日常学习笔记
会的越多,不会的越多
戒浮戒躁,脚踏实地
记录和东哥、小海海、小灿灿一起奋斗的日子
java并发编程实践
01 | 可见性、原子性和有序性问题:并发编程Bug的源头
笔记
- 并发编程的三个问题
- 原子性 -> 一个操作是不可中断的,要么全部执行成功要么全部执行失败。
- 指令级别语义:CPU单个指令一定是原子性的。
- java语言语义:java中一个指令不代表是具备原子性的。java指令是对CPU指令的封装。(1 - n)
- 有序性 -> 程序按照代码顺序有序执行
- 编译期优化:在java编译期,JVM认为改变指令顺序不会影响结果的场景中(不违反happens-before),会进行编译期的指令重排
- CPU指令重排:为了解决MESI协议导致的CPU空闲,引入了指令重排机制。大大提高了CPU的利用率
- 可见性 -> 当前线程对共享变量的修改,对其它线程立即可见
- JMM语义:在JMM中线程对共享变量的修改对其它线程立即可见。
- CPU语义:一个内核对L1/l2缓存的M(modify)操作对其它S(share)该变量的内核可见。
- 可见性问题的根本来源:指令重排导致的CPU指令乱序执行。最终根源
- Store Buffere
- Invalidte Queue
- 可见性问题的根本来源:指令重排导致的CPU指令乱序执行。最终根源
- 原子性 -> 一个操作是不可中断的,要么全部执行成功要么全部执行失败。
金句
在采用一项技术的同时,一定要清楚它带来的问题是什么,以及如何规避
举个例子,我们为了对系统实施监控,会引入例如pinpoint之类的AMP组件,解决了监控问题
的同时也带来了性能问题,比如对带宽的占用,增加了接口响应的延时等;再比如,微服务
架构是为了解决单体应用灵活性差等问题而出现,同时也带了了架构的复杂度,增加了服务
之间通信,数据隔离等问题。所以,一个技术在解决某个问题的同时可能带来新的问题,这样
我们可能又会为新的问题引入别的技术来处理,这是个不断循环的过程。因此,我们在评估
一项技术的时候,需要充分考虑其负面影响,怎么权衡利弊,实现利益最大化。
CPU --> 三级缓存 --> MESI协议 --> 指令重排
02 | Java内存模型:看Java如何解决可见性和有序性问题
笔记
- java内存模型
- JMM是JVM兼容不同的CPU架构的基础。为了屏蔽底层硬件的差异,向开发者提供统一的接口,故诞生了JMM
- JMM只是规范,JMM只是规范,JMM只是规范
- JVM对JMM的实现,才是常见的堆、栈、方法区等一些耳熟能详的名词
- 可见性、有序性的根本解决方案
- 程序员:对CPU缓存、编译器等按需禁用缓存以及编译优化
- 方法:volatile/synchronized/final
- 以上三种方法是java提供给程序员“按需”禁止缓存及编译优化的手段。
- 方法:volatile/synchronized/final
- JVM:happens-before原则
在JVM可预见的场景中禁止CPU缓存、编译器优化- 程序次序规则
- 在一个线程中,前面的操作总是对后面操作可见
- 锁定规则
- 一个unlock操作先行发生于后面对这个锁的lock操作(先释放,才能加锁)
- 传递性规则
- A happens-before B B happens-before C 则 A happens-before C (以前理解不到位)
class VolatileExample { int x = 0; volatile boolean v = false; public void writer() { x = 42; v = true; } public void reader() { if (v == true) { // 这里x会是多少呢? } } } - 线程start规则
- start前的操作,总是对被start的操作可见。它是指主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作。
Thread B = new Thread(()->{ // 主线程调用B.start()之前 // 所有对共享变量的修改,此处皆可见 // 此例中,var==77 }); // 此处对共享变量var修改 var = 77; // 主线程启动子线程 B.start(); - 线程 join() 规则
- 这条是关于线程等待的。它是指主线程 A 等待子线程 B 完成(主线程 A 通过调用子线程 B 的 join() 方法实现),
当子线程 B 完成后(主线程 A 中 join() 方法返回),主线程能够看到子线程的操作。当然所谓的“看到”,指的是对共享变量的操作。
Thread B = new Thread(()->{ // 此处对共享变量var修改 var = 66; }); // 例如此处对共享变量修改, // 则这个修改结果对线程B可见 // 主线程启动子线程 B.start(); B.join() // 子线程所有对共享变量的修改 // 在主线程调用B.join()之后皆可见 // 此例中,var==66 - 这条是关于线程等待的。它是指主线程 A 等待子线程 B 完成(主线程 A 通过调用子线程 B 的 join() 方法实现),
- 程序次序规则
- 程序员:对CPU缓存、编译器等按需禁用缓存以及编译优化
理解
- 文中的禁用CPU缓存,更深层次的理解见
- store buffer
- Invalidate Queue
- volatile/synchronized/final等是java提供给程序员禁止指令重排和禁用缓存的工具
- CPU为了提高利用率需要指令重排,但是在一些场景中指令重排会导致一些意想不到的错误。这时候需要程序员来发现问题并给出了解决问题的手段
- 重点理解JMM是一种规范、不能混淆JVM对JMM的实现
03 | 互斥锁(上):解决原子性问题
笔记
- 原子性问题到底该如何解决呢
- 原子性问题的源头是线程切换,如果能够禁用线程切换那不就能解决这个问题了吗?而操作系统做线程切换是依赖 CPU 中断的,所以禁止 CPU 发生中断就能够禁止线程切换。
- 同一时刻只有一个线程执行”这个条件非常重要,我们称之为互斥。如果我们能够保证对共享变量的修改是互斥的,那么,无论是单核 CPU 还是多核 CPU,就都能保证原子性了。
- synchronized
- synchronized属于重量级锁,性能不高,在锁竞争激烈的场所不建议使用
- synchronized好处在于简单易用,绝对不会unlock
- 锁和受保护资源的关系
- 受保护资源和锁之间的关联关系是 N:1 的关系
重点
- synchronized锁膨胀过程
- synchronized 对象头 monitor
- long类型的并发读写问题(long64位 -- 32位操作系统)
金句
单核时代通过控制线程的切花就可以保证原子性,但是在多核时代,单纯的控制线程切换是无法保证原子性的,需要通过锁的互斥来
保证高并发场景下的原子性。
04 | 互斥锁(下):如何用一把锁保护多个资源
笔记
- 保护没有关联关系的多个资源
- 用不同的锁对受保护资源进行精细化管理,能够提升性能。这种锁还有个名字,叫细粒度锁
- 保护有关联关系的多个资源
- 锁能覆盖所有受保护资源
- 对象锁无法解决这个问题,因为会产生,我家的锁锁住别人家的资源的情况
- 正确姿势是采用类锁(性能有待优化)
理解
- 以前没考虑过也没遇到过 同一把锁管理多个资源的情况,以后在用锁的场景需要注意。
05 | 一不小心就死锁了,怎么办
笔记
- 死锁的专业定义
一组线程因为竞争共享资源而陷入互相等待,导致“永久”阻塞的现象。class Account { private int balance; // 转账 void transfer(Account target, int amt){ // 锁定转出账户 synchronized(this){ //① // 锁定转入账户 synchronized(target){ //② if (this.balance > amt) { this.balance -= amt; target.balance += amt; } } } } } - 在现实中寻找答案
我们试想在古代,没有信息化,账户的存在形式真的就是一个账本,而且每个账户都有一个账本,这些账本都统一存放在文件架上。银行柜员在给我们做转账时,要去文件架上把转出账本和转入账本都拿到手,然后做转账- 文件架上恰好有转出账本和转入账本,那就同时拿走;
- 如果文件架上只有转出账本和转入账本之一,那这个柜员就先把文件架上有的账本拿到手,同时等着其他柜员把另外一个账本送回来;
- 转出账本和转入账本都没有,那这个柜员就等着两个账本都被送回来。
死锁产生
同一时刻A柜员拿到了入账账本,B柜员拿到了出账账本,A等待出账账本,B等待入账账本。AB柜员就会陷入“永久”等待。这就是死锁。
- 粗粒度锁
解决上述问题,可以采用粗粒度锁,也就是类锁,但是类锁带来的是性能问题。 - 细粒度锁
- 优点:使用细粒度锁可以提高并行度,是性能优化的有效手段。
- 风险:机会和风险是并存的。细粒度锁可能导致死锁。
- 如何预防死锁
解决死锁最好的办法是预防死锁,将其扼杀在摇篮里。- 产生死锁的四个条件
- 互斥,共享资源X和Y只能被一个线程占用
- 占有且等待,线程T1占有X资源,在等待资源Y的同时,不释放资源X。
- 不可抢占,其他线程不能强行抢占线程T1占有的资源
- 循环等待,线程T1等待线程T2占有的资源,线程T2等待线程T1占有的资源,就是循环等待
- 解决死锁的思路就很简单了,就是破坏以上一个条件就不会造成死锁
- 破坏占用且等待条件:一次性申请所有的资源
- example:不允许柜员直接在文件架上拿账本,而是增加管理员,柜员拿账本需要通过管理员来审核。比如,A柜员需要拿进账
管理员发现文件架上没有出账账本,所以不允许柜员只拿进账账本。这样就解决了占用且等待问题。
- example:不允许柜员直接在文件架上拿账本,而是增加管理员,柜员拿账本需要通过管理员来审核。比如,A柜员需要拿进账
- 破坏不可抢占条件:核心是要能够主动释放它占有的资源
- 这一点 synchronized 是做不到的。因为synchronized一旦申请不到资源就会进入阻塞状态
进入阻塞态就以为什么也干不了,也释放不了线程占用的资源。 - ReetrentLock 可以解决这个问题
- 这一点 synchronized 是做不到的。因为synchronized一旦申请不到资源就会进入阻塞状态
- 破坏循环等待条件:对资源排序,然后按序申请资源
- 我们假设每个账户都有不同的属性 id,这个 id 可以作为排序字段,申请的时候,我们可以按照从小到大的顺序来申请
class Account { private int id; private int balance; // 转账 void transfer(Account target, int amt){ Account left = this; //① Account right = target; //② if (this.id > target.id) { //③ left = target; //④ right = this; //⑤ } //⑥ // 锁定序号小的账户 synchronized(left){ // 锁定序号大的账户 synchronized(right){ if (this.balance > amt){ this.balance -= amt; target.balance += amt; } } } } }
- 破坏占用且等待条件:一次性申请所有的资源
- 产生死锁的四个条件
金句
当我们在编程世界里遇到问题时,应不局限于当下,可以换个思路,向现实世界要答案,利用现实世界的模型来构思解决方案,
这样往往能够让我们的方案更容易理解,也更能够看清楚问题的本质。
用细粒度锁来锁定多个资源时,要注意死锁的问题。这个就需要你能把它强化为一个思维定势,遇到这种场景,
马上想到可能存在死锁问题。当你知道风险之后,才有机会谈如何预防和避免,因此,识别出风险很重要
我们在选择具体方案的时候,还需要评估一下操作成本,从中选择一个成本最低的方案。
收获
while(true)循环是不是应该有个timeout,避免一直阻塞下去?
