进程和程序的区别
程序
程序就是一堆计算机可以识别的文件,程序在没有被运行时就是躺在硬盘上的一堆二进制
运行程序时,要从硬盘读取数据到内存中,CPU再从内存中读取指令并执行
进程
一旦程序运行就会产生进程
一个程序可以多次执行,产生多个进程,但是进程之间时相互独立的
当我们右键运行一个py文件时,其实启动的时python解释器,你的py文件其实是当作参数传给了解释器
阻塞 非阻塞 并行 并发 ******
1、阻塞:程序运行时遇到IO操作时就进入了阻塞状态
本地IO:input print sleep read write
网络IO:recv send
2、非阻塞:程序正常运行中,没有任何IO操作,就处于非阻塞状态
## 阻塞 非阻塞 说的是程序的运行状态
3、并发:多个任务看起来同时在处理,本质上时切换执行,只是速度非常快而已
4、并行:多个任务真正的同时执行,必须具备多核CPU,才可以并行
## 并发 并行 说的是任务的处理方式
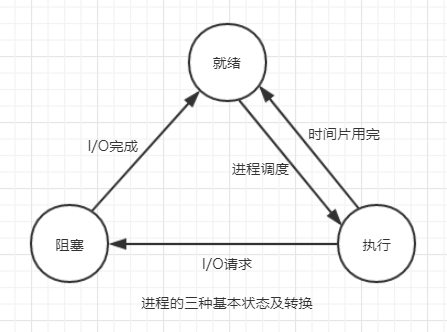
进程的三种状态以及之间的切换
1、运行态:程序正常执行
2、阻塞态:遇到io操作进入阻塞状态
3、就绪态:io执行完毕进入就绪状态,并向cpu发出信息(等待cpu过来执行)
提高进程效率的方法
根本方法就是让程序尽可能处于运行的状态
减少I/O操作 或者 尽可能多的占用CPU时间
之前学的缓冲区就是用于减少I/O操作,一次多拿点数据,减少拿的次数
进程的创建与销毁
进程的创建
但凡时硬件,就需要有操作系统取管理,只要有操作系统,就有进程的概念,就需要有创建进程的方式,
一些操作系统只为一个应用程序设计,比如自动洗衣机,一旦启动,进程就已经存在
而对于通用系统(跑很多应用程序),需要有系统运行过程中创建或撤销进程的能力,主要分为4种形式创建新的进程
--1、系统初始化(就是只有在需要的时候才启动进程,例如web页面滑到对应的界面才唤醒的进程,也称为守护进程)
--2、一个进程在运行过程中开启了子进程(例如我们在pycharm中运行py文件开启了python解释器的进程)
--3、用户交互式请求,创建新的进程(例如在GUI界面双击某个应用程序)
--4、一个批处理作业的初始化(只有在大型机的批处理系统中应用),现在基本没有了,了解即可
创建子进程unix与windows的比较
1、相同点:进程创建后,父进程和子进程有各自不同的地址空间(多道技术要求物理层面实现进程之间内存的隔离),任何一个进程的在其地址空间中的修改都不会影响到另外一个进程
2、不同点:在unix中,子进程的初始地址空间时父进程的一个副本,但对于windows来说,需要重新加载程序代码,所以需要把创建子进程的一些代码放到自执行的判断中
进程的销毁
1、正常退出(自愿,如用户点击交互式页面的×,或者程序执行完毕调用发起系统调用正常退出)
2、出错退出(自愿, python a.py中 a.py不存在)
3、严重错误(非自愿,执行非法操作时,如引用不存在的内存,可以捕捉异常)
4、被其他进程杀死(非自愿,如kill -9)
python中实现多进程
在一个应用程序中可能会有多个任务需要并发执行,但是对于操作系统而言,一个进程就是一个任务,
当程序执行过程中遇到I/O操作时,操作系统就会把cpu调给其他应用程序,这对于当前应用程序来说效率就降低了
如何让程序既能完成任务又不降低效率,就需要把耗时的操作交给子进程来完成
开启子进程的两种方式
在python中,想要开启子进程,需要用到multiprocessing模块中的Process类
1、直接实例化Process类
from multiprocessing import Process import time def task(name): # 创建函数,里面是需要子进程执行的代码块 print("子进程 run") time.sleep(3) # 模拟任务需要耗时 print(name) print("子进程 over") if __name__ == '__main__': # 创建子进程的代码必须放在这个判断下面,因为windows会导入一下这文件 # target指定的子进程要执行的任务 args里传入的是子进程需要的参数,需要几个传几个 p = Process(target=task,args=("xxx","sad ")) print("父进程 run") p.start() time.sleep(2) print("父进程 over") # 运行结果表明,子进程和当前进程看起来是同时执行(并发)
2、继承Process类并且覆盖run方法
