整理自:
https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1
- 原理
- RNN、LSTM、GRU区别
- LSTM防止梯度弥散和爆炸
- 引出word2vec
1.原理
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward+Neural+Networks)。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出。所以叫循环神经网络
2.RNN、LSTM、GRU区别
- RNN引入了循环的概念,但是在实际过程中却出现了初始信息随时间消失的问题,即长期依赖(Long-Term Dependencies)问题,所以引入了LSTM。
- LSTM:因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。推导forget gate,input gate,cell state, hidden information等因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸的变化是关键,下图非常明确适合记忆:
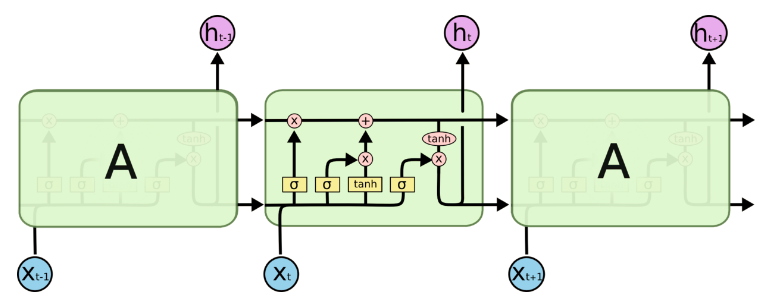
- GRU是LSTM的变体,将忘记门和输入们合成了一个单一的更新门。
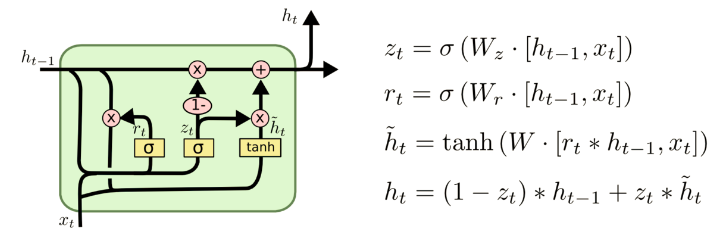
3. LSTM防止梯度弥散和爆炸
LSTM用加和的方式取代了乘积,使得很难出现梯度弥散。但是相应的更大的几率会出现梯度爆炸,但是可以通过给梯度加门限解决这一问题。
4.引出word2vec
这个也就是Word Embedding,是一种高效的从原始语料中学习字词空间向量的预测模型。分为CBOW(Continous Bag of Words)和Skip-Gram两种形式。其中CBOW是从原始语句推测目标词汇,而Skip-Gram相反。CBOW可以用于小语料库,Skip-Gram用于大语料库。