分析目标
爬取的是斗鱼主播头像,示范使用的URL似乎是个移动接口(下文有提到),理由是网页主页属于动态页面,爬取难度陡升,当然爬取斗鱼主播头像这么恶趣味的事也不是我的兴趣......
目标URL如下,
http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=150
这是一个json形式文件(所谓json形式的文件实际就是把字典作为字符串保存起来),limit参数表示一次加载多少条目,offset表示偏移量,即加载的第一条项目相对于初始条目的位次数。
形式如下(这不是查看源码,而是数据本身就是这样,好像是个移动端接口),

形式和我之前保存的json相同,是字典的格式,key有error和data,data的value是list,中间的元素是房间的信息dict,这里列举了前两个房间。
我们需要爬取的是主播名字('nickname')和头像('vertical_src')。
item
import scrapy
class DouyuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
nickname = scrapy.Field()
imagelink = scrapy.Field()
spider
这里使用了json包的方法去解析str字符串为dict。
import scrapy
import json
from douyu.items import DouyuItem
class DouyuspiderSpider(scrapy.Spider):
name = "DouyuSpider"
allowed_domains = ["douyucdn.cn"]
baseURL = 'http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset='
offset = 0
start_urls = [baseURL + str(offset)]
def parse(self, response):
# .load和磁盘交互,.loads处理字符串
data_list = json.loads(response.body.decode('utf-8'))['data']
if not len(data_list):
return
for data in data_list:
item = DouyuItem()
item['nickname'] = data['nickname']
item['imagelink'] = data['vertical_src']
yield item
self.offset += 20
yield scrapy.Request(self.baseURL + str(self.offset), callback=self.parse)
pipelines
取消settings.py注释,

这里面我们继承了一个新的用于下载二进制文件的管线类,并改写了两个方法,用于,
- 下载二进制文件
- 根据下载结果(成功与否)将图片重命名为主播名
下载文件的方法会自动读取settings.py的字段,而且这个字段默认setting.py是没有的,所以需要在文件中手动添加,位置无所谓,
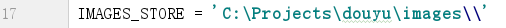
import os
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from douyu.settings import IMAGES_STORE
# 新的管线类,用于处理二进制文件
class DouyuPipeline(ImagesPipeline):
# 二进制下载,电影视频实际都可以,会自动调用download模组的函数
def get_media_requests(self, item, info):
image_link = item['imagelink']
yield scrapy.Request(image_link)
# 这个方法会在一次处理的最后调用(从返回item也可以推理出)
# result表示下载的结果状态
def item_completed(self, results, item, info):
# print(results)
# [(True, {'url': 'https://rpic.douyucdn.cn/acrpic/170827/3034164_v1319.jpg',
# 'checksum': '7383ee5f8dfadebf16a7f123bce4dc45', 'path': 'full/6faebfb1ae66d563476449c69258f2e0aa24000a.jpg'})]
image_path = [x['path'] for ok,x in results if ok]
os.rename(IMAGES_STORE + image_path[0], IMAGES_STORE + item['nickname'] + '.jpg')
return item
重命名函数os.rename比win下的重命名强多了,它可以对路径重命名达到修改文件位置的功效(内部原理贴近操作系统层面了,到底是os库的函数233)。
运行如下命令,
scrapy crawl DouyuSpider
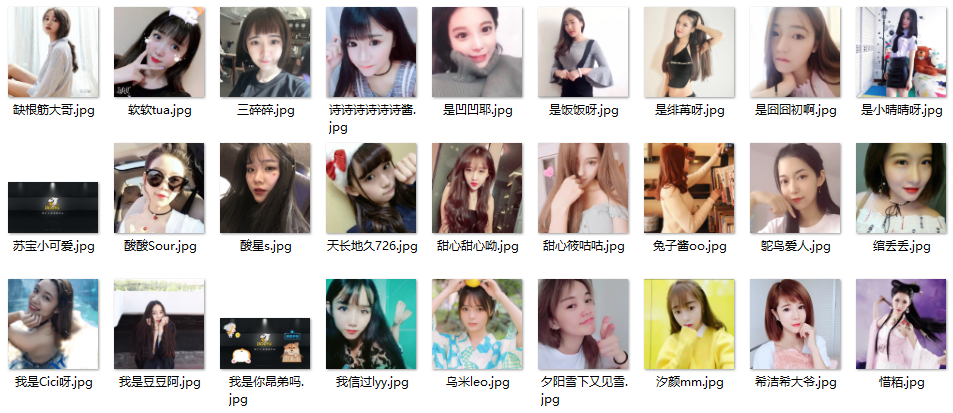
结束即可查看图片,结果和下面类似,