加超时在项目中非常实用。
06 | 用“等待-通知”机制优化循环等待
笔记
- 问题:05中破坏占用且等待条件,while循环会浪费CPU资源
当并发冲突增加,可能上述while循环会循环上万次,浪费CPU资源// 一次性申请转出账户和转入账户,直到成功 while(!actr.apply(this, target)){...}; - 方案:等待-通知机制
- 05中解决占用且等待条件,其实根本原因在于所有线程都在盲目申请,而不是等到“机会”合适的时候再申请。所谓来得早不如来得巧
- 使用 synchronized, wait(), notify(), notifyAll()实现等待-通知机制
- 这个等待队列和互斥锁是一对一的关系,每个互斥锁都有自己独立的等待队列
- notify() 只能保证在通知时间点,条件是满足的。而被通知线程的执行时间点和通知的时间点基本上不会重合,所以当线程执行的时候,很可能条件已经不满足了(保不齐有其他线程插队)
//单例
class Allocator {
private List<Object> als;
// 一次性申请所有资源
synchronized void apply(
Object from, Object to){
// 经典写法 范式
while(als.contains(from) ||
als.contains(to)){
try{
wait();
}catch(Exception e){
}
}
als.add(from);
als.add(to);
}
// 归还资源
synchronized void free(
Object from, Object to){
als.remove(from);
als.remove(to);
notifyAll();
}
}
//测试方法
public class Test{
public void test(){
//加锁
allocator.apply(from, to);
//TODO ...
//释放锁
allocator.free();
}
}
收获
- 尽量使用notifyAll
- notify() 是会随机地通知等待队列中的一个线程,而 notifyAll() 会通知等待队列中的所有线程。从感觉上来讲,应该是 notify() 更好一些,因为即便通知所有线程,也只有一个线程能够进入临界区。但那所谓的感觉往往都蕴藏着风险,实际上使用 notify() 也很有风险,它的风险在于可能导致某些线程永远不会被通知到。
假设我们有资源 A、B、C、D,线程 1 申请到了 AB,线程 2 申请到了 CD,此时线程 3 申请 AB,会进入等待队列(AB 分配给线程 1,线程 3 要求的条件不满足),线程 4 申请 CD 也会进入等待队列。我们再假设之后线程 1 归还了资源 AB,如果使用 notify() 来通知等待队列中的线程,有可能被通知的是线程 4,但线程 4 申请的是 CD,所以此时线程 4 还是会继续等待,而真正该唤醒的线程 3 就再也没有机会被唤醒了。所以除非经过深思熟虑,否则尽量使用 notifyAll()。
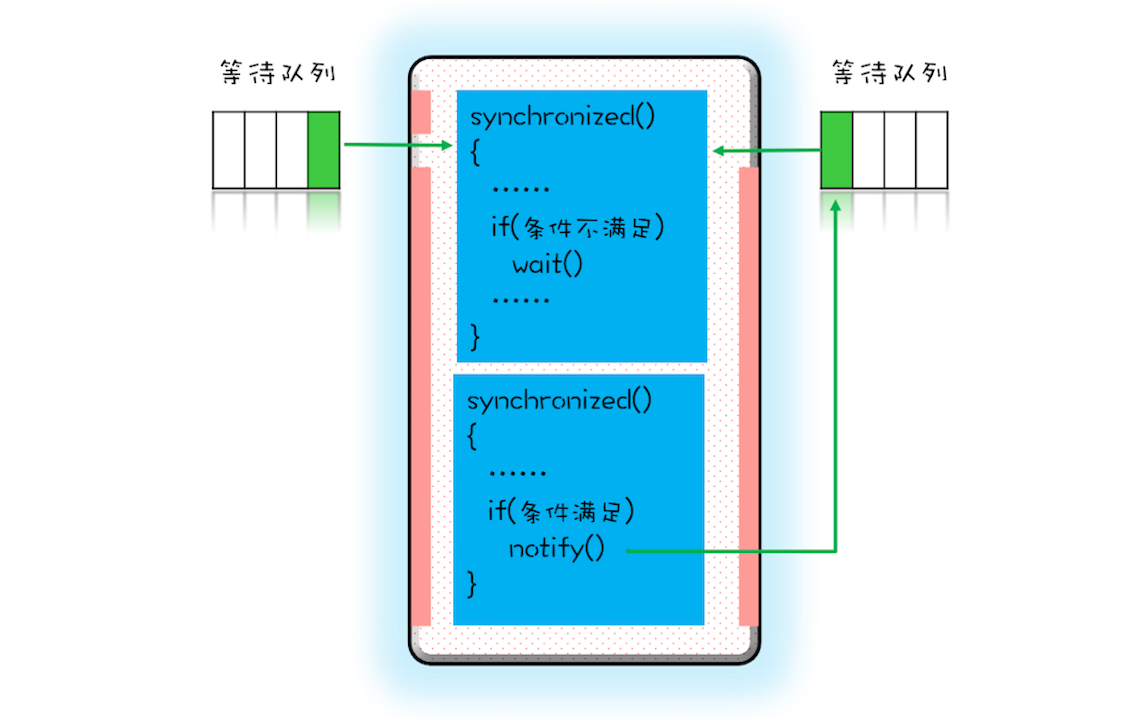
notify工作原理图
- notify() 是会随机地通知等待队列中的一个线程,而 notifyAll() 会通知等待队列中的所有线程。从感觉上来讲,应该是 notify() 更好一些,因为即便通知所有线程,也只有一个线程能够进入临界区。但那所谓的感觉往往都蕴藏着风险,实际上使用 notify() 也很有风险,它的风险在于可能导致某些线程永远不会被通知到。
- 每个互斥锁都有各自独立的等待池
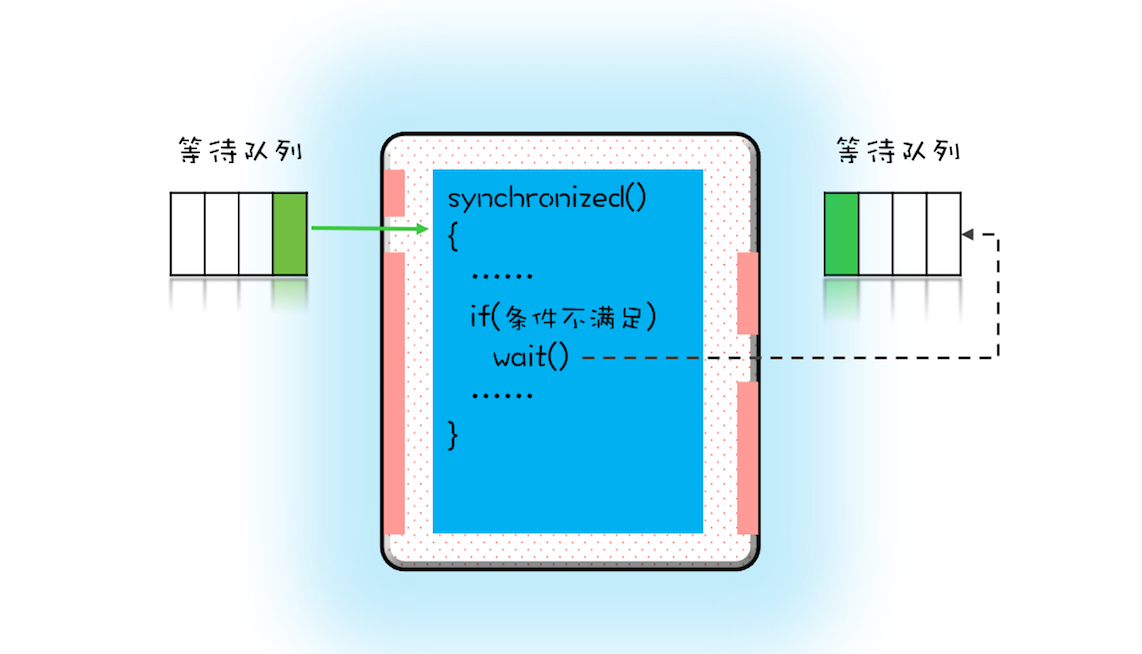
- wait和sleep的区别
wait()方法与sleep()方法的不同之处在于,wait()方法会释放对象的“锁标志”。当调用某一对象的wait()方法后,会使当前线程暂停执行,并将当前线程放入对象等待池中,直到调用了notify()方法后,将从对象等待池中移出任意一个线程并放入锁标志等待池中,只有锁标志等待池中的线程可以获取锁标志,它们随时准备争夺锁的拥有权。当调用了某个对象的notifyAll()方法,会将对象等待池中的所有线程都移动到该对象的锁标志等待池。
sleep()方法需要指定等待的时间,它可以让当前正在执行的线程在指定的时间内暂停执行,进入阻塞状态,该方法既可以让其他同优先级或者高优先级的线程得到执行的机会,也可以让低优先级的线程得到执行机会。但是sleep()方法不会释放“锁标志”,也就是说如果有synchronized同步块,其他线程仍然不能访问共享数据。- wait释放锁
- sleep不释放锁
07 | 安全性、活跃性以及性能问题
笔记
- 并发编程的问题
- 微观上:原子性、可见性、有序性
- 宏观上:安全性、活跃性、性能
- 安全性问题
- 理论知识
- 什么是线程安全?本质上就是正确性:程序按照我们的期望执行
- 理论上线程安全的程序就是要避免原子性、可见性、有序性问题
- 需要着重的关注线程安全性的场景:存在共享数据并且该数据会发生变化,通俗的讲就是多个线程同时读写同一个数据
- 数据竞争:当多个线程同时修改一个共享数据时,导致的并发bug(其实就是线程安全性)
public class Test { private long count = 0; void add10K() { int idx = 0; while(idx++ < 10000) { count += 1; } } }- 竞态条件:指的是线程执行的结果依赖线程执行的顺序
public class Test { private long count = 0; synchronized long get(){ return count; } synchronized void set(long v){ count = v; } void add10K() { int idx = 0; while(idx++ < 10000) { set(get()+1) //当两个线程同时运行到get()方法时,get()方法先后(有sync锁)0,count结果为1。当先后执行时,count结果为2 } } }- 解决方案 -- 互斥(锁)
CPU 提供了相关的互斥指令,操作系统、编程语言也会提供相关的 API。从逻辑上来看,我们可以统一归为:锁
- 理论知识
- 活跃性问题
所谓活跃性问题,指的是某个操作无法执行下去。我们常见的“死锁”就是一种典型的活跃性问题,当然除了死锁外,还有两种情况,分别是“活锁”和“饥饿”- 活锁:互相“谦让”的例子。线程因为总是同时的进行竞争而导致的互相等待的现象。