from multiprocessing import Process import time class MyProcess(Process): # 继承Process类 def __init__(self,name): # 想要往子进程里传入参数,必须在__init__函数中加入属性 super().__init__() self.name = name def run(self): # 覆盖Process的run方法,里面放入子进程要执行的代码块 print("子进程 run") time.sleep(1) print(self.name) time.sleep(1) print("子进程 over") if __name__ == '__main__': p = MyProcess("rose") print("父进程 run") p.start() time.sleep(1) print("父进程 over")
需要注意的是:
1、在windows下 开启子进程函数必须放到__main__下面,因为windows在开启子进程时会重新加载所有的代码造成递归创建进程
2、第二种方式中,必须将要执行的代码放到run方法中,子进程只会执行run方法,其他一概不管
进程之间的内存空间是隔离的
from multiprocessing import Process a = 1000 def task(): global a a = 10 print(a) if __name__ == '__main__': p = Process(target=task) p.start() print(a) # 1000 # 10 运行结果表明进程间内存时相互隔离的
join方法
from multiprocessing import Process import time def task(): print("子进程 run") time.sleep(2) print("子进程 over") if __name__ == '__main__': p = Process(target=task) p.start() p.join() print("我是父进程") # 子进程 run # 子进程 over # 我是父进程 结果表明join函数是让父进程等待该子进程运行完之后才继续往下执行
既然join方法是让父进程等待子进程运行结束才执行代码,那么是不是又变成串行了???
如果你只是开启一个子进程的话,那这样确实变成串行(那你也没必要开子进程了)
但如果开启了多个子进程的话,join函数只会让父进程等该子进程运行结束才执行,但是并不会限制其他子进程的执行
from multiprocessing import Process import time def task(): print("子进程 run") time.sleep(2) print("子进程 over") if __name__ == '__main__': p1 = Process(target=task) p2 = Process(target=task) p3 = Process(target=task) p1.start() p2.start() p3.start() p1.join() p2.join() p3.join() print("我是父进程") # 结果表明 2 秒之后 3个子进程基本同时(并行)执行完毕,然后父进程继续执行代码
process对象的常用方法
p = Process(target=task) p.start() # 向操作系统发送开启进程的指令,需要一定时间 p.join() # 等待子进程结束,父进程再执行往后的代码 p.terminate() # 终止进程 也是向操作系统发送指令,需要延迟 print(p.name) # 进程的名称 print(p.is_alive()) # 查看进程是否存活 print(p.pid) # 查看进程的pid # 需要注意的是:process对象是惰性的,如果不发送start指令,p对象相当于没有创建
僵尸进程与孤儿进程
孤儿进程
指的是,父进程先结束,而子进程还在运行着,由操作系统接管
孤儿进程是无害的,并且是由存在的必要性的
例如:qq开启的浏览器,qq退出了,浏览器应该继续运行,因为它的任务可能还没有运行结束
僵尸进程
僵尸进程指的是,子进程已经结束了,但是操作系统会保存一些进程信息,如PID,运行时间等(证明这个进程开启过),此时,这个进程就成为僵尸进程,占用系统资源
僵尸进程如果太多将会占用大量的资源,造成系统无法开启新的进程
在Linux中,父进程需要调用wait/waitpid来获取子进程的残留信息,并清理它
python会自动回收僵尸进程