全部内容来源于《Python深度学习》,以练习为主,理论知识较少,掺杂有一些个人的理解,虽然不算很准确,但是胜在简单易懂,这本书是目前看到最适合没有深度学习经验的同学们入门的书籍了,不妨试试,该书作者:Francois Chollet,即Keras之父,该书译者:张亮;
相关内容以及代码已经在Kaggle的notebook上正常运行,欢迎大家star、fork;
深度学习第一个难点在于它所谓的黑盒,让人望而生畏,这本书的思路是以最简单的模型结构入手,针对最经典的全连接层、卷积层、循环层依次进行拆解,分析其原理、适用场景、为什么适用、例子(并且例子都非常有趣且实用)程序来验证前面的观点,在分析之中穿插有多种提升模型性能的手段,既能完成具体的项目看到效果,又能理解模型预测好与坏的原因以及如何定向的优化它;
本篇目录:
- 电影评论分类、新闻分类、房价预测 - 全连接层
- 猫狗分类 - 卷积神经网络
- 谁说深度学习都是黑盒 - 卷积神经网络的可视化
- 文本序列分类、时间序列预测 - 循环神经网络
- 从无到有创造文本 - 基于LSTM的语言模型
- 从无到有创造图像 - 变分自编码
深度学习标准工作流
- 读取输入数据、清洗、构建特征、调整数据格式为符合网络输入层要求;
- 搭建网络拓扑结构;
- compile网络设置optimizer、loss、metrics等参数;
- 训练模型,通常需要指定validation data来实时验证模型性能;
- 使用模型预测测试集数据;
全连接层
Dense层(全连接层、密集连接层)是神经网络中最基础也是最常用的层,它处理一维向量数据,对应的也就是shape=(samples,features)的二阶张量,对于输入数据的计算方式如下:
上式中,向量点积、加法运算为纯线性计算,激活函数activation提供非线性计算,这极大的增长了神经网络模型的假设空间,通俗理解就是模型变得更加强大,能够拟合更多的数据;
输入数据准备:
- 不管是结构化数据、文本数据还是图像数据,都需要进行向量化(数据转为N阶张量)处理以符合网络中输入层的格式要求;
- 对于标签列,如果是分类任务,则需要进行categorical处理,类似索引化处理;
- Dense、Conv2D、LSTM等需要的输入数据的张量阶数一般是不同的,通常需要reshape处理;
电影评论情感分类
该项目属于文本二分类任务,也是NLP领域最基础的任务之一,首先它的原始数据为文本,因此需要想办法对其进行向量化处理,其次它是分类任务,因此标签列需要categorical处理;
下面一步一步来实现:
- 文本向量化:即索引化、one-hot以及词嵌入;
- 索引化是将每个word(英文是单词,中文是字或者词,取决于你的颗粒度)映射到一个整数值,例如“我”->1,“爱”->2,“中国”->5,那么“我爱中国”向量化后为 1 2 5,由于文本的长度并不是固定的,因此通常会设置一个最长的限制,例如maxlen=10,超过maxlen的部分截断,不足maxlen的需要以某个指定值填充,例如maxlen=5,不足使用0填充的“我爱中国”映射为 0 0 1 2 5,这样处理后就可以将每段文本转换为等长的向量;
- one-hot是类似独热编码的处理,与索引化类似,依然使用上述“我爱中国”的例子,索引化的结果为 0 0 1 2 5,而one-hot的结果为 0 1 1 0 0 1 0 0 0 0,即将1、2、5对应位置改为1,其余保持0,同时长度固定为10,主要区别在于:索引化中字的顺序没有变化,而one-hot中这种顺序被丢弃了,其次通常索引化后的向量是密集的,而one-hot则是稀疏的;
- 词嵌入是另一种文本向量化的方法,后面用循环神经网络处理序列问题是会用到,我们后面再细说;
# 此处使用的是**one-hot**向量化处理,由于Dense层单独处理每个输入张量,因此无法捕获序列中的前后依赖信息,因此更适合处理**one-hot**向量化后的数据
# 通过keras内置的imdb数据集加载数据,num_words表示只加载出现最多的前10000个单词
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000)
# 文本序列向量化处理
def vectorize_sequences(sequences, dimension=10000):
# 构建全0向量
results = np.zeros((len(sequences),dimension))
# 根据文本中单词的索引值来指定对应位置的元素为1,其余为0,结果为 0 0 1 1 0 1 0 0 1 ....长度为10000的由0和1组成的向量
for i,sequence in enumerate(sequences):
results[i, sequence] = 1