- 解决方案:让线程等待一个随机的时间。避免“同时”即可
- 死锁:一组线程线程因为竞争共享数据而陷入永久性等待,导致线程“永久”的阻塞。
- 解决方案:破坏四个条件即可:互斥、占用且等待、不可抢占、循环等待
- 饥饿:所谓“饥饿”指的是线程因为无法访问所需资源而无法执行下去的情况
- 解决方案
- 公平的分配资源
- 保证资源充足
- 避免线程长时间持有锁
- 公平锁,先来先得
- 解决方案
- 活锁:互相“谦让”的例子。线程因为总是同时的进行竞争而导致的互相等待的现象。
- 性能问题
- 尽量采用无锁方式 乐观锁(CAS) 本地化存储(ThreadLocal) copy-on-write
- 尽量减少线程持有锁的时间
- 优化锁粒度 联想1.8前后ConcurrentHashMap的锁设计
总结
- 安全性方面注意数据竞争 竞态条件问题
- 活跃性方面注意死锁 活锁 饥饿等问题
- 性能方面尽量采用无锁CAS,优化锁粒度,减少锁持有时间
08 | 管程:并发编程的万能钥匙
笔记
- 管程和信号量
- 管程和信号量是同步的,所谓同步也就是管程能实现信号量,信号量也能实现管程
- 什么是管程
- 管程是一个概念
- 在java中每一个对象都绑定着一个管程(信号量)
- 线程访问加锁对象其实就是去拥有一个监视器的过程。
- 线程访问共享变量的过程其实就是申请拥有监视器的过程。
- 监视器至少有两个等待队列。
总结起来就是,管程就是一个对象监视器。任何线程想要访问该资源,就要排队进入监控范围。进入之后,接受检查,不符合条件,则要继续等待,直到被通知,然后继续进入监视器。
- java中的管程
- 1.5之前:①synchronized + wait、notify、notifyAll
- 1.5之后:②lock + condition
- 区别
- ①只支持一种一个条件变量,即wait,调用wait时将会将其加入到等待队列。被notify时会随机通知一个线程加入到锁的等待池
- ②相对①condition支持中断和增加了等待时间
- 三种实现管程的模型
- HASEN:执行完,再去唤醒另外一个线程。能够保证线程的执行
- HOARE:是中断当前线程,唤醒另外一个线程,执行玩再去唤醒,也能够保证完成。
- MESA:是进入等待队列,不一定有机会能够执行(公平竞争公平 == 容易饥饿)
09 | Java线程(上):Java线程的生命周期
笔记
- 通用的五种线程状态
- 初始状态
- 可运行状态
- 运行状态
- 休眠状态
- 终止状态
- java线程的五种状态
- new(初始化)
- runnable(可运行/运行状态)
- blocked(阻塞状态)
- waiting(无限时等待)
- timed_waiting(有时限等待)
- terminated(终止)
- RUNNABLE 与 BLOCKED 的状态转换
- 只有一种场景会触发这种转换,就是线程等待 synchronized 的隐式锁。synchronized 修饰的方法、代码块同一时刻只允许一个线程执行,其他线程只能等待,这种情况下,等待的线程就会从 RUNNABLE 转换到 BLOCKED 状态。而当等待的线程获得 synchronized 隐式锁时,就又会从 BLOCKED 转换到 RUNNABLE 状态
- RUNNABLE 与 WAITING 的状态转换
- 第一种场景,获得 synchronized 隐式锁的线程,调用无参数的 Object.wait() 方法
- 第二种场景,调用无参数的 Thread.join() 方法
- 第三种场景,调用 LockSupport.park() 方法。其中的 LockSupport 对象,也许你有点陌生,其实 Java 并发包中的锁,都是基于它实现的
- RUNNABLE 与 TIMED_WAITING 的状态转换
- 调用带超时参数的 Thread.sleep(long millis) 方法
- 获得 synchronized 隐式锁的线程,调用带超时参数的 Object.wait(long timeout) 方法
- 调用带超时参数的 Thread.join(long millis) 方法
- 调用带超时参数的 LockSupport.parkNanos(Object blocker, long deadline) 方法
- 调用带超时参数的 LockSupport.parkUntil(long deadline) 方法
- 从 NEW 到 RUNNABLE 状态
- Java 刚创建出来的 Thread 对象就是 NEW 状态,而创建 Thread 对象主要有两种方法
- RUNNABLE 到 TERMINATED 状态
- 正常结束
- interrupt()
10 | Java线程(中):创建多少线程才是合适的?
笔记
-
为什么要使用多线程?
- 使用多线程,本质上就是提升程序性能。
- 两个指标
- 延迟指的是发出请求到收到响应这个过程的时间;延迟越短,意味着程序执行得越快,性能也就越好。
- 吞吐量指的是在单位时间内能处理请求的数量;吞吐量越大,意味着程序能处理的请求越多,性能也就越好
- 本质上就是将硬件的性能发挥到极致
-
多线程的应用场景
- I/O密集型
- CPU密集型
-
评论区
- 个人觉得公式话性能问题有些不妥,定性的io密集或者cpu密集很难在定量的维度上反应出性能瓶颈,而且公式上忽略了线程数增加带来的cpu消耗,性能优化还是要定量比较好,这样不会盲目,比如io已经成为了瓶颈,增加线程或许带来不了性能提升,这个时候是不是可以考虑用cpu换取带宽,压缩数据,或者逻辑上少发送一些。最后一个问题,我的答案是大部分应用环境是合理的,老师也说了是积累了一些调优经验后给出的方案,没有特殊需求,初始值我会选大家都在用伪标准
11 | Java线程(下):为什么局部变量是线程安全的?
笔记
- 为什么局部变量不存在线程安全问题
- 从线程栈解释:局部变量在线程的独享栈中
- 没有共享就没有伤害
- 线程安全问题的解决方案之一
- 线程封闭
- ThreadLocal
- 注意ThreadLocal的内存泄漏问题
总结
- new出来的对象都在堆中的合理解释
- 对象在堆中,但是对象的句柄(引用或者指针)在栈中
- 没有共享就没有伤害
- 递归注意深度,容易导致栈内存溢出
- ThreadLocal的内存泄漏问题
- Spring对数据源连接池的抽象 ThreadLocal实现的
12 | 如何用面向对象思想写好并发程序?
