作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS 全称 Hadoop分布式文件系统,其最主要的作用是作为 Hadoop 生态中各系统的存储服务。功能:其中的目的是为了可以用大量廉价的存储器存取大量的数据可以支撑起千万计的文件,是一种非常好的数据存储模式,在这种模式中考虑到了数据批处理,而不是用户交互处理,比之数据访问延迟的问题,更关键的是数据访问的高吞吐量。工作原理: 其中HDFS采用master/slave架构,就是主要分为两类分别是NameNode和DataNode节点,其中NameNode节点是主节点安排工作,负责对文件的访问,DataNode节点主要是负责管理本机上的存储。
MapReduce是一种编程模型,功能:主要用于大数据的处理,例如分布grep,分布排序,web连接图反转,每台机器的词矢量,web访问日志分析,反向索引构建,文档聚类,机器学习,基于统计的机器翻译等等。工作原理:由于数据是以块为基础的,数据节点又不是只有一个,所以主要的思想是并行处理。而每个块的数据输入我们又称之为分片,map会对分片进行处理,每个map都是可以并行的得出的结果传给Reduce进行约束然后进行处理并输出最后的结果。
HDFS和MapReduce两者是必不可少的,缺少一个都不行,HDFS是要MapReduce进行处理的数据的来源,而HDFS的数据又要MapReduce的处理才能有作用。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/hszdocument

2)编写map函数和reduce函数,在本地运行测试通过


3)启动Hadoop:HDFS, JobTracker, TaskTracker

4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效

6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh

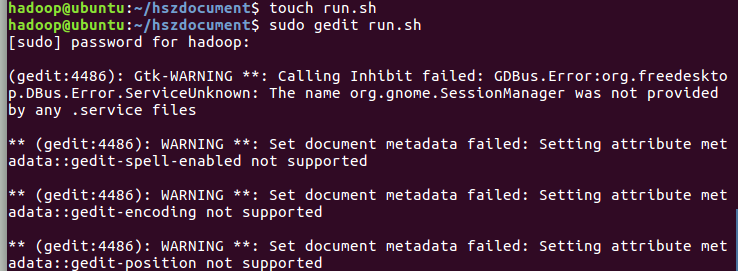
7)source run.sh来执行mapreduce

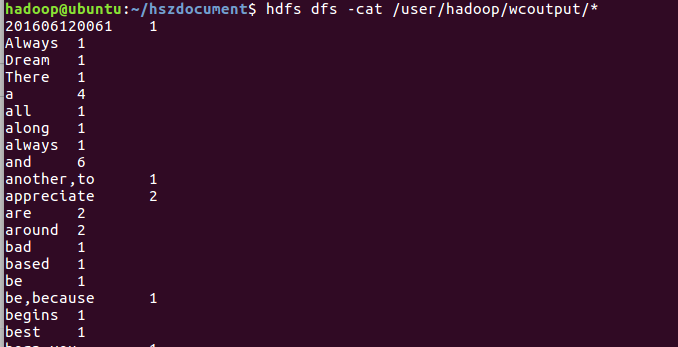
8)查看运行结果