
{
"_id" : 6,
"name" : "abc",
"age" : 43,
"type" : 1,
"status" : "A",
"favorites" : { "food" : "pizza", "artist" : "Picasso" },
"finished" : [ 18, 12 ],
"badges" : [ "black", "blue" ],
"points" : [ { "points" : 78, "bonus" : 8 }, { "points" : 57, "bonus" : 7 } ]
}
2.6.4 为数组元素指定多个准则(匹配条件)
单个元素符合准则
使用 $elemMatch操作符指定多个准则,至少集合中有一个元素满足指定的准则。
下面的例子演示了找到符合以下条件的文档:finished 数组至少包含一个比15大且比20小的元素。
db.users.find( { finished: { $elemMatch: { $gt: 15, $lt: 20 } } } )
返回结果:
{
"_id" : 1,
"name" : "sue",
"age" : 19,
"type" : 1,
"status" : "P",
"favorites" : { "artist" : "Picasso", "food" : "pizza" },
"finished" : [ 17, 3 ]
"badges" : [ "blue", "black" ],
"points" : [ { "points" : 85, "bonus" : 20 }, { "points" : 85, "bonus" : 10 } ]}{
"_id" : 6,
"name" : "abc",
"age" : 43,
"type" : 1,
"status" : "A",
"favorites" : { "food" : "pizza", "artist" : "Picasso" },
"finished" : [ 18, 12 ],
"badges" : [ "black", "blue" ],
"points" : [ { "points" : 78, "bonus" : 8 }, { "points" : 57, "bonus" : 7 } ]}
元素组合符合准则
下面的例子演示了找到符合以下条件的文档:finished 中的元素的组合满足查询条件。例如,一个元素比15大且其他的元素比20小,或者某个元素既比15大又比20小。
db.users.find( { finished: { $gt: 15, $lt: 20 } } )
查询结果为:
{
"_id" : 1,
"name" : "sue",
"age" : 19,
"type" : 1,
"status" : "P",
"favorites" : { "artist" : "Picasso", "food" : "pizza" },
"finished" : [ 17, 3 ]
"badges" : [ "blue", "black" ],
"points" : [ { "points" : 85, "bonus" : 20 }, { "points" : 85, "bonus" : 10 } ]}{
"_id" : 2,
"name" : "bob",
"age" : 42,
"type" : 1,
"status" : "A",
"favorites" : { "artist" : "Miro", "food" : "meringue" },
"finished" : [ 11, 20 ],
"badges" : [ "green" ],
"points" : [ { "points" : 85, "bonus" : 20 }, { "points" : 64, "bonus" : 12 } ]}{
"_id" : 6,
"name" : "abc",
"age" : 43,
"type" : 1,
"status" : "A",
"favorites" : { "food" : "pizza", "artist" : "Picasso" },
"finished" : [ 18, 12 ],
"badges" : [ "black", "blue" ],
"points" : [ { "points" : 78, "bonus" : 8 }, { "points" : 57, "bonus" : 7 } ]}
2.6.5 嵌入式文档数组
使用数组索引匹配嵌入式文档中的一个字段
如果知道数组中待检索嵌入式文档的索引,可使用圆点操作符和嵌入式文档位置指定嵌入式文档。
例如,检索满足下列条件的所有文档:points 数组中的第一个元素为嵌入式文档,points 为此嵌入式文档中的字段,points值小于等于55。
db.users.find( { 'points.0.points': { $lte: 55 } } )
查询结果为:
{
"_id" : 4,
"name" : "xi",
"age" : 34,
"type" : 2,
"status" : "D",
"favorites" : { "artist" : "Chagall", "food" : "chocolate" },
"finished" : [ 5, 11 ],
"badges" : [ "red", "black" ],
"points" : [ { "points" : 53, "bonus" : 15 }, { "points" : 51, "bonus" : 15 } ]}
匹配字段而不指定索引
如果不知道数组中待检索嵌入式文档的索引,用圆点操作符连接数组字段和嵌入式文档字段。
例如,检索满足下列条件的所有文档:至少有一个嵌入式文档的points字段值小于等于55。
db.users.find( { 'points.points': { $lte: 55 } } )
查询结果为:
{
"_id" : 3,
"name" : "ahn",
"age" : 22,
"type" : 2,
"status" : "A",
"favorites" : { "artist" : "Cassatt", "food" : "cake" },
"finished" : [ 6 ],