笔记
- 三个思路
- 封装共享变量
- 将共享变量作为对象属性封装在内部,对所有公共方法制定并发访问策略
- 识别共享变量间的约束条件
public class SafeWM { // 库存上限 private final AtomicLong upper = new AtomicLong(0); // 库存下限 private final AtomicLong lower = new AtomicLong(0); // 设置库存上限 void setUpper(long v){ upper.set(v); } // 设置库存下限 void setLower(long v){ lower.set(v); } // 省略其他业务代码 }* 约束条件,决定了并发访问策略 * 忽略了一个约束条件:下限 < 上限 * 不安全的一个例子public class SafeWM { // 库存上限 private final AtomicLong upper = new AtomicLong(0); // 库存下限 private final AtomicLong lower = new AtomicLong(0); // 设置库存上限 void setUpper(long v){ // 检查参数合法性 if (v < lower.get()) { throw new IllegalArgumentException(); } upper.set(v); } // 设置库存下限 void setLower(long v){ // 检查参数合法性 if (v > upper.get()) { throw new IllegalArgumentException(); } lower.set(v); } // 省略其他业务代码 }当setUpper(5) 和 setLower(7)同时发生时,会发生upper = 5 lower = 7 * 着重注意if else语句造成的竞态条件 - 封装共享变量
- 制定并发访问策略
- 避免共享
- 不变模式(不可变对象/变量)
- 管程/并发工具(JUC)
- 优先考虑java的并发包,一般能解决绝大多数并发问题
- 迫不得已时再考虑“低级”原语:synchronized、Lock、Semaphore,使用时千万小心
- 避免过早优化,首先保证安全,等到确实遇到性能瓶颈的时候,再考虑优化
14 | Lock和Condition(上):隐藏在并发包中的管程
笔记
- 并发编程的两个核心问题
- 互斥-同一个时刻只能有一个线程可以访问共享资源
- 同步-线程之间如何通信、协作
- Java中管程的两个实现--java线程的两种协作方式
- synchronized + wait + notify
- synchronized实现互斥
- wait + notify实现同步
- lock + Condition
- lock实现互斥
- condition实现同步
- synchronized + wait + notify
- 再造管程的理由
- synchronized存在的问题
- 1.5之前性能不够好 + 容易膨胀为重量级锁
- 死锁问题无法破坏不可抢占条件
- synchronized存在的问题
- 设计一个锁能解决不可抢占条件
- 能够响应中断
- 支持超时
- 非阻塞的获取锁
// 支持中断的API void lockInterruptibly() throws InterruptedException; // 支持超时的API boolean tryLock(long time, TimeUnit unit) throws InterruptedException; // 支持非阻塞获取锁的API boolean tryLock(); - 如何保证可见性
- synchronized
- happens-before中有一个锁规则,保证了synchronized的可见性
- Lock
- 利用了 volatile 相关的 Happens-Before 规则
ReentrantLock 内部持有一个volatile的变量
class SampleLock { volatile int state; // 加锁 lock() { // 省略代码无数 state = 1; } // 解锁 unlock() { // 省略代码无数 state = 0; } } - 利用了 volatile 相关的 Happens-Before 规则
- synchronized
- 可重入锁
- 线程可以重复获取同一把锁
- ReentrantLock汉语意思就是可重入锁的含义
- 公平锁与非公平锁
- 公平锁:按照先来先得的原则,完全公平。其实就是排队等待
- 非公平锁:公平竞争锁,每次竞争所有线程获取锁的机会是均等待。(为什么叫非公平锁呢?因为运气不好的可能造成线程饥饿)
15 | Lock和Condition(下):Dubbo如何用管程实现异步转同步?
笔记
- 相对synchronized + wait + notify/ReentrantLock + Condition的优势
- Lock&Condition 实现的管程是支持多个条件变量的,这是二者的一个重要区别。
- sync + wait只能支持一个条件,因为条件都是绑定到monitor上的,每一个锁只有一个monitor
- 如何实现一个阻塞队列
- 阻塞队列需要两个条件:满阻塞/空阻塞
- sync管程只能实现一个阻塞,因为其只能支持一个条件变量
- lock + Condition 可以支持多个条件变量
- 复习
- sync + wait + notify + notifyAll
- lock + Condition + await + signal + signalAll
public class BlockedQueue<T>{ final Lock lock = new ReentrantLock(); // 条件变量:队列不满 final Condition notFull = lock.newCondition(); // 条件变量:队列不空 final Condition notEmpty = lock.newCondition(); // 入队 void enq(T x) { lock.lock(); try { while (队列已满){ // 等待队列不满 notFull.await(); } // 省略入队操作... //入队后,通知可出队 notEmpty.signal(); }finally { lock.unlock(); } } // 出队 void deq(){ lock.lock(); try { while (队列已空){ // 等待队列不空 notEmpty.await(); } // 省略出队操作... //出队后,通知可入队 notFull.signal(); }finally { lock.unlock(); } } }
- 阻塞队列需要两个条件:满阻塞/空阻塞
- Dubbo如何实现异步的RPC实现同步的等待结果
// 创建锁与条件变量 private final Lock lock = new ReentrantLock(); private final Condition done = lock.newCondition(); // 调用方通过该方法等待结果 Object get(int timeout){ long start = System.nanoTime(); lock.lock(); try { while (!isDone()) { done.await(timeout); long cur=System.nanoTime(); if (isDone() || cur-start > timeout){ break; } } } finally { lock.unlock(); } if (!isDone()) { throw new TimeoutException(); } return returnFromResponse(); } // RPC结果是否已经返回 boolean isDone() { return response != null; } // RPC结果返回时调用该方法 private void doReceived(Response res) { lock.lock(); try { response = res; if (done != null) { done.signal(); } } finally { lock.unlock(); } }
猜想
- Future应该也是通过 Lock + Condition实现的
- 明天看源码ArrayListBlockQueue/LinkedListBlockQueue,看二者如何实现的阻塞
16 | Semaphore:如何快速实现一个限流器?
笔记
- 信号量
- 互斥性
- Semaphore如何实现互斥。指定Semaphore的计数器为1,也就意味着同一个时刻只能有一个线程可以访问临界区资源
- 线程并行控制
- Semaphore如何控制并发。Semaphore通过计数器,控制访问临界区的线程不能超过计数器值。
- 互斥性
- 操作系统中也存在信号量--作用和java中的信号量也是相同的
- 操作系统利用信号量控制进程的并行
- Semaphore 的公平性
- 默认Semaphore是非公平的,同 ReentrantLock
- Semaphore提供了两个构造方法,如下所示,两个参数的构造方法,第二个参数可以指定公平性
- false:非公平,也就是公平竞争,容易饥饿
- true:公平,先来后到
public Semaphore(int permits) { sync = new NonfairSync(permits); } public Semaphore(int permits, boolean fair) { sync = fair ? new FairSync(permits) : new NonfairSync(permits); }
总结
- 信号量在 Java 语言里面名气并不算大,但是在其他语言里却是很有知名度的。Java 在并发编程领域走的很快,
重点支持的还是管程模型。 管程模型理论上解决了信号量模型的一些不足,主要体现在易用性和工程化方面,
例如用信号量解决我们曾经提到过的阻塞队列问题,就比管程模型麻烦很多。
17 | ReadWriteLock:如何快速实现一个完备的缓存?
笔记
- 管程和信号量都能解决所有并发问题了,JUC中还存在那么多并发工具?
- 分场景优化,提升易用性
- 什么是读写锁
- 读写锁普遍存在于各种语言,三条基本原则
- 允许多个线程同时读共享变量
- 统一时刻只允许一个线程写共享变量
- 如果一个写线程正在执行写操作,此时禁止读线程读共享变量(读锁和写锁是互斥的)
- 对比mysql(以下两条结论都建立在两个独立的事务中)
- 在read-uncommitted、read-committed、repeatable-read级别下,对同一行数据的写不会阻塞读。原因在于在以上三个隔离级别中,是通过MVCC控制的。当然如果采用当前读(lock in share mode读读不互斥,读写互斥。ps:for update读读互斥、读写互斥)则可以产生阻塞
- 在serializable隔离级别下,同读写锁的第三条读写互斥规则。原因是在serializable级别下所有的读都是当前读(互斥读)。
- mysql 演示
-- session1 -- 查询事务级别 select @@tx_isolation; -- 设置事务级别 set session transaction isolation level read committed; -- 开启事务 start transaction; select * from sys_test where id = 2 ; -- 加上lock in share mode同读写锁的读写互斥; -- 提交事务 commit; -- session2 set session transaction isolation level read committed; start transaction; update sys_test set name = '55' where id = 2; select * from sys_test where id = 2; commit;
- 对比mysql(以下两条结论都建立在两个独立的事务中)
- 读写锁普遍存在于各种语言,三条基本原则
- ReadWriteLock读写锁
- 读多写少的场景
- 缓存
- 读写锁的升级与降级
- ReadWriteLock不支持锁升级(会饥饿),但是支持锁降级。
理解
- ReadWriteLock读写锁如果不互斥,也就没必要存在读锁了。
- 类似mysql,如果读写不互斥,则没必要加读锁。
- 读锁存在的意义在于第三条规则。写同时阻塞读,可以保证读到的一定是最新的。
- mysql在前三个隔离级别下默认读是快照读(无锁读),所以才存在了脏读、不可重复度、幻读。所以解决以上三个问题的终极方法就是所有读都采用当前读(锁读)、当然这会影响性能,不建议使用。
18 | StampedLock:有没有比读写锁更快的锁?
