这是《selenium2+python学习总结》的升级版。
- 1. 项目结构
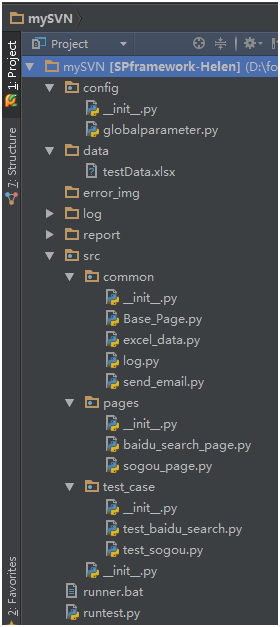
- 2. 项目代码
1) globalparameter.py
# coding:utf-8 __author__ = 'helen' import time,os ''' 配置全局参数 ''' # 项目的绝对路径(因为 windows执行时需要绝对路径才能执行通过) # project_path = "D:\for2017\SPframework-Helen_2.0\" # 获取项目路径 project_path = os.path.abspath(os.path.join(os.path.dirname(os.path.realpath(__file__)[0]), '.')) print project_path # 测试用例代码存放路径(用于构建suite,注意该文件夹下的文件都应该以test开头命名) test_case_path = project_path+"\src\test_case" # excel测试数据文档存放路径 test_data_path = project_path+"\data\testData.xlsx" # 日志文件存储路径 log_path = project_path+"\log\mylog.log" print u'日志路径:'+log_path # 测试报告存储路径,并以当前时间作为报告名称前缀 report_path = project_path+"\report\" report_name = report_path+time.strftime('%Y%m%d%H%S', time.localtime()) # 异常截图存储路径,并以当前时间作为图片名称前缀 img_path = project_path+"\error_img\"+time.strftime('%Y%m%d%H%S', time.localtime()) # 设置发送测试报告的公共邮箱、用户名和密码 smtp_sever = 'mail.**.com' # 邮箱SMTP服务,各大运营商的smtp服务可以在网上找,然后可以在foxmail这些工具中验正 email_name = "SDS@**.com" # 发件人名称 email_password = "****" # 发件人登录密码 email_To = '5047**0@qq.com;54*0016@qq.com;hel**ter@163.com' # 收件人
2) log.py
# coding:utf-8 __author__ = 'helen' import logging from config import globalparameter as gl ''' 配置日志文件,输出INFO级别以上的日志 ''' class log: def __init__(self): self.logname = "mylog" def setMSG(self, level, msg): # 之前把下面定义log的一大段代码写在了__init__里面,造成了日志重复输出 # 此大坑,谨记谨记!!!! logger = logging.getLogger() # 定义Handler输出到文件和控制台 fh = logging.FileHandler(gl.log_path) ch = logging.StreamHandler() # 定义日志输出格式 formater = logging.Formatter("%(asctime)s %(levelname)s %(message)s' ") fh.setFormatter(formater) ch.setFormatter(formater) # 添加Handler logger.addHandler(fh) logger.addHandler(ch) # 添加日志信息,输出INFO级别的信息 logger.setLevel(logging.INFO) if level=='debug': logger.debug(msg) elif level=='info': logger.info(msg) elif level=='warning': logger.warning(msg) elif level=='error': logger.error(msg) # 移除句柄,否则日志会重复输出 logger.removeHandler(fh) logger.removeHandler(ch) fh.close() def debug(self, msg): self.setMSG('debug', msg) def info(self, msg): self.setMSG('info', msg) def warning(self, msg): self.setMSG('warning', msg) def error(self, msg): self.setMSG('error', msg)
3) send_mail.py
# coding:utf-8 __author__ = 'helen' import os,smtplib,os.path from config import globalparameter as gl from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from src.common import log ''' 邮件发送最新的测试报告 ''' class send_email: def __init__(self): self.mylog = log.log() # 定义邮件内容 def email_init(self,report,reportName): with open(report,'rb')as f: mail_body = f.read() # 创建一个带附件的邮件实例 msg = MIMEMultipart() # 以测试报告作为邮件正文 msg.attach(MIMEText(mail_body,'html','utf-8')) report_file = MIMEText(mail_body,'html','utf-8') # 定义附件名称(附件的名称可以随便定义,你写的是什么邮件里面显示的就是什么) report_file["Content-Disposition"] = 'attachment;filename='+reportName msg.attach(report_file) # 添加附件 msg['Subject'] = '自动化测试报告:'+reportName # 邮件标题 msg['From'] = gl.email_name #发件人 msg['To'] = gl.email_To #收件人列表 try: server = smtplib.SMTP(gl.smtp_sever) server.login(gl.email_name,gl.email_password) server.sendmail(msg['From'],msg['To'].split(';'),msg.as_string()) server.quit() except smtplib.SMTPException: self.mylog.error(u'邮件发送测试报告失败 at'+__file__) def sendReport(self): # 找到最新的测试报告 report_list = os.listdir(gl.report_path) report_list.sort(key=lambda fn: os.path.getmtime(gl.report_path+fn) if not os.path.isdir(gl.report_path+fn) else 0) new_report = os.path.join(gl.report_path,report_list[-1]) # 发送邮件 self.email_init(new_report,report_list[-1])
4) excel_data.py
