拉格朗日乘数
在数学中的最优化问题中,拉格朗日乘数法(以数学家约瑟夫·拉格朗日命名)是一种寻找多元函数在其变量受到一个或多个条件的约束时的极值的方法。这种方法可以将一个有n个变量与k个约束条件的最优化问题转换为一个解有n + k个变量的方程组的解的问题。这种方法中引入了一个或一组新的未知数,即拉格朗日乘数,又称拉格朗日乘子,或拉氏乘子,它们是在转换后的方程,即约束方程中作为梯度(gradient)的线性组合中各个向量的系数。
比如,要求



拉格朗日乘数法所得的极点会包含原问题的所有极值点,但并不保证每个极值点都是原问题的极值点。拉格朗日乘数法的正确性的证明牵涉到偏微分,全微分或链法。
微积分中最常见的问题之一是求一个函数的极大极小值(极值)。但是很多时候找到极值函数的显式表达是很困难的,特别是当函数有先决条件或约束时。拉格朗日乘数则提供了一个非常便利方法来解决这类问题,而避开显式地引入约束和求解外部变量。
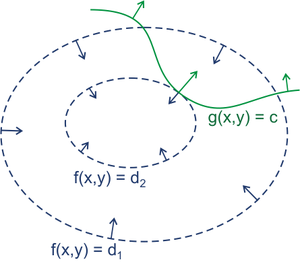
先看一个二维的例子:假设有函数:

c为常数。对不同
的等高线。而方程




气象图中就很常出现这样的例子,当温度和气压两列等高线同时出现的时候,切点就意味着约束极值的存在。
用向量的形式来表达的话,我们说相切的性质在此意味着
![abla Big[f left(x, y
ight) + lambda left(g left(x, y
ight) - c
ight) Big] = 0](https://wikimedia.org/api/rest_v1/media/math/render/svg/b3a981575b3f3bcbe55cd1616bc5a0ea1a0db98b)
且λ ≠ 0.
一旦求出λ的值,将其套入下式,易求在无约束条件下的极值和对应的极值点。
=

新方程

拉格朗日乘数的运用方法
如f定义为在Rn上的方程,约束为gk(x)= ck(或将约束左移得到gk(x) − ck = 0)。定义拉格朗日Λ为
。
注意极值的条件和约束现在就都被记录到一个式子里了:

和
。
拉格朗日乘数常被用作表达最大增长值。原因是从式子:
。
中我们可以看出λk是当方程在被约束条件下,能够达到的最大增长率。拉格朗日力学就使用到这个原理。
拉格朗日乘数法在卡罗需-库恩-塔克条件被推广。
例子
很简单的例子
求此方程的最小值:

同时未知数满足

因为只有一个未知数的限制条件,我们只需要用一个乘数


将所有



另一个例子
。
所有概率的总和是1,因此我们得到的约束是g(p)= 1即
。
可以使用拉格朗日乘数找到最高熵(概率的函数)。对于所有的k从1到n,要求

由此得到
。
计算出这n个等式的微分,我们得到:
。
这说明pi都相等(因为它们都只是λ的函数)。解出约束∑k pk = 1,得到
。
因此,使用均匀分布可得到最大熵的值。
参考:
https://zh.wikipedia.org/wiki/%E6%8B%89%E6%A0%BC%E6%9C%97%E6%97%A5%E4%B9%98%E6%95%B0