笔记
- StampedLock 和 ReadWriteLock的区别
- ReadWriteLock 支持两种模式(读读不互斥,写写互斥,读写互斥)
- 读锁
- 写锁
- StampedLock 支持三种模式
- 写锁 语义同ReadWriteLock的写锁
- 悲观读锁 语义同ReadWriteLock的读锁
- 乐观读锁 乐观锁-无锁,性能更好
- ReadWriteLock 支持两种模式(读读不互斥,写写互斥,读写互斥)
- StampedLock 锁升级 (不是内部实现)
- 当 StampedLock 乐观读期间遇到写操作(validate(stamp)方法可判断)
- 注意事项
- StampedLock 是不可重入的
- 使用 StampedLock 一定不要调用中断操作,如果需要支持中断功能,一定使用可中断的悲观读锁 readLockInterruptibly() 和写锁 writeLockInterruptibly()。这个规则一定要记清楚。
范式
- 读范式
final StampedLock sl = new StampedLock(); // 乐观读 long stamp = sl.tryOptimisticRead(); // 读入方法局部变量 ...... // 校验stamp if (!sl.validate(stamp)){ // 升级为悲观读锁 stamp = sl.readLock(); try { // 读入方法局部变量 ..... } finally { //释放悲观读锁 sl.unlockRead(stamp); } } //使用方法局部变量执行业务操作 ...... - 写范式
long stamp = sl.writeLock(); try { // 写共享变量 ...... } finally { sl.unlockWrite(stamp); }
19 | CountDownLatch和CyclicBarrier:如何让多线程步调一致?
笔记
- CountDownLatch
- 主要用来解决一个线程等待多个线程的场景。可以类比旅游团团长要等待所有的游客到齐才能去下一个景点;
- 一旦计数器到0,再有线程调用await(),会直接通过。
- CyclicBarrier
- 一组线程之间互相等待。
- 具备自动重置功能。CyclicBarrier 的计数器是可以循环利用的。一旦计数器减到 0 会自动重置到你设置的初始值。
- CyclicBarrier 还可以设置回调函数
TODO
- CyclicBarrier实操
20 | 并发容器:都有哪些“坑”需要我们填?
笔记
- List
- LinkedList
- ArrayList
- 同步容器
- Vector
- 并发容器
- CopyOnWriteArrayList
- Set
- HashSet
- TreeSet
- LinkedSet
- 并发容器
- CopyOnWriteArraySet
- CopyOnWriteSkipListSet
- Map
- LinkedHashMap
- HashMap
- TreeMap
- 同步容器
- HashTable
- 并发容器
- ConcurrentHashMap
- ConcurrentSkipListMap
- Queue
- 非阻塞
- 线程不安全
- PriorityQueue
- LinkedList
- 线程安全
- 单端
- ConcurrentLinkedQueue
- 双端
- ConcurrentLinkedDeque
- 单端
- 线程不安全
- 阻塞
- ArrayBlockingQueue
- 出队入队同一把锁
- 底层数据结构:数组
- 有界
- 默认不保证线程安全性
- LinkedBlockingQueue
- 底层链表
- “有界”阻塞队列(长度为int长度)
- SynchronousQueue
- 无空间(不存储元素)
- LinkedTransferQueue
- 无界:由链表组成的无界TransferQueue
- PriorityBlockingQueue
- 支持优先级
- 无界
- DelayQueue
- 延时阻塞队列
- 无界
- ArrayBlockingQueue
- 非阻塞
- 对于Collections.synchronizedXXX()的方法要着重注意竞态条件问题
- 使用无界队列时要着重注意oom问题。例如:线程池的阻塞队列
21 | 原子类:无锁工具类的典范
笔记
-
CAS全程
- Compare And Swap
-
无锁方案的优点
- 无锁方案相对于互斥锁方案,最大的好处就是性能
- 互斥锁方案为了保证互斥性,需要执行加锁、解锁操作,而加锁、解锁操作本身就消耗性能;
同时拿不到锁的线程还会进入阻塞状态,进而触发线程切换,线程切换对性能的消耗也很大。
相比之下,无锁方案则完全没有加锁、解锁的性能消耗,同时还能保证互斥性,既解决了问题,又没有带来新的问题,可谓绝佳方案。
- 互斥锁方案为了保证互斥性,需要执行加锁、解锁操作,而加锁、解锁操作本身就消耗性能;
- 不会出现死锁
- 注意活锁和饥饿问题
- 无锁方案相对于互斥锁方案,最大的好处就是性能
-
无锁方案的实现原理
- 硬件支持-CPU为了解决并发问题,提供了CAS指令。作为一条 CPU 指令,CAS 指令本身是能够保证原子性的。
- CAS的使用一般都伴随着自旋
-
ABA问题
- 解决方案
- 理论上增加时间戳或者版本号都可以实现,JDK采用的是使用版本号。
- 解决方案
-
单纯的累加操作,使用累加器相对原子化的基本类型,性能更高
-
TODO实操
22 | Executor与线程池:如何创建正确的线程池?
- 线程池是一种生产者 - 消费者模式
- 线程池的使用方式 是 生产者
- 线程池本身是消费者
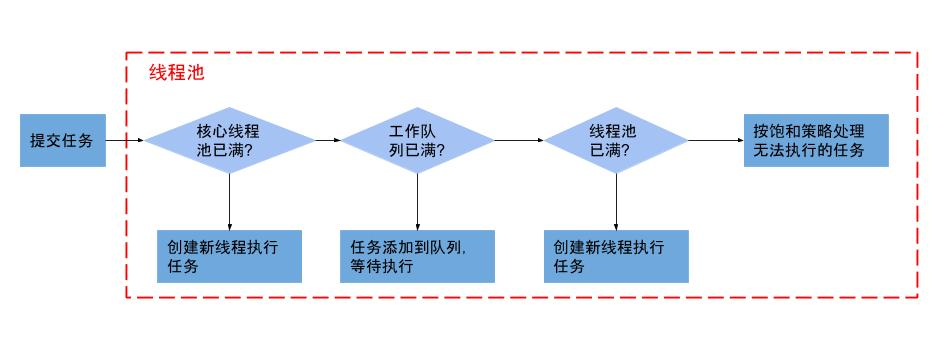
- ThreadPoolExecutor
ThreadPoolExecutor( int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)- corePoolSize 核心池大小
表示线程池保有的最小线程数。有些项目很闲,但是也不能把人都撤了,至少要留 corePoolSize 个人坚守阵地。- 当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理
- 核心线程会一直存活,即使没有任务需要执行
- 设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭
- maximumPoolSize 最大池
表示线程池创建的最大线程数。当项目很忙时,就需要加人,但是也不能无限制地加,最多就加到 maximumPoolSize 个人。当项目闲下来时,就要撤人了,最多能撤到 corePoolSize 个人。 - keepAliveTime & unit 空闲线程存活的时间
上面提到项目根据忙闲来增减人员,那在编程世界里,如何定义忙和闲呢?很简单,一个线程如果在一段时间内,都没有执行任务,说明很闲,keepAliveTime 和 unit 就是用来定义这个“一段时间”的参数。也就是说,如果一个线程空闲了keepAliveTime & unit这么久,而且线程池的线程数大于 corePoolSize ,那么这个空闲的线程就要被回收了。 - workQueue 工作队列
工作队列,当线程核心池已满,接下来来的任务就会被放到工作队列(阻塞队列)- 最好不要用无界队列,一旦业务量增加很容易OOM
- threadFactory
通过这个参数你可以自定义如何创建线程,例如你可以给线程指定一个有意义的名字。(PS:一般给线程池名字加前缀用这个方法) - handler 拒绝策略
当工作队列和线程池都满了,那么此时提交任务,线程池就会拒绝接收- CallerRunsPolicy:提交任务的线程自己去执行该任务。
- AbortPolicy:默认的拒绝策略,会 throws RejectedExecutionException
- DiscardPolicy:直接丢弃任务,没有任何异常抛出
- DiscardOldestPolicy:丢弃最老的任务,其实就是把最早进入工作队列的任务丢弃,然后把新任务加入到工作队列。
- 实现 RejectedExecutionHandler 接口 自定义拒绝策略,如果处理的任务不允许丢失,则可以和降级策略配合使用。
可以放数据库,放mq,redis,本地文件都可以,具体要看实际需求。
- corePoolSize 核心池大小
重点
- 注意事项
- 不要使用无界工作队列 最好不要使用 无界队列 因为业务量的突然增加很容易导致OOM
- 默认拒绝策略要慎重使用 实际开发任务中可以配合MQ和服务降级处理
- 线程池的异常处理 execute() 方法提交任务时,如果任务在执行的过程中出现运行时异常,会导致执行任务的线程终止;不过,最致命的是任务虽然异常了,但是你却获取不到任何通知,这会让你误以为任务都执行得很正常。
最好的办法还是捕获所有异常,按需处理 - 线程池的使用建议
- 业务隔离
- 压测确定队列长度或线程数
- 核心池大小
- 经验值
- IO密集型
- 2 * CPU + 1
- CPU密集型
- CPU + 1
- IO密集型
- 实践值
- 最佳线程数目 = (线程等待时间与线程CPU时间之比 + 1)* CPU数目
- 最佳值
- 压测
- 经验值
- 线程池流程
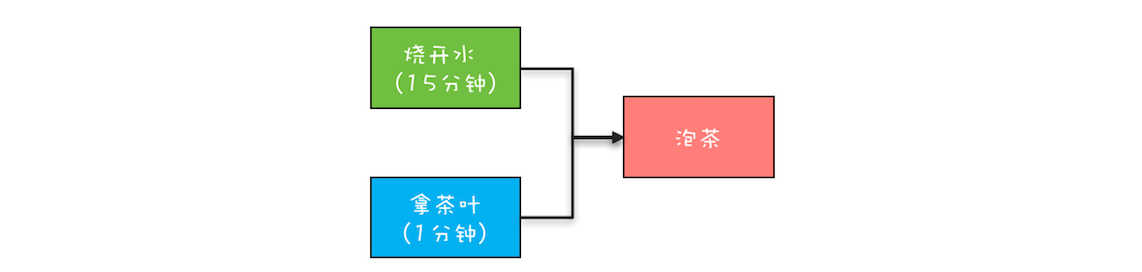
23 | Future:如何用多线程实现最优的“烧水泡茶”程序?