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
- 搭建网络拓扑结构:
# 对于文本二分类等简单任务,拓扑结构不宜太复杂,此处选择一个Dense作为输入层,一个Dense作为隐含层,一个Dense作为输出层的线性堆叠结构
network = models.Sequential()
# 激活函数使用relu,一般情况下都适用
network.add(layers.Dense(16,activation="relu",input_shape=(10000,))) # relu整流激活函数实现表示空间非线性
network.add(layers.Dense(16,activation="relu"))
# 由于是二分类问题,因此选择sigmoid作为输出层激活函数,sigmoid将输出压缩到0~1之间作为二分类的类别概率值
network.add(layers.Dense(1,activation="sigmoid"))
- 编译模型:
# 以下使用的都是二分类问题的基本参数,很多时候默认的就是最优的
network.compile(loss="binary_crossentropy", # 适用于输出概率值的二分类模型
optimizer="rmsprop", # SGD的变种
metrics=["accuracy"])
- 训练模型并观察最优迭代数:
# 训练过程需要实时测试性能,因此需要将数据划分为训练集和验证机
x_val = x_train[:10000]
x_train_partial = x_train[10000:]
y_val = train_labels[:10000]
y_train_partial = train_labels[10000:]
# epochs表示模型迭代次数,batch_size表示每次迭代的每一轮模型权重参数更新使用的数据量
history = network.fit(x_train_partial,y_train_partial,epochs=20,batch_size=512,validation_data=(x_val,y_val))
# 通过history参数来查看训练过程每一轮记录的loss和accuracy
history_df = pd.DataFrame(history.history)
history_df[["loss","val_loss"]].plot()
history_df[["accuracy","val_accuracy"]].plot()


- 在测试集上验证模型:
# 上述图中可以看到最优epochs约为4
network = models.Sequential()
network.add(layers.Dense(16,activation="relu",input_shape=(10000,)))
network.add(layers.Dense(16,activation="relu"))
network.add(layers.Dense(1,activation="sigmoid"))
network.compile(loss="binary_crossentropy",optimizer="rmsprop",metrics=["accuracy"])
network.fit(x_train,train_labels,epochs=4,batch_size=512)
result = network.evaluate(x_test,test_labels)
# 结果为:[0.3078942894935608, 0.8791999816894531]
以上就是一个完整的深度学习建模并测试的流程,虽然不管是数据处理还是模型调优等都尽可能的简化了,但是麻雀虽小五脏俱全,再复杂的模型也是在这个基础上产生的,对于这个情感分类问题,如果采用机器学习算法,比如随机森林、逻辑回归、XGBoost等也是可以做到一样甚至更好的准确率的,但是过程会复杂很多,主要体现在特征工程部分,需要针对不同情感分类对应的关键字等进行特征构建,因此我们依然可以看到深度学习的魅力,即便是在如此简单的一个问题上;
新闻多分类
这个项目与上述电影评论分类唯一的区别在于它是个多分类问题,因此下述主要展示这一点区别对流程上的影响;
network = models.Sequential()
# 你会注意到输入层与隐含层的神经元个数较新闻评论二分类相比多了,由16->64,这里没有一定的规则,但是通常认为多分类任务较二分类要复杂,神经元个数代表了神经层的表示能力,因此需要增加,但是具体增加到多少是需要调试的
network.add(layers.Dense(64,activation="relu",input_shape=(10000,))) # 隐藏单元数设置为64,用于构建更复杂的表示空间去识别复杂的46个类别的表示