# coding:utf-8 __author__ = 'helen' import xlrd from src.common import log from config.globalparameter import test_data_path ''' 读取excel文件 ''' class excel: def __init__(self): self.mylog = log.log() def open_excel(self,file): u'''读取excel文件''' try: data = xlrd.open_workbook(file) return data except Exception, e: self.mylog.error(u"打开excel文件失败") def excel_table(self,file, sheetName): u'''装载list''' data = self.open_excel(file) # 通过工作表名称,获取到一个工作表 table = data.sheet_by_name(sheetName) # 获取行数 Trows = table.nrows # 获取 第一行数据 Tcolnames = table.row_values(0) lister = [] for rownumber in range(1,Trows): row = table.row_values(rownumber) if row: app = {} for i in range(len(Tcolnames)): app[Tcolnames[i]] = row[i] lister.append(app) return lister def get_list(self,sheetname): try: data_list = self.excel_table(test_data_path, sheetname) assert len(data_list)>=0,u'excel标签页:'+sheetname+u'为空' return data_list except Exception as e: self.mylog.error(u'excel标签页:'+sheetname+u'为空') raise e
5) Base_Page.py
# coding:utf-8 __author__ = 'helen' from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from src.common import log from config.globalparameter import img_path ''' project:封装页面公用方法 ''' class BasePage(object): def __init__(self, selenium_driver, base_url, page_title): self.driver = selenium_driver self.url = base_url self.title = page_title self.mylog = log.log() # 打开页面,并校验链接是否加载正确 def _open(self, url, page_title): try: self.driver.get(url) self.driver.maximize_window() # 通过断言输入的title是否在当前title中 assert page_title in self.driver.title, u'打开页面失败:%s' % url except: self.mylog.error(u'未能正确打开页面:'+url) # 重写find_element方法,增加定位元素的健壮性 def find_element(self, *loc): try: WebDriverWait(self.driver, 10).until(EC.visibility_of_element_located(loc)) return self.driver.find_element(*loc) except: self.mylog.error(u'找不到元素:'+str(loc)) # 重写send_keys方法 def send_keys(self, value, clear=True, *loc): try: if clear: self.find_element(*loc).clear() self.find_element(*loc).send_keys(value) except AttributeError: self.mylog.error(u'输入失败,loc='+str(loc)+u';value='+value) # 截图 def img_screenshot(self, img_name): try: self.driver.get_screenshot_as_file(img_path+img_name+'.png') except: self.mylog.error(u'截图失败:'+img_name)
6) baidu_page.py
# coding:utf-8 __author__ = 'helen' from selenium.webdriver.common.by import By from src.common.Base_Page import BasePage from selenium.webdriver.common.action_chains import ActionChains class BaiduPage(BasePage): # 定位器 keywords_loc = (By.ID, 'kw') submit_loc = (By.ID, 'su') hao123_loc = (By.NAME, 'tj_trhao123') more_loc = (By.LINK_TEXT, u'更多产品') zhidao_loc = (By.NAME,'tj_zhidao') # 打开页面 def open(self): self._open(self.url, self.title) # 输入关键词 def input_keywords(self, keywords): self.find_element(*self.keywords_loc).send_keys(keywords) # 点击搜索按钮 def click_submit(self): self.find_element(*self.submit_loc).click() # 点击hao123链接 def click_hao123(self): self.find_element(*self.hao123_loc).click() # 鼠标悬停在"更多产品"上 def ActionChains_more(self): mouse = self.find_element(*self.more_loc) ActionChains(self.driver).move_to_element(mouse).perform() # 点击“全部产品” def click_zhidao(self): self.find_element(*self.zhidao_loc).click()
7) test_baidu.py