笔记
- 如何获取异步执行结果
- Future
- CountdownLatch
- join方法
- Future接口是一个获取异步结果的通用接口
- FutureTask是如何获取结果的
- FutureTask源码中状态标识 state
- NEW = 0;初始状态
- COMPLETING = 1;正在执行
- NORMAL = 2;
- EXCEPTIONAL = 3;
- CANCELLED = 4;
- INTERRUPTING = 5;
- INTERRUPTED = 6;
- 状态转换 TODO详细阅读源码理解
- NEW -> COMPLETING -> NORMAL
- NEW -> COMPLETING -> EXCEPTIONAL
- NEW -> CANCELLED
- NEW -> INTERRUPTING -> INTERRUPTED
- FutureTask源码中状态标识 state
- FutureTask的阻塞方法不像有些博客说的 Object#wait而是 LockSupport.park(this);对应的唤醒线程的方法 LockSupport.unpark(this);
TODO
- 总结java中实现获取异步结果的方式和工具
- 总结 异步转同步的方式
24 | CompletableFuture:异步编程没那么难
笔记
- CompletableFuture 的核心优势
- 无需手工维护线程,没有繁琐的手工维护线程的工作,给任务分配线程的工作也不需要我们关注;(对比FutureTask的实现)
- 语义更清晰,例如 f3 = f1.thenCombine(f2, ()->{}) 能够清晰地表述“任务 3 要等待任务 1 和任务 2 都完成后才能开始”;
- 代码更简练并且专注于业务逻辑,几乎所有代码都是业务逻辑相关的。
- 创建CompletableFuture对象
- runAsync(Runnable runnable) 不获取返回值的静态方法
- supplyAsync(Supplier supplier) 可获取返回值的方法 (ps:作用同Future),Supplier相对于Runnable,get方法可以获取返回值
- 以上两个方法可以指定线程池 (PS:CompletableFuture默认使用ForkJoinPool线程池)
//使用默认线程池 static CompletableFuture<Void> runAsync(Runnable runnable) static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) //可以指定线程池 static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor) static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor) - CompletableFuture实现的CompletionStage接口的作用
任务的时序关系管理- 串行关系

CompletionStage<R> thenApply(fn); CompletionStage<R> thenApplyAsync(fn); CompletionStage<Void> thenAccept(consumer); CompletionStage<Void> thenAcceptAsync(consumer); CompletionStage<Void> thenRun(action); CompletionStage<Void> thenRunAsync(action); CompletionStage<R> thenCompose(fn); CompletionStage<R> thenComposeAsync(fn); - 并行关系
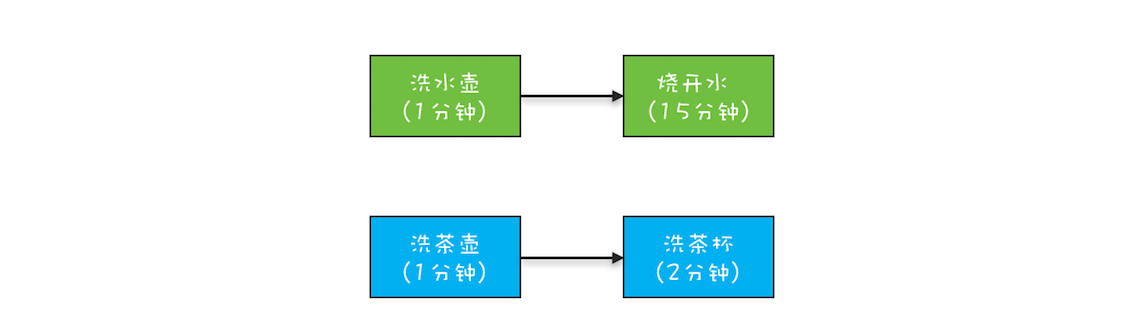
- 汇聚关系
- AND汇聚关系
CompletionStage<R> thenCombine(other, fn); CompletionStage<R> thenCombineAsync(other, fn); CompletionStage<Void> thenAcceptBoth(other, consumer); CompletionStage<Void> thenAcceptBothAsync(other, consumer); CompletionStage<Void> runAfterBoth(other, action); CompletionStage<Void> runAfterBothAsync(other, action); - OR 汇聚关系
CompletionStage applyToEither(other, fn); CompletionStage applyToEitherAsync(other, fn); CompletionStage acceptEither(other, consumer); CompletionStage acceptEitherAsync(other, consumer); CompletionStage runAfterEither(other, action); CompletionStage runAfterEitherAsync(other, action); - AND汇聚关系
- 串行关系
- 异常处理
CompletionStage exceptionally(fn); CompletionStage<R> whenComplete(consumer); CompletionStage<R> whenCompleteAsync(consumer); CompletionStage<R> handle(fn); CompletionStage<R> handleAsync(fn);
课后思考
- 创建采购订单的时候,需要校验一些规则,例如最大金额是和采购员级别相关的。有同学利用 CompletableFuture 实现了这个校验的功能,逻辑很简单,首先是从数据库中把相关规则查出来,然后执行规则校验。你觉得他的实现是否有问题呢?
//采购订单
PurchersOrder po;
CompletableFuture<Boolean> cf =
CompletableFuture.supplyAsync(()->{
//在数据库中查询规则
return findRuleByJdbc();
}).thenApply(r -> {
//规则校验
return check(po, r);
});
Boolean isOk = cf.join();
- 解答
- 没有进行异常处理,
- 要指定专门的线程池做数据库查询(读数据库属于io操作,应该放在单独线程池,避免线程饥饿)
- 如果检查和查询都比较耗时,那么应该像之前的对账系统一样,采用生产者和消费者模式,让上一次的检查和下一次的查询并行起来。
25 | CompletionService:如何批量执行异步任务?
- CompletionService 批量提交异步任务
// 创建线程池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 异步向电商S1询价
Future<Integer> f1 =
executor.submit(
()->getPriceByS1());
// 异步向电商S2询价
Future<Integer> f2 =
executor.submit(
()->getPriceByS2());
// 异步向电商S3询价
Future<Integer> f3 =
executor.submit(
()->getPriceByS3());
// 获取电商S1报价并保存
r=f1.get();
executor.execute(()->save(r));
// 获取电商S2报价并保存
r=f2.get();
executor.execute(()->save(r));
// 获取电商S3报价并保存
r=f3.get();
executor.execute(()->save(r));
- Future 实现“询价”程序
- 如上所示,需要一个个的get然后执行下一步操作,f1, f2, f3需要一次等待
// 创建阻塞队列
BlockingQueue<Integer> bq =
new LinkedBlockingQueue<>();
//电商S1报价异步进入阻塞队列
executor.execute(()->
bq.put(f1.get()));
//电商S2报价异步进入阻塞队列
executor.execute(()->
bq.put(f2.get()));
//电商S3报价异步进入阻塞队列
executor.execute(()->
bq.put(f3.get()));
//异步保存所有报价
for (int i=0; i<3; i++) {
Integer r = bq.take();
executor.execute(()->save(r));
}
- 阻塞队列的优化方案
- 如上所示 阻塞队列也能解决这种互相等待操作造成的资源浪费
- 利用 CompletionService 实现询价系统
- CompletionService 内部实现了一个阻塞队列,默认 LinkedListBlockingQueue(建议覆盖,因为默认的是无界的)
- CompletionService 会把Future对象放到阻塞队列中。
代码实现如下所示
// 创建线程池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 创建CompletionService
CompletionService<Integer> cs = new
ExecutorCompletionService<>(executor);
// 异步向电商S1询价
cs.submit(()->getPriceByS1());
// 异步向电商S2询价
cs.submit(()->getPriceByS2());
// 异步向电商S3询价
cs.submit(()->getPriceByS3());
// 将询价结果异步保存到数据库
for (int i=0; i<3; i++) {
Integer r = cs.take().get();// **TODO 验证是否是先执行完的,先入队**
executor.execute(()->save(r));
}
TODO 验证是否是先执行完的,先入队
- 利用 CompletionService 实现 Dubbo 中的 Forking Cluster
- Dubbo 中有一种叫做 Forking 的集群模式,这种集群模式下,支持并行地调用多个查询服务,只要有一个成功返回结果,整个服务就可以返回了。
// 创建线程池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 创建CompletionService
CompletionService<Integer> cs =
new ExecutorCompletionService<>(executor);
// 用于保存Future对象
List<Future<Integer>> futures =
new ArrayList<>(3);
//提交异步任务,并保存future到futures
futures.add(
cs.submit(()->geocoderByS1()));
futures.add(
cs.submit(()->geocoderByS2()));
futures.add(
cs.submit(()->geocoderByS3()));
// 获取最快返回的任务执行结果
Integer r = 0;
try {
// 只要有一个成功返回,则break
for (int i = 0; i < 3; ++i) {
r = cs.take().get();
//简单地通过判空来检查是否成功返回
if (r != null) {
break;
}
}
} finally {
//取消所有任务
for(Future<Integer> f : futures)
f.cancel(true);
}
// 返回结果
return r;
总结
- 当需要批量提交异步任务的时候建议你使用 CompletionService。CompletionService 将线程池 Executor 和阻塞队列 BlockingQueue 的功能融合在了一起,能够让批量异步任务的管理更简单。除此之外,CompletionService 能够让异步任务的执行结果有序化,先执行完的先进入阻塞队列,利用这个特性,你可以轻松实现后续处理的有序性,避免无谓的等待,同时还可以快速实现诸如 Forking Cluster 这样的需求。
- CompletionService 的实现类 ExecutorCompletionService,需要你自己创建线程池,虽看上去有些啰嗦,但好处是你可以让多个 ExecutorCompletionService 的线程池隔离,这种隔离性能避免几个特别耗时的任务拖垮整个应用的风险。
课后思考
- 本章使用 CompletionService 实现了一个询价应用的核心功能,后来又有了新的需求,需要计算出最低报价并返回,下面的示例代码尝试实现这个需求,你看看是否存在问题呢?
