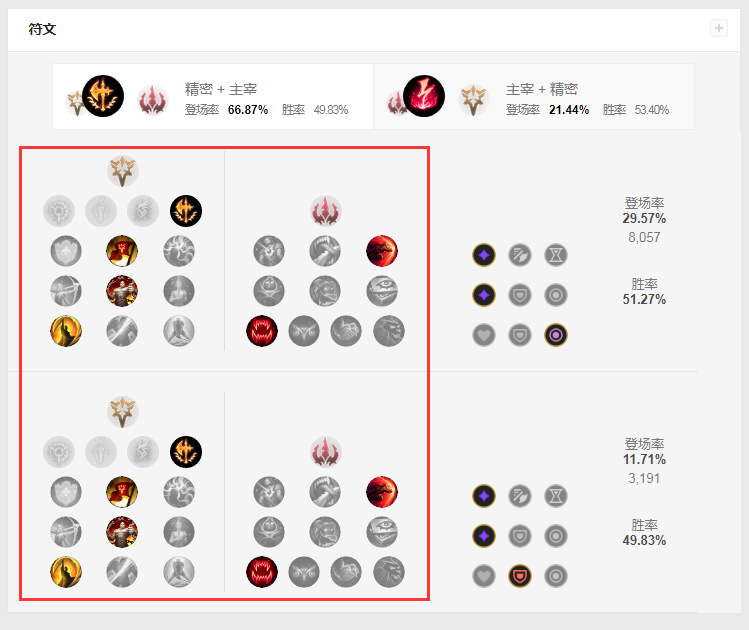
业务需求,需要爬取英雄联盟英雄的符文图片,然后在把它们拼接回去。
以下是爬取单个英雄katarina的符文图片到本地的代码,爬取地址为:
http://www.op.gg/champion/katarina/statistics/mid
要爬取的图片内容为:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author:hejianping
#2019/05/21
from bs4 import BeautifulSoup
import requests
response = requests.get(url='http://www.op.gg/champion/katarina/statistics/mid')
print(response.text) # 查看页面是否下载下来。
soup = BeautifulSoup(response.text,features='html.parser')
# 英雄名字
info = soup.find(class_="champion-stats-header-info")
name =info.find('h1').text
print(name)
target = soup.find(class_="tabItem ChampionKeystoneRune-1")
#print(target)
div_list = target.find_all(class_="perk-page__item")
#print(div_list)
def mkdir(path):
import os
path = path.strip()
path = path.rstrip("\")
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)
path + ' 创建成功'
return True
else:
path + ' 目录已存在'
return False
# 定义要创建的目录
mkpath = "F:\爬虫\www.op.gg_champion_statistics\splider\" + name + '\'
print(mkpath)
# 调用函数
mkdir(mkpath)
count = 0
for i in div_list:
img = i.find('img')
if img:
# 图片地址
# print(img.attrs.get('scr'))
img_url = 'http:' + img.attrs.get('src')
print(img_url) # 官网上的链接少了http: 自己拼接。
# 把图片下载到本地保存起来。
img_response = requests.get(url=img_url)
# import uuid # 随机起名字。
# file_name = str(uuid.uuid4()) + '.jpg'
# 设置图片存放地址和命名规范。
file_name = mkpath + str(count + 1) + '.jpg'
count = count + 1
with open(file_name,'wb') as f:
f.write(img_response.content) # .content 返回字节类型