"badges" : [ "blue", "red" ],
"points" : [ { "points" : 81, "bonus" : 8 }, { "points" : 55, "bonus" : 20 } ]}{
"_id" : 4,
"name" : "xi",
"age" : 34,
"type" : 2,
"status" : "D",
"favorites" : { "artist" : "Chagall", "food" : "chocolate" },
"finished" : [ 5, 11 ],
"badges" : [ "red", "black" ],
"points" : [ { "points" : 53, "bonus" : 15 }, { "points" : 51, "bonus" : 15 } ]
}
2.6.6 为文档数组指定多个准则
单个元素符合准则
使用$elemMatch操作符,为一个数组中的嵌入式文档指定准则,使得至少有一个嵌入式文档符合所有指定的准则。
例如,找出满足下列条件的所有文档:points 集合中至少有一个嵌入式文档字段points 的值小于等于70且bonus 字段的值等于20。
db.users.find( { points: { $elemMatch: { points: { $lte: 70 }, bonus: 20 } } } )
查询结果为:
{
"_id" : 3,
"name" : "ahn",
"age" : 22,
"type" : 2,
"status" : "A",
"favorites" : { "artist" : "Cassatt", "food" : "cake" },
"finished" : [ 6 ],
"badges" : [ "blue", "red" ],
"points" : [ { "points" : 81, "bonus" : 8 }, { "points" : 55, "bonus" : 20 } ]
}
元素复合准则
例如,找出满足下列条件的所有文档:points 中的数组字段满足复合检索条件。Points数组中的一个嵌入式文档字段points 的值小于等于70并且另一个嵌入式文档字段bonus的值等于20。
查询结果为:
{
"_id" : 2,
"name" : "bob",
"age" : 42,
"type" : 1,
"status" : "A",
"favorites" : { "artist" : "Miro", "food" : "meringue" },
"finished" : [ 11, 20 ],
"badges" : [ "green" ],
"points" : [ { "points" : 85, "bonus" : 20 }, { "points" : 64, "bonus" : 12 } ]}{
"_id" : 3,
"name" : "ahn",
"age" : 22,
"type" : 2,
"status" : "A",
"favorites" : { "artist" : "Cassatt", "food" : "cake" },
"finished" : [ 6 ],
"badges" : [ "blue", "red" ],
"points" : [ { "points" : 81, "bonus" : 8 }, { "points" : 55, "bonus" : 20 } ]}
2.7 其他方法
下面的方法也能从一个集合中读取文档:
- db.collection.findOne
- 在聚集管道中,$match 管道支持MongoDB 查询。
2.8读取隔离
3.2版本新增
为了读取副本集和副本集分片,读关注(read concern)允许客户端选则读隔离级别。
2.9 投影字段以返回查询结果
默认返回文档中所有字段。为了限制返回结果的数据量,可以在查询操作中使用投影器文档。
投影器文档
投影器文档限制了查询操作返回所有匹配到的文档的字段。投影器文档指定了返回结果中包含或排除哪些字段,其格式为:{ field1: <value>, field2: <value> ... }
<value>可以是下面的任何值:
- 1或true表示字段被包含在返回的结果文档中。
- 0或false表示字段不包含在返回的结果文档中。
- 当<value>为表达式时,要使用投影器操作符。
注:
对于_id字段,为使其包含在返回结果中,不用明确指定“_id:1”。db.collection.find() 方法返回结果中总是包含_id字段,除非指定“ _id: 0 ”。
投影器不能同时使用包含规范和排除规范,除对_id做排除以外。在明确指定包含规范的投影器中,仅可对_id字段指定排除规范。
示例集合
在mongo shell中,使用db.collection.find()来检索本页的集合,如果一个游标没有赋给一个var变量,那么游标自动迭代20次以打印查询结果中的前20个文档。
在mongo shell中执行下面的语句来填充users 集合。
注:
如果在集合users 中,已有文档的_id字段值和待插入文档的_id字段值相同,那么要先将集合users删除。
db.users.insertMany(
[
{
_id: 1,
name: "sue",
age: 19,
type: 1,
status: "P",
favorites: { artist: "Picasso", food: "pizza" },
finished: [ 17, 3 ],
badges: [ "blue", "black" ],
points: [
{ points: 85, bonus: 20 },
{ points: 85, bonus: 10 }
]
},
{
_id: 2,
name: "bob",
age: 42,
type: 1,
status: "A",
favorites: { artist: "Miro", food: "meringue" },
finished: [ 11, 25 ],
badges: [ "green" ],
points: [
{ points: 85, bonus: 20 },
{ points: 64, bonus: 12 }
]
},
{
_id: 3,
name: "ahn",