// 创建线程池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 创建CompletionService
CompletionService<Integer> cs = new
ExecutorCompletionService<>(executor);
// 异步向电商S1询价
cs.submit(()->getPriceByS1());
// 异步向电商S2询价
cs.submit(()->getPriceByS2());
// 异步向电商S3询价
cs.submit(()->getPriceByS3());
// 将询价结果异步保存到数据库
// 并计算最低报价
AtomicReference<Integer> m =
new AtomicReference<>(Integer.MAX_VALUE);
for (int i=0; i<3; i++) {
executor.execute(()->{
Integer r = null;
try {
r = cs.take().get();
} catch (Exception e) {}
save(r);
m.set(Integer.min(m.get(), r));
});
}
return m;
Copy
解答
- 以上代码无法保证三个线程 和 主线程 return m的顺序。可以加个CountDownLatch 来保证线程执行完成 再让主线程return。
26 | Fork/Join:单机版的MapReduce
笔记
- 从任务的角度看待并发编程
- 不难发现线程池、Future、CompletableFuture、CompletionService都是站在任务的角度看待并发编程,将视野扩大,不再将精力都浪费在线程的协作上
- 对于简单的并行任务,可以通过线程池+Future
- 如果任务之间有耦合关系,不管是AND或者OR,都可以CompletableFuture来解决
- 如果是批量任务,可以通过CompletionService来解决
- 并发编程关注的三个问题
- 互斥、
- 实现互斥的方案:锁:Synchronized、ReentrantLock、ReadWriteLock、StampedLock、、、
- 分工、
- 实现分工的方案:线程池、CompletionService、CompletableFuture
- 协作
- 线程协作的方案:管程:synchronized+wait+notify、Lock+Condition、CountDownLatch、CyclicBarrier
- 互斥、
- 从更高的视野看待并发编程
- 任务
- 线程任务调度方式:线程池+Future、CompletionService、CompletableFuture
- 任务
- 任务类型
- 并行任务:线程池 + Future + 阻塞队列、CompletableFuture
- 批量任务:CompletionService
- 聚合任务:CompletableFuture
- 分治任务:Fork/Join
- Fork/Join
- 理解
- Fork对应任务分解
- join对应任务聚合
- 工具
- ForkJoinPool
- 生产者-消费者模型
- 任务窃取当pool中的呃线程空闲了,会去窃取其他工作队列中的任务。TODO 确认是一个等待池还是每个线程有一个等待池
- ForkJoinTask
- 抽象实现类:RecursiveAction(compute()无返回值)
- 抽象实现类:RecursiveTask(compute()有返回值)
以上两者的关系类似 ThreadPoolExecutor 和 Runnable的关系
- ForkJoinPool
- 理解
总结
- Fork/Join 并行计算框架的核心组件是 ForkJoinPool。ForkJoinPool 支持任务窃取机制,能够让所有线程的工作量基本均衡,
不会出现有的线程很忙,而有的线程很闲的状况,所以性能很好。Java 1.8 提供的 Stream API 里面并行流也是以 ForkJoinPool
为基础的。不过需要你注意的是,默认情况下所有的并行流计算都共享一个 ForkJoinPool,
这个共享的 ForkJoinPool 默认的线程数是 CPU 的核数;如果所有的并行流计算都是 CPU 密集型计算的话,完全没有问题,
但是如果存在 I/O 密集型的并行流计算,那么很可能会因为一个很慢的 I/O 计算而拖慢整个系统的性能。
所以建议用不同的 ForkJoinPool 执行不同类型的计算任务。
27 | 并发工具类模块热点问题答疑
笔记
- 注意while(true)的问题
- 一般while(true)需要break条件,一般是超时时间,不然容易导致死循环
- while(true) & Lock和Condition里面的活锁问题
- notifyAll和signalAll
- 一般使用All比notify和signal更安全
- Semaphore 需要锁中锁
- Semaphore 允许多个线程访问一个临界区,这也是一把双刃剑,当多个线程进入临界区时,如果需要访问共享变量就会存在并发问题,所以必须加锁,也就是说 Semaphore 需要锁中锁。
- 个人理解,Semaphore不是一个锁,只是一个并发工具,所以遇到共享变量问题,依然是需要锁的
- 锁的申请和释放要成对出现
- 回调总要关心执行线程是谁
- 当看到回调函数的时候,一定问一问执行回调函数的线程是谁
- 共享线程池:有福同享就要有难同当
- 对于I/O密集型和CPU密集型的线程池要做业务隔离
- 线上问题定位的利器:线程栈 dump
- 善于利用JSP和jstack命令
28 | Immutability模式:如何利用不变性解决并发问题?
- 快速实现具备不可变性的类
- 将一个类所有的属性都设置成 final 的,并且只允许存在只读方法,那么这个类基本上就具备不可变性了
- 将类也设置成 final 保证不能通过继承修改该类的final属性
- String
- String 类是final的,就是为了保证线程安全的
- String 类的字符串替换操作 String#replace方法如何保证的线程安全?
- replace 是通过将替换后的值返回的形式"修改"的字符串,严格来说不能说是修改,而是生成了一个新的字符串。也就是生成了一个新的不可变String对象
- TODO,思考 String 类型为什么是存在常量池的
- 享元模式
享元模式本质上其实就是一个对象池,利用享元模式创建对象的逻辑也很简单:创建之前,首先去对象池里看看是不是存在;如果已经存在,就利用对象池里的对象;
如果不存在,就会新创建一个对象,并且把这个新创建出来的对象放进对象池里。- Long & Integer
- Long 这个类并没有照搬享元模式,Long 内部维护了一个静态的对象池,仅缓存了[-128,127]之间的数字,这个对象池在 JVM 启动的时候就创建好了,
而且这个对象池一直都不会变化,也就是说它是静态的。
- Long 这个类并没有照搬享元模式,Long 内部维护了一个静态的对象池,仅缓存了[-128,127]之间的数字,这个对象池在 JVM 启动的时候就创建好了,
- Long & Integer
- 使用 Immutability 模式的注意事项
- 对象的所有属性都是 final 的,并不能保证不可变性;
- 不可变对象也需要正确发布。
- 注意不可变的边界,如下所示,虽然Bar对象中Foo属性是final的,但是不能保证foo的属性不能被修改。
class Foo{
int age=0;
int name="abc";
}
final class Bar {
final Foo foo;
void setAge(int a){
foo.age=a;
}
}
总结
- 利用 Immutability 模式解决并发问题,也许你觉得有点陌生,其实你天天都在享受它的战果。Java 语言里面的 String 和 Long、Integer、Double
等基础类型的包装类都具备不可变性,这些对象的线程安全性都是靠不可变性来保证的。
Immutability 模式是最简单的解决并发问题的方法,建议当你试图解决一个并发问题时,可以首先尝试一下 Immutability 模式,看是否能够快速解决。 - 无状态
具备不变性的对象,只有一种状态,这个状态由对象内部所有的不变属性共同决定。其实还有一种更简单的不变性对象,那就是无状态。
无状态对象内部没有属性,只有方法。除了无状态的对象,你可能还听说过无状态的服务、无状态的协议等等。无状态有很多好处,最核心的一点就是性能。
在多线程领域,无状态对象没有线程安全问题,无需同步处理,自然性能很好;在分布式领域,无状态意味着可以无限地水平扩展,所以分布式领域里面性能的瓶颈一定不是出在无状态的服务节点上。 - 其实spring的 单例Bean 也是一种无状态的Bean ,也就是在单例Bean中最好不要定义共享变量,因为如果不加入线程安全的控制的话,读写一定能引起并发问题。
29 | Copy-on-Write模式:不是延时策略的COW
笔记
- Copy-on-Write 写时复制
- 基本思想-懒惰策略
- Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,
才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。
- Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,
- 基本思想-读写分离
- 当修改容器时,不首先修改原容器,而是将原容器copy一份,然后修改copy的容器,之后再将修改后的容器替换原容器。这样读和写操作的永远都是两个容器。
也就实现了读写分离。
- 当修改容器时,不首先修改原容器,而是将原容器copy一份,然后修改copy的容器,之后再将修改后的容器替换原容器。这样读和写操作的永远都是两个容器。
- 基本思想-懒惰策略
- Copy-on-Write 在操作系统中的应用
