普通哈希算法
假如有cache主机5台分别为cacheA、cacheB、cacheC、cacheD、cacheE
当程序进行hash时,首先每个节点要根据自己的唯一参数哈希出一个值来(如根据ip进行哈希)
主机哈希完成后形成的哈希值如下
cacheA 0
cacheB 1
cacheC 2
cacheD 3
cacheE 4
主机形成哈希值后,我们以缓存来做实例,比如某个用户登录后会有一个唯一的pin值,然后根据
这个pin值进行hash求余。因为求余是用5来求余,所以数值肯定会小宇5 因此就有了落点,然后把
缓存数据进行缓存到落点服务器中
一致性哈希算法
假如有cache主机5台分别为cacheA、cacheB、cacheC、cacheD、cacheE
当程序进行hash时,首先每个节点要根据自己的唯一参数哈希出一个值来(如根据ip进行哈希)
主机哈希完成后形成的哈希值如下
cacheA key1
cacheB key2
cacheC key3
cacheD key4
cacheE key5
然后5台节点围绕称一个环形,如图
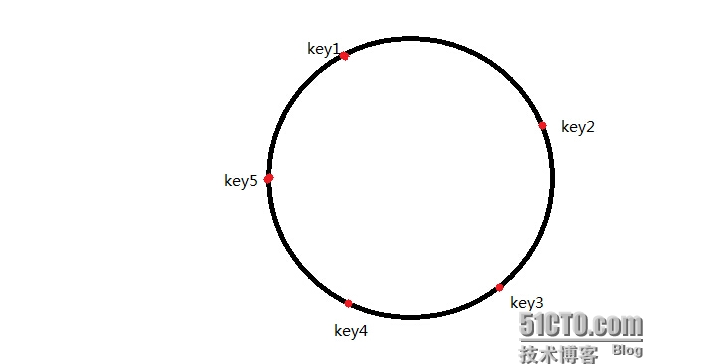
主机形成哈希值后,我们以缓存来做实例,比如某个用户登录后会有一个唯一的pin值,然后根据
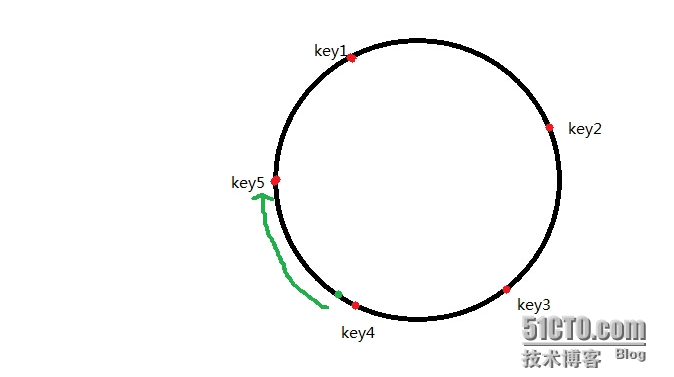
这个pin值进行hash。这里注意和普通hash不一样的就是这里只hash不求余,当hash出一个数值
后,查看这个这个值介于那两个值之间比如介于key4和key5之间,然后从这个落点开始顺时针查
找遇到第一个cache服务器后就把这个服务器当作此次缓存的落点,从而把这个缓存放到这个落点
上。如图:
两者比较:
经过上面的介绍我们能看出,假如普通的哈希当其中任意一台机器down掉后,我们整个的
缓存都将安然无存,为什么这么说呢?
因为当某台cache down掉后我们需要重选算落点,除数已经变了,所以都要重新set缓存,
当然不排除有一些两个pin值算的落点是一样的,但是当cache服务器增加到一定数量后,前面所
说的可能性几乎为0,所以称之为全部缓存都要重新set。
而使用一致性哈希当其中一台机器down掉后,只有它上面到它这一段的环路缓存失效了,如:
当cache3 down掉后,那落掉在cache2到cache3之间的pin都将失效,那么失效的落点讲继续顺时
针查找cache服务器,那么新的落点都将落到cache4上。