一、需求:spark写入phoniex
二、实现方式
1.官网方式
dataFrame.write
.format("org.apache.phoenix.spark")
.mode("overwrite")
.option("table", table)
.option("zkUrl", zkUrl)
.option("skipNormalizingIdentifier", true)
.save()
这个方式底层是使用MapReduce的RecordWriter实现类PhoenixRecordWriter通过jdbc方式写入
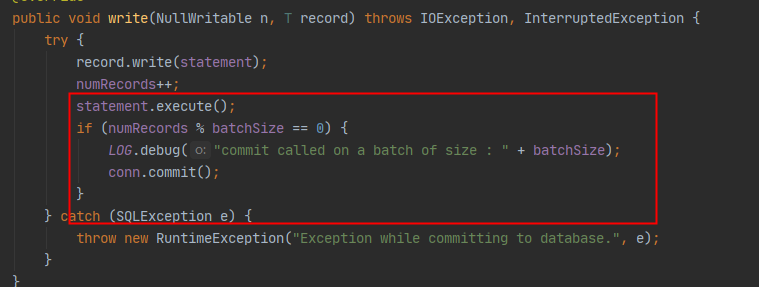
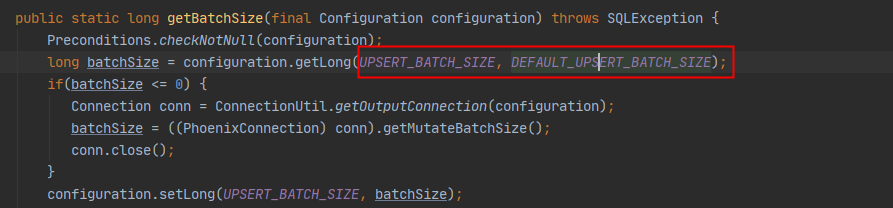
但是默认的batchsize是1000,所以插入速度极慢,但是官网没有说明写入的参数设置,需要去源码里面寻找一下
所以可以通过设置参数来提升速度
.option(PhoenixConfigurationUtil.UPSERT_BATCH_SIZE,batch)
二、自己实现jdbc的通用方式(任何jdbc方式都可以写入)
代码:
object JdbcUtils {
def jdbcBatchInsert(dataFrame: DataFrame, table: String, url: String, pro: Properties, batch: Int): Unit = {
val fields: Array[String] = dataFrame.schema.fieldNames
val schema: Array[StructField] = dataFrame.schema.toArray
val numFields = fields.length
val fieldsSql = fields.map(str => """.concat(str).concat(""")).mkString("(", ",", ")")
val charSql = fields.map(str => "?").mkString(",")
val setters: Array[JDBCValueSetter] = schema.map(f => makeSetter(f.dataType))
val insertSql = s"upsert into $table $fieldsSql values ($charSql) "
System.err.println("插入sql:" + insertSql)
val start = System.currentTimeMillis()
dataFrame.rdd.foreachPartition(partition => {
val connection = DriverManager.getConnection(url, pro)
try {
connection.setAutoCommit(false)
val pstmt: PreparedStatement = connection.prepareStatement(insertSql)
var count = 0
var cnt = 0
partition.foreach(row => {
for (i <- 0 until numFields) {
if (row.isNullAt(i)) {
pstmt.setNull(i + 1, getJdbcType(schema(i).dataType))
} else {
setters(i).apply(pstmt, row, i)
}
}
pstmt.addBatch()
count += 1
if (count % batch == 0) {
pstmt.executeBatch()
connection.commit()
cnt += 1
println(s"${TaskContext.get.partitionId}分区,提交第${cnt}次,${count}tiao")
}
})
pstmt.executeBatch()
connection.commit()
println(s"第${TaskContext.get.partitionId}分区,共提交第${cnt},${count}条")
} finally {
connection.close()
}
})
val end = System.currentTimeMillis()
println(s"插入表$table,共花费时间${(end - start) / 1000}秒")
}
private type JDBCValueSetter = (PreparedStatement, Row, Int) => Unit
/**
* 类型匹配 如果有其他类型 自行添加
*
* @param dataType
* @return
*/
def makeSetter(dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
if (row.isNullAt(pos)) {
stmt.setNull(pos + 1, java.sql.Types.INTEGER)
} else {
stmt.setInt(pos + 1, row.getInt(pos))
}
case LongType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setLong(pos + 1, row.getLong(pos))
case DoubleType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setDouble(pos + 1, row.getDouble(pos))
case FloatType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setFloat(pos + 1, row.getFloat(pos))
case ShortType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setInt(pos + 1, row.getShort(pos))
case ByteType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setInt(pos + 1, row.getByte(pos))
case BooleanType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setBoolean(pos + 1, row.getBoolean(pos))
case StringType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setString(pos + 1, row.getString(pos))
case BinaryType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos))
case TimestampType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos))
case DateType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos))
case t: DecimalType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setBigDecimal(pos + 1, row.getDecimal(pos))
/* case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase(Locale.ROOT).split("\(")(0)
(stmt: PreparedStatement, row: Row, pos: Int) =>
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos).toArray)
stmt.setArray(pos + 1, array)*/
case _ =>
(_: PreparedStatement, _: Row, pos: Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}
/**
* sql类型匹配 如果有其他类型 自行添加
*
* @param dt
* @return
*/
private def getJdbcType(dt: DataType): Int = {
dt match {
case IntegerType => java.sql.Types.INTEGER
case LongType => java.sql.Types.BIGINT
case DoubleType => java.sql.Types.DOUBLE
case StringType => java.sql.Types.VARCHAR
case _ => java.sql.Types.VARCHAR
}
}
}
测试:
#config是个map集合要不要都可以
val connectionProperties = new Properties();
connectionProperties.setProperty(QueryServices.MAX_MUTATION_SIZE_ATTRIB, config.getOrDefault("phoenix.mutate.maxSize", "500000")); //改变默认的500000
connectionProperties.setProperty(QueryServices.MUTATE_BATCH_SIZE_BYTES_ATTRIB, config.getOrDefault("phoenix.mutate.batchSizeBytes", "1073741824000"))
val batch = config.getOrDefault("phoenix.insert.batchSize", "50000").toInt
//调用插入方法
JdbcUtils.jdbcBatchInsert(dataFrame, table, phoenixUrl, connectionProperties, batch);