age: 22,
type: 2,
status: "A",
favorites: { artist: "Cassatt", food: "cake" },
finished: [ 6 ],
badges: [ "blue", "red" ],
points: [
{ points: 81, bonus: 8 },
{ points: 55, bonus: 20 }
]
},
{
_id: 4,
name: "xi",
age: 34,
type: 2,
status: "D",
favorites: { artist: "Chagall", food: "chocolate" },
finished: [ 5, 11 ],
badges: [ "red", "black" ],
points: [
{ points: 53, bonus: 15 },
{ points: 51, bonus: 15 }
]
},
{
_id: 5,
name: "xyz",
age: 23,
type: 2,
status: "D",
favorites: { artist: "Noguchi", food: "nougat" },
finished: [ 14, 6 ],
badges: [ "orange" ],
points: [
{ points: 71, bonus: 20 }
]
},
{
_id: 6,
name: "abc",
age: 43,
type: 1,
status: "A",
favorites: { food: "pizza", artist: "Picasso" },
finished: [ 18, 12 ],
badges: [ "black", "blue" ],
points: [
{ points: 78, bonus: 8 },
{ points: 57, bonus: 7 }
]
}
]
)
返回匹配到的全部字段
使用db.collection.find()方法检索而不使用投影器,将返回文档的全部字段。
例如,从users 集合中检索字段status 的值为“A”的文档。
db.users.find( { status: "A" } )
查询结果:
{
"_id" : 2,
"name" : "bob",
"age" : 42,
"type" : 1,
"status" : "A",
"favorites" : { "artist" : "Miro", "food" : "meringue" },
"finished" : [ 11, 25 ],
"badges" : [ "green" ],
"points" : [ { "points" : 85, "bonus" : 20 }, { "points" : 64, "bonus" : 12 } ]}
{
"_id" : 3,
"name" : "ahn",
"age" : 22,
"type" : 2,
"status" : "A",
"favorites" : { "artist" : "Cassatt", "food" : "cake" },
"finished" : [ 6 ],
"badges" : [ "blue", "red" ],
"points" : [ { "points" : 81, "bonus" : 8 }, { "points" : 55, "bonus" : 20 } ]}
{
"_id" : 6,
"name" : "abc",
"age" : 43,
"type" : 1,
"status" : "A",
"favorites" : { "food" : "pizza", "artist" : "Picasso" },
"finished" : [ 18, 12 ],
"badges" : [ "black", "blue" ],
"points" : [ { "points" : 78, "bonus" : 8 }, { "points" : 57, "bonus" : 7 } ]}
只返回指定字段和_id字段
例如,结果集中只包含name, status和_id字段
db.users.find( { status: "A" }, { name: 1, status: 1 } )
查询结果为:
{ "_id" : 2, "name" : "bob", "status" : "A" }
{ "_id" : 3, "name" : "ahn", "status" : "A" }
{ "_id" : 6, "name" : "abc", "status" : "A" }
只返回指定字段
db.users.find( { status: "A" }, { name: 1, status: 1, _id: 0 } )
查询结果为:
{ "name" : "bob", "status" : "A" }
{ "name" : "ahn", "status" : "A" }
{ "name" : "abc", "status" : "A" }
排除某些字段
db.users.find( { status: "A" }, { favorites: 0, points: 0 } )
查询结果为:
{
"_id" : 2,
"name" : "bob",
"age" : 42,
"type" : 1,
"status" : "A",
"finished" : [ 11, 25 ],
"badges" : [ "green" ]}{
"_id" : 3,
"name" : "ahn",
"age" : 22,
"type" : 2,
"status" : "A",
"finished" : [ 6 ],
"badges" : [ "blue", "red" ]}
{
"_id" : 6,
"name" : "abc",
"age" : 43,
"type" : 1,
"status" : "A",
"finished" : [ 18, 12 ],
"badges" : [ "black", "blue" ]}
返回嵌入式文档中指定字段
使用圆点操作符指定嵌入式文档中的字段。
例如,设定投影器,返回_id 字段, name字段, status字段, 和嵌入式文档favorites 中的food 字段,food字段被包含在匹配到的文档的字段favorites 中。
