代码如下:
""" 下面的方法是用kmeans方法进行聚类,用calinski_harabaz_score方法评价聚类效果的好坏 大概是类间距除以类内距,因此这个值越大越好 """ import matplotlib.pyplot as plt from sklearn.datasets.samples_generator import make_blobs from sklearn.cluster import KMeans from sklearn import metrics """ 下面是生成一些样本数据 X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.5, 0.2] """ X, y = make_blobs(n_samples=500, n_features=2, centers=[[2,3], [3,0], [1,1]], cluster_std=[0.4, 0.5, 0.2], random_state =9) """ 首先画出生成的样本数据的分布 """ plt.scatter(X[:, 0], X[:, 1], marker='o') plt.show() """ 下面看不同的k值下的聚类效果 """ score_all=[] list1=range(2,6) #其中i不能为0,也不能为1 for i in range(2,6): y_pred = KMeans(n_clusters=i, random_state=9).fit_predict(X) #画出结果的散点图 plt.scatter(X[:, 0], X[:, 1], c=y_pred) plt.show() score=metrics.calinski_harabaz_score(X, y_pred) score_all.append(score) print(score) """ 画出不同k值对应的聚类效果 """ plt.plt(list1,score_all) plt.show()
原来的数据分布图为:
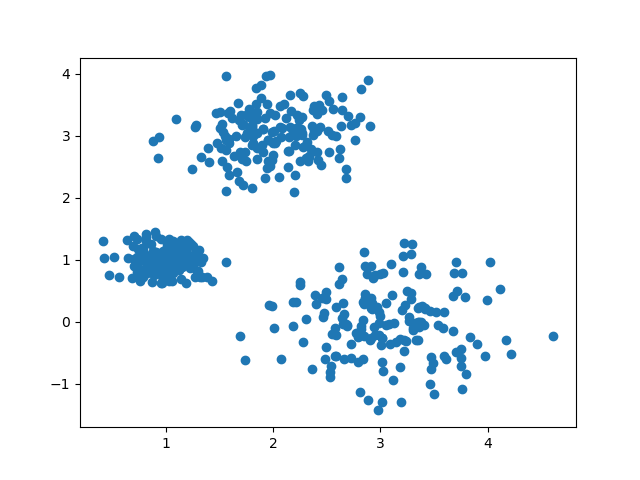
k=2时,聚类情况:
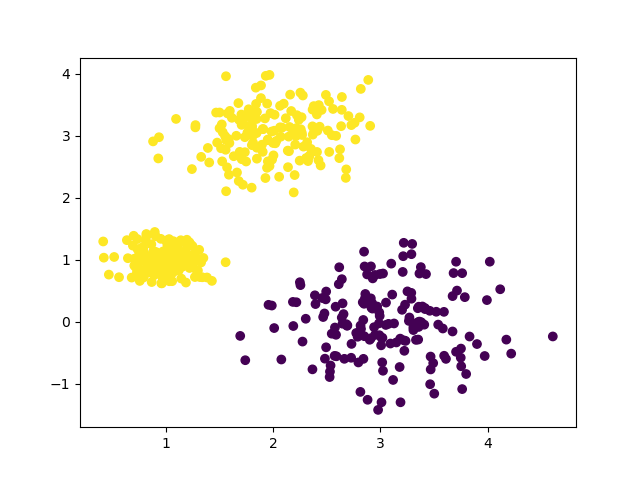
k=3时,聚类情况:
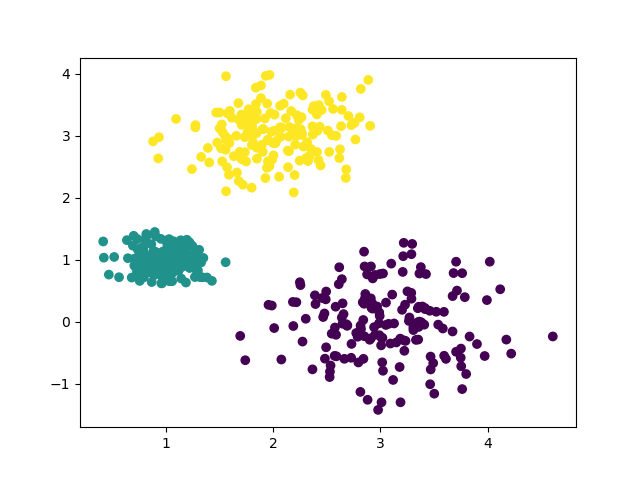
k=4时的聚类效果:
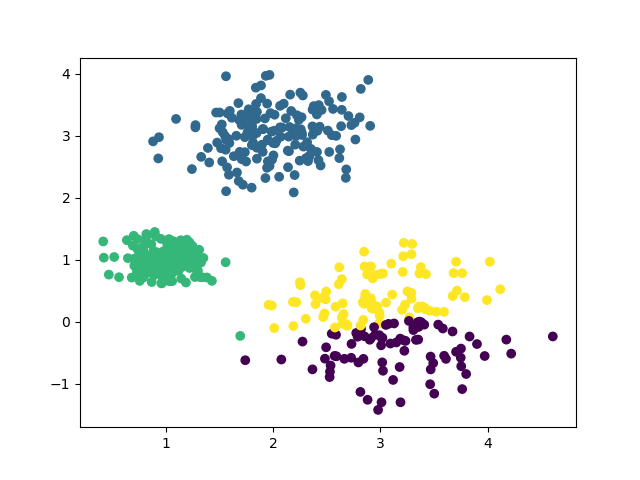
k=5时的聚类效果:

不同k值对应的聚类效果折线图:
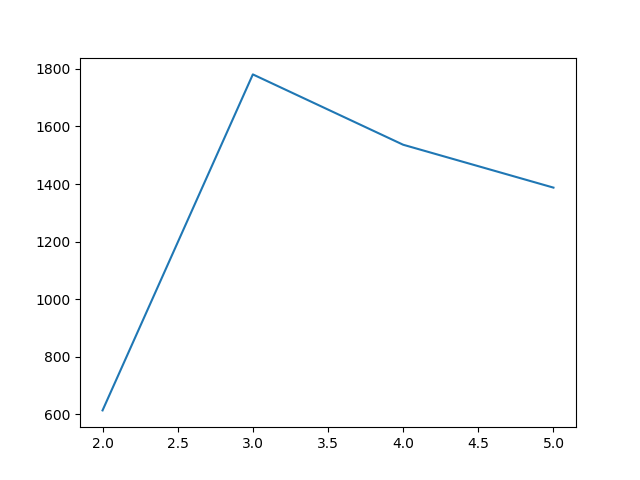
我们可以看到,k=3时,哪个值最大,效果最好。