# coding:utf-8 __author__ = 'helen' import unittest from selenium import webdriver from src.pages.baidu_page import BaiduPage from time import sleep ''' project:百度页面测试 ''' class TestBaiduSearch(unittest.TestCase): def setUp(self): self.driver = webdriver.Firefox() self.url = 'https://www.baidu.com/' self.keyword = 'python' self.baidu_page = BaiduPage(self.driver, self.url, u'百度') def test_baidu_search(self): u'''百度搜索''' try: self.baidu_page.open() self.baidu_page.input_keywords(self.keyword) self.baidu_page.click_submit() sleep(2) self.assertIn(self.keyword, self.driver.title) except Exception as e: self.baidu_page.img_screenshot(u'百度搜索') raise e def test_baidu_changeto_hao123(self): u'''从百度首页打开hao123''' try: self.baidu_page.open() self.baidu_page.click_hao123() self.assertEqual(self.driver.current_url, 'https://www.hao123.com/') except Exception as e: self.baidu_page.img_screenshot(u'从百度首页打开hao123') raise e def test_baidu_more(self): u'''打开百度知道''' try: self.baidu_page.open() self.baidu_page.ActionChains_more() self.baidu_page.click_zhidao() self.assertEqual(self.driver.current_url, 'https://zhidao.baidu.com/') except Exception as e: self.baidu_page.img_screenshot(u'打开百度知道') raise e def tearDown(self): self.driver.close()
8) sogou_page.py
# coding:utf-8 __author__ = 'helen' from selenium.webdriver.common.by import By from src.common.Base_Page import BasePage ''' project:sogo页面元素管理 ''' class sogou_page(BasePage): # 定位 keyword_loc = (By.ID, 'query') sumit_loc = (By.ID, 'stb') def open(self): self._open(self.url,self.title) # 输入关键词 def input_keyword(self, value): self.find_element(*self.keyword_loc).send_keys(value) # 点击搜索 def click_sumit(self): self.find_element(*self.sumit_loc).click()
9) test_sogou.py
# coding:utf-8 __author__ = 'helen' import unittest from selenium import webdriver from src.pages.sogou_page import sogou_page from src.common.log import log from src.common import excel_data '''sogou页面测试 ''' class test_sogou(unittest.TestCase): def setUp(self): self.mylog = log() self.driver = webdriver.Firefox() self.url = 'https://www.sogou.com/' self.sogou_page = sogou_page(self.driver,self.url,u'搜狗') self.excel = excel_data.excel() def test_search(self): u'''搜狗搜索:excel数据驱动''' keyword_list = self.excel.get_list('sogou_search') for i in range(0, len(keyword_list)): keyword = keyword_list[i]["keyword"] try: self.sogou_page.open() self.sogou_page.input_keyword(keyword) self.sogou_page.click_sumit() # 因为assert对比是的str所以要判断keyword类型如何不是str, 就要进行转换 if type(keyword)!=str: keyword = str(keyword) self.assertIn(keyword,self.driver.title) except Exception as e: self.mylog.error('error for search keyword:'+str(keyword)) self.sogou_page.img_screenshot(u'搜狗搜索') raise e def tearDown(self): self.driver.close() if __name__=='__main__': unittest.main()
10) runtest.py
# coding:utf-8 __author__ = 'helen' import unittest,time,HTMLTestRunner from config.globalparameter import test_case_path,report_name from src.common import send_email ''' 构建测试套件,并执行测试 ''' # 构建测试集,包含src/test_case目录下的所有以test开头的.py文件 suite = unittest.defaultTestLoader.discover(start_dir=test_case_path,pattern='test*.py') # 执行测试 if __name__=="__main__": report = report_name+"Report.html" fb = open(report,'wb') runner = HTMLTestRunner.HTMLTestRunner( stream=fb, title=u'自动化测试报告', description=u'项目描述。………' ) runner.run(suite) fb.close() # 发送邮件 time.sleep(10) # 设置睡眠时间,等待测试报告生成完毕(这里被坑了==) email = send_email.send_email() email.sendReport()