network.add(layers.Dense(64,activation="relu"))
# 多分类问题需要使用softmax做多类别的概率输出,46为类别数
network.add(layers.Dense(46,activation="softmax")) # softmax用于多分类的激活函数,输出46个类别对应的概率,概率和为1
# 与二分类使用binary_crossentropy不同,多分类使用categorical_crossentropy
network.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"])
x_val = x_train[:1000]
x_train_part = x_train[1000:]
y_val = y_train[:1000]
y_train_part = y_train[1000:]
history = network.fit(x_train_part,y_train_part,epochs=20,batch_size=512,validation_data=(x_val,y_val))
history_df = pd.DataFrame(history.history)
history_df[["loss","val_loss"]].plot()
history_df[["accuracy","val_accuracy"]].plot()


波士顿房价预测
之前的两个项目都是分类任务,本项目为回归任务,实际从构建网络上来看,回归任务更简单一些,同样的下述从差异介绍;
- 由于输入数据是结构化因此不需要向量化处理,但是由于各个特征量纲不同,一般需要统一量纲:
# 各个特征统一到均值为0,标准差为1下
mean_ = train_data.mean(axis=0)
std_ = train_data.std(axis=0)
train_data -= mean_
train_data /= std_
test_data -= mean_
test_data /= std_
- 输出层参数、损失函数以及监控指标的区别:
model = models.Sequential()
model.add(layers.Dense(64,activation="relu",input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64,activation="relu"))
# 由于Dense层本身输出的就是连续值,因此不需要激活函数
model.add(layers.Dense(1))
# 损失函数选择mse、性能指标选择mae,都是回归问题常用的指标
model.compile(optimizer="rmsprop",loss="mse",metrics=["mae"])


卷积神经网络
深度学习在图像识别领域是远远领先于其他机器学习算法的,主要原因在于对于机器学习算法,图像数据难以人工构建有效特征,而特征工程的好坏直接影响了最终模型的性能,而深度学习模型更擅长此类问题,比如用于处理图像识别的卷积神经网络,我们知道视觉空间有两大特点:
- 平移不变性:假如模型在某个局部范围内学习到了”耳朵“这个模式,那么它在其他位置依然可以识别该模式;
- 空间层次结构:随着网络层的加深,不同的卷积层会学习到不同维度的模式,一般最上层是一些纯色、边缘等基础的、通用的模式,而越往后模式就越抽象,比如猫狗分类中会出现猫耳朵、狗尾巴等模式被识别出来(PS:这种模式是可以通过可视化的方式直观看到的,这个在后面的卷积神经网络可视化部分会展示给大家看,非常有趣);
对于平移不变性,卷积神经网络的做法是通过固定大小的滑窗逐步的对部分像素数据进行计算,识别其模式,而对于空间层次结构,通过堆叠卷积层,使得靠后的卷积层在之前卷积层的输出上进一步识别模式,以此实现对高维模式的捕获;
卷积层对输入数据的计算如下:
假设输入图像数据5*5,卷积核为3*3,步幅为1,那么计算过程如下:
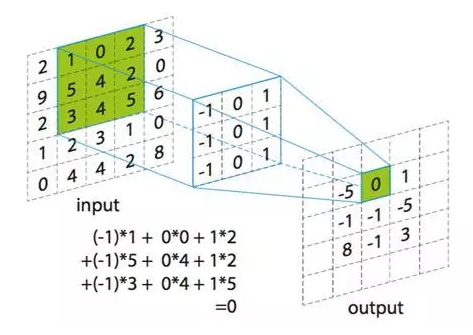
可以看到,在此情况下输出为3*3,虽然与Dense一样都可以看做是信息蒸馏的过程,但是与Dense同时计算全部数据不同,卷积层是依次对不同区域的像素数据进行计算,因此可以识别更基础的模式,且最终结果依然保持了图像信息的相对位置,这一点很重要;
最后
下一部分将进入各个实战章节,包含MNIST、猫狗识别、时序问题、生成式深度学习、深度学习可视化等等,将会更加有趣,一起期待一下把;
最后附上notebook链接,大家最好copy过去修改、运行、看效果哈,动手学习效果最佳;