db.users.find(
{ status: "A" },
{ name: 1, status: 1, "favorites.food": 1 }
)
查询结果为:
{ "_id" : 2, "name" : "bob", "status" : "A", "favorites" : { "food" : "meringue" } }
{ "_id" : 3, "name" : "ahn", "status" : "A", "favorites" : { "food" : "cake" } }
{ "_id" : 6, "name" : "abc", "status" : "A", "favorites" : { "food" : "pizza" } }
排除嵌入式文档中的指定字段
使用圆点操作符将嵌入式文档中的字段值设置为0。
例如,排除嵌入式文档favorites中的food字段,其他字段都返回
db.users.find(
{ status: "A" },
{ "favorites.food": 0 }
)
查询结果为:
{
"_id" : 2,
"name" : "bob",
"age" : 42,
"type" : 1,
"status" : "A",
"favorites" : { "artist" : "Miro" },
"finished" : [ 11, 25 ],
"badges" : [ "green" ],
"points" : [ { "points" : 85, "bonus" : 20 }, { "points" : 64, "bonus" : 12 } ]
}
{
"_id" : 3,
"name" : "ahn",
"age" : 22,
"type" : 2,
"status" : "A",
"favorites" : { "artist" : "Cassatt" },
"finished" : [ 6 ],
"badges" : [ "blue", "red" ],
"points" : [ { "points" : 81, "bonus" : 8 }, { "points" : 55, "bonus" : 20 } ]
}
{
"_id" : 6,
"name" : "abc",
"age" : 43,
"type" : 1,
"status" : "A",
"favorites" : { "artist" : "Picasso" },
"finished" : [ 18, 12 ],
"badges" : [ "black", "blue" ],
"points" : [ { "points" : 78, "bonus" : 8 }, { "points" : 57, "bonus" : 7 } ]
}
投射器作用于数组中的嵌入式文档
使用圆点操作符投射数组中嵌入式文档的指定字段。
例如,指定投射器,返回name字段 、status 字段和bonus 字段;_id 字段默认返回。
db.users.find( { status: "A" }, { name: 1, status: 1, "points.bonus": 1 } )
查询结果:
{ "_id" : 2, "name" : "bob", "status" : "A", "points" : [ { "bonus" : 20 }, { "bonus" : 12 } ] }
{ "_id" : 3, "name" : "ahn", "status" : "A", "points" : [ { "bonus" : 8 }, { "bonus" : 20 } ] }
{ "_id" : 6, "name" : "abc", "status" : "A", "points" : [ { "bonus" : 8 }, { "bonus" : 7 } ] }
在返回的数组中投射指定的数组元素
对于包含数组的字段,MongoDB提供了下面的投影器操作符:$elemMatch, $slice, 和$.
例如,使用 $slice投影操作符来返回scores 数组中最后一个元素。
db.users.find( { status: "A" }, { name: 1, status: 1, points: { $slice: -1 } } )
查询结果为:
{ "_id" : 2, "name" : "bob", "status" : "A", "points" : [ { "points" : 64, "bonus" : 12 } ] }
{ "_id" : 3, "name" : "ahn", "status" : "A", "points" : [ { "points" : 55, "bonus" : 20 } ] }
{ "_id" : 6, "name" : "abc", "status" : "A", "points" : [ { "points" : 57, "bonus" : 7 } ] }
$elemMatch, $slice, 和$是投射指定元素(多个)且使其包含在返回结果中的仅有的方式。例如,不能使用数组索引投射任何元素,投影器{ "ratings.0": 1 },不会投射数组中的第一个元素。
2.10 查询null或缺失的字段
在MongoDB 中,不同的操作符对待null值是不同的。
本页中的例子在mongo shell中执行db.collection.find()方法。为了填充集合users,在mongo shell中执行:
db.users.insert(
[
{ "_id" : 900, "name" : null },
{ "_id" : 901 }
]
)
相等过滤器
查询匹配文档{ name : null }检索出这样的文档:文档包含值为null的name字段,或者文档不包含name字段。
给出如下查询:
db.users.find( { name: null } )
查询返回结果为:
{ "_id" : 900, "name" : null }
{ "_id" : 901 }
如果索引是稀疏的,那么只会匹配null值而不是缺失的字段。
2.6版本中的变更:如果使用稀疏索引导致不完整的结果,MongoDB 将不会使用索引,除非使用hint()指定索引。
类型检测