- 类 Unix 的操作系统中创建进程的 API 是 fork(),传统的 fork() 函数会创建父进程的一个完整副本,例如父进程的地址空间现在用到了 1G 的内存,那么 fork() 子进程的时候要复制父进程整个进程的地址空间(占有 1G 内存)给子进程,这个过程是很耗时的。而 Linux 中的 fork() 函数就聪明得多了,fork() 子进程的时候,并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间;只用在父进程或者子进程需要写入的时候才会复制地址空间,从而使父子进程拥有各自的地址空间。
- java中的 CopyOnWriteArrayList 和 CopyOnWriteArraySet是一种典型的空间换时间的做法
- java中的CopyOnWriteXXX容器采用的都是当元素发生变化,就进行copy操作。
- 存在的问题:当容器非常大,这样就会浪费很多的空间。
- java中的CopyOnWriteXXX容器采用的都是当元素发生变化,就进行copy操作。
总结
- 目前 Copy-on-Write 在 Java 并发编程领域知名度不是很高,很多人都在无意中把它忽视了,但其实 Copy-on-Write 才是最简单的并发解决方案。
它是如此简单,以至于 Java 中的基本数据类型 String、Integer、Long 等都是基于 Copy-on-Write 方案实现的。Copy-on-Write 是一项非常通用的技术方案,
在很多领域都有着广泛的应用。不过,它也有缺点的,那就是消耗内存,每次修改都需要复制一个新的对象出来,好在随着自动垃圾回收(GC)
算法的成熟以及硬件的发展,这种内存消耗已经渐渐可以接受了。所以在实际工作中,如果写操作非常少,那你就可以尝试用一下 Copy-on-Write,效果还是不错的。
思考题
- 为什么java中没有 CopyOnWriteLinkedList
- 知识点:链表是分散的存储空间,通过 指针串联起来的
- 知识点:数组是连续的存储空间
- 当需要复制数组,只需要复制数组所在的连续空间即可,是一个时间复杂度为O(1)的操作。
而链表是不连续的存储空间,所以复制链表意味着需要 按照链表的指针,遍历整个链表。这将是一个时间复杂度为O(n)的操作。
30 | 线程本地存储模式:没有共享,就没有伤害
笔记
- 线程封闭
- 局部变量
- ThreadLocal
- ThreadLocal源码
- 切记 ThreadLocalMap是Thread持有的
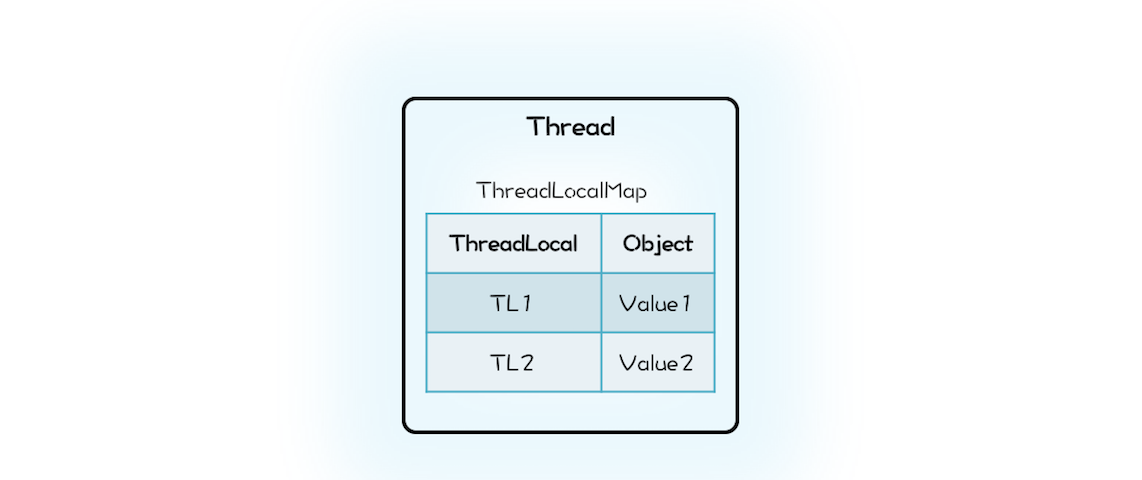
- 切记 ThreadLocalMap是Thread持有的
class Thread {
//内部持有ThreadLocalMap
ThreadLocal.ThreadLocalMap
threadLocals;
}
class ThreadLocal<T>{
public T get() {
//首先获取线程持有的
//ThreadLocalMap
ThreadLocalMap map = Thread.currentThread().threadLocals;
//在ThreadLocalMap中
//查找变量
Entry e = map.getEntry(this);
return e.value;
}
static class ThreadLocalMap{
//内部是数组而不是Map
Entry[] table;
//根据ThreadLocal查找Entry
Entry getEntry(ThreadLocal key){
//省略查找逻辑
}
//Entry定义
static class Entry extends
WeakReference<ThreadLocal>{
Object value;
}
}
}
- ThreadLocal 的内存泄漏问题
- 一个误区、不是说ThreadLocal一定存在内存泄漏,在一般场景中,Thread持有ThreadLocalMap,ThreadLocalMap以弱引用的方式持有ThreadLocal,当线程Thread被回收,意味着ThreadLocal一定会被回收。
- ThreadLocal的内存泄漏发生在配合线程池使用的场景中
- 在线程池中 线程存活时间很长,往往同应用程序是同生共死的,这就意味着 Thread 持有的 ThreadLocalMap 一直都不会被回收,再加上 ThreadLocalMap 的 Entry对 ThreadLocal的引用是弱引用(WeakReference)
- 所以 只要 ThreadLocal 结束了自己的生命周期 是可以被回收掉的。但是 Entry 中的value 却是被Entry强引用。所以即便 Value的生命周期结束了,value 也是无法被回收的(可达性分析算法),从而导致内存泄漏
- 解决方案-一般ThreadLocal配合线程池使用,需要使用try{}finally{}手动释放资源
ExecutorService es;
ThreadLocal tl;
es.execute(()->{
//ThreadLocal增加变量
tl.set(obj);
try {
// 省略业务逻辑代码
}finally {
//手动清理ThreadLocal
tl.remove();
}
});
总结
- Spring的 线程池管理 采用的就是 ThreadLocal ,每个线程可以针对性的修改自己的线程池。通过这个,可以写一个切面来切换数据源。
- 线程本地存储模式本质上是一种避免共享的方案,由于没有共享,所以自然也就没有并发问题。
31 | Guarded Suspension模式:等待唤醒机制的规范实现
笔记
- 等待唤醒机制

- 场景:
- 服务调用方(生产者) 将消息 发动到 MQ。
- 服务提供方(消费者) 将消息 消费。
现在需要消费者消费完消息后,通知 生产者,然后生产者再响应其客户端。
- 分析
- 生产者需要等待
- 消费者消费完需要通知生产者
- 方案
- 分析场景,其实就是一个异步转同步的过程
- 生产者等待 消费者通知 可以使用 管程实现
- 管程采用Lock + Condition 实现等待 和 通知的关键 需要找到一个将 生产者发送消息 和 消费者响应消息,将两个消息对应到一个Condition
- 方案就是将消息对应的Condition缓存起来 这样的话就可以采用 **Key(msg.id) --> value(Condition)
- 当 上下游 生产者和消费者都是集群化部署,如何解决?
- 设计 MQ的topic = msg + ip 这样就能保证 同一个节点消费的通知消息一定是 本节点生产的消息
- 场景:
32 | Balking模式:再谈线程安全的单例模式
笔记
- 多线程版本的if
- 场景:
- 类似语雀,编辑完了需要保存。
- 首先需要维护一个变量“changed”标识当前文档有没有被修改
- 然后一个定时任务 定时执行自动保存任务。
伪代码如下所示
- 类似语雀,编辑完了需要保存。
- 场景:
//自动存盘操作
void autoSave(){
synchronized(this){//同步代码块保证 对changed的读和下面的写互斥
if (!changed) {
return;
}
changed = false;
}
//执行存盘操作
//省略且实现
this.execSave();
}
//编辑操作
void edit(){
//省略编辑逻辑
......
synchronized(this){
changed = true;
}
}
- 针对上面的场景,总结成为一个并发设计模式 - Balking模式
- Balking 本质上是一种规范化的解决“多线程版本if”的方案
- Balking 模式范式 -- 使用管程实现
boolean changed=false;
//自动存盘操作
void autoSave(){
synchronized(this){
if (!changed) {
return;
}
changed = false;
}
//执行存盘操作
//省略且实现
this.execSave();
}
//编辑操作
void edit(){
//省略编辑逻辑
......
change();
}
//改变状态
void change(){
synchronized(this){
changed = true;
}
}
- volatile 实现Balking模式
- 对于上面使用 管程 实现的balking模式,是针对多线程版本的互斥方案。如果,在场景中不需要保证变量 changed 的互斥,可以采用volatile来实现
- 切记 使用 volatile 的前提是对原子性没有要求。
仍然是上面的场景,如果对互斥要求不严格,表现在业务上,也就是如果多保存几次也无所谓,那么就可以去掉 管程 使用volatile来修饰_changed_变量。 - 重点 volatile实现Balking 的场景十分有限。只需要记住使用 volatile 的前提是对原子性没有要求。 即可
课后思考
以下代码是为了保证 count只被计算一次。
class Test{
volatile boolean inited = false;
int count = 0;
void init(){
if(inited){//1
return;
}
inited = true;//2
//计算count的值
count = calc();//3
}
}
- 以上代码是否存在线程安全性问题?
- 当多个线程同时进入1处代码,也就意味着,这几个想成都能完整执行2,3处的代码。所以count就有可能被计算多次。
总结
- 只执行一次的场景
- 场景:
SpringBoot 启动流程的源码中,refresh 方法只能被执行一次。 - 方案:保证代码绝对只执行一次最好的解决方案就是使用原子类AtomicBoolean。
AtomicBoolean.compareAndSet(false, true)。
- 场景:
- Balking 模式的启发
- 之前实现的离线 license 可以通过 Balking 模式优化一般