使用{ name : { $type: 10 } }匹配出name 字段为null的文档。例如name 字段值为Null(BSON类型)。
db.users.find( { name : { $type: 10 } } )
查询结果为:
{ "_id" : 900, "name" : null }
存在检测
使用{ name : { $exists: false } }匹配出不包含某一字段的文档:
db.users.find( { name : { $exists: false } } )
查询结果为:
{ "_id" : 901 }
2.11在mongo shell中迭代游标
db.collection.find() 方法返回游标,为了使用文档,你需要迭代游标。然而,如果返回的游标没有赋给var类型的变量,那么游标会自动迭代20次以打印结果集中前20个文档。
下面的例子描述了手动迭代游标来使用文档或迭代器索引的方式。
2.11.1 手动迭代游标
在mongo shell,当你将由 find()方法返回的游标赋给var类型变量时,游标不会迭代。
你可以在mongo shell中调用游标变量,迭代20次并打印匹配文档,例子如下:
var myCursor = db.users.find( { type: 2 } );
myCursor
你可以使用游标方法next() 来使用文档,例子如下:
var myCursor = db.users.find( { type: 2 } );
while (myCursor.hasNext()) {
print(tojson(myCursor.next()));
}
作为一种替代的打印方式,考虑使用printjson()这一帮助方法来替代print(tojson()):
var myCursor = db.users.find( { type: 2 } );
while (myCursor.hasNext()) {
printjson(myCursor.next());
}
你可以使用游标方法forEach()来迭代游标并使用文档,例子如下:
var myCursor = db.users.find( { type: 2 } );
myCursor.forEach(printjson);
2.11.2 迭代器索引
在mongo shell,你可以使用toArray()方法来迭代游标并返回数组中的文档,例子如下:
var myCursor = db.inventory.find( { type: 2 } );
var documentArray = myCursor.toArray();
var myDocument = documentArray[3];
toArray() 方法将游标返回的所有文档都加载到内存中,它会耗尽游标。
另外,一些驱动提供了通过使用游标索引来获得文档的方法(例如,cursor[index])。先调用toArray()方法,然后使用结果集索引,这是一种便捷的方式。
考虑如下的例子:
var myCursor = db.users.find( { type: 2 } );
var myDocument = myCursor[1];
同myCursor[1] 等价的方式为:
myCursor.toArray() [1];
2.11.3 游标行为
关闭无效的游标
默认地,游标的不活跃时期超过十分钟时或者客户端耗尽游标,服务器会自动关闭游标。为在mongo shell中重设置这一行为,可以使用cursor.noCursorTimeout()方法:
var myCursor = db.users.find().noCursorTimeout();
设置了noCursorTimeout 选项以后,必须使用cursor.close() 方法手动关闭游标,或者通过耗尽游标结果的方式关闭游标。
游标隔离
当使用游标获得文档的同时,其他的查询操作可能正在执行。对于MMAPv1 存储引擎,对一个文档的交替写操作,如果文档已经改变了,可能导致游标返回同一文档两次。为了控制这种情况,请参考snapshot mode。
游标批处理
MongoDB 成批地返回查询结果。批大小不会超过BSON文档的最大值。对于大多数查询来说,第一批返回101个文档,或者超过1MB的文档,随后的批大小为4MB,为了重置批大小,可以使用batchSize() 和limit()方法。
没有索引的情况下,如果查询包含排序操作,服务器要将所有的文档加载到内存中以执行排序。
当你使用游标迭代并且达到了已返回那批的末尾时,如果还有更多的数据,cursor.next() 方法将会执行获取更多操作来检索下一批。当你迭代游标时,为了查看有多少文档在某一批中,你可以使用objsLeftInBatch()方法,例如:
var myCursor = db.inventory.find();
var myFirstDocument = myCursor.hasNext() ? myCursor.next() : null;
myCursor.objsLeftInBatch();
游标信息
db.serverStatus() 方法返回的文档中包含metrics 字段,metrics 字段包含具有如下信息的metrics.cursor 字段:
- 从服务器最近一次重启到当期时间的超时游标数量。
- 设置DBQuery.Option.noTimeout选项的已打开游标数量,设置DBQuery.Option.noTimeout可防止一段不活跃期后游标超时。
- 被“定住”的已打开游标。
- 已打开游标的总数。
如下的例子中,调用db.serverStatus()方法,使用返回结果中的字段metrics 和metrics 中的字段cursor:
db.serverStatus().metrics.cursor
执行结果为:
{
"timedOut" : <number>
"open" : {
"noTimeout" : <number>,
"pinned" : <number>,
"total" : <number>
}
}
-----------------------------------------------------------------------------------------
转载与引用请注明出处。
时间仓促,水平有限,如有不当之处,欢迎指正。