本文作者:hhh5460
本文地址:https://www.cnblogs.com/hhh5460/p/10139738.html
例一的代码是函数式编写的,这里用面向对象的方式重新撸了一遍。好处是,更便于理解环境(Env)、个体(Agent)之间的关系。
有缘看到的朋友,自己慢慢体会吧。
0.效果图
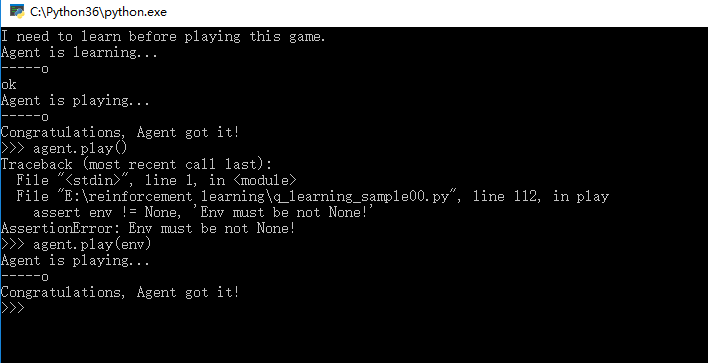
1.完整代码
import pandas as pd import random import time import pickle import pathlib ''' -o---T # T 就是宝藏的位置, o 是探索者的位置
作者:hhh5460
时间:20181218
地点:Tai Zi Miao ''' class Env(object): '''环境类''' def __init__(self): '''初始化''' self.env = list('-----T') def update(self, state, delay=0.1): '''更新环境,并打印''' env = self.env[:] env[state] = 'o' # 更新环境 print(' {}'.format(''.join(env)), end='') time.sleep(delay) class Agent(object): '''个体类''' def __init__(self, alpha=0.01, gamma=0.9): '''初始化''' self.states = range(6) self.actions = ['left', 'right'] self.rewards = [0,0,0,0,0,1] self.alpha = alpha self.gamma = gamma self.q_table = pd.DataFrame(data=[[0 for _ in self.actions] for _ in self.states], index=self.states, columns=self.actions) def save_policy(self): '''保存Q table''' with open('q_table.pickle', 'wb') as f: # Pickle the 'data' dictionary using the highest protocol available. pickle.dump(self.q_table, f, pickle.HIGHEST_PROTOCOL) def load_policy(self): '''导入Q table''' with open('q_table.pickle', 'rb') as f: self.q_table = pickle.load(f) def choose_action(self, state, epsilon=0.8): '''选择相应的动作。根据当前状态,随机或贪婪,按照参数epsilon''' if (random.uniform(0,1) > epsilon) or ((self.q_table.ix[state] == 0).all()): # 探索 action = random.choice(self.get_valid_actions(state)) else: action = self.q_table.ix[state].idxmax() # 利用(贪婪) return action def get_q_values(self, state): '''取状态state的所有Q value''' q_values = self.q_table.ix[state, self.get_valid_actions(state)] return q_values def update_q_value(self, state, action, next_state_reward, next_state_q_values): '''更新Q value,根据贝尔曼方程''' self.q_table.ix[state, action] += self.alpha * (next_state_reward + self.gamma * next_state_q_values.max() - self.q_table.ix[state, action]) def get_valid_actions(self, state): '''取当前状态下所有的合法动作''' valid_actions = set(self.actions) if state == self.states[-1]: # 最后一个状态(位置),则 valid_actions -= set(['right']) # 不能向右 if state == self.states[0]: # 最前一个状态(位置),则 valid_actions -= set(['left']) # 不能向左 return list(valid_actions) def get_next_state(self, state, action): '''对状态执行动作后,得到下一状态''' # l,r,n = -1,+1,0 if action == 'right' and state != self.states[-1]: # 除非最后一个状态(位置),向右就+1 next_state = state + 1 elif action == 'left' and state != self.states[0]: # 除非最前一个状态(位置),向左就-1 next_state = state -1 else: next_state = state return next_state def learn(self, env=None, episode=1000, epsilon=0.8): '''q-learning算法''' print('Agent is learning...') for _ in range(episode): current_state = self.states[0] if env is not None: # 若提供了环境,则更新之! env.update(current_state) while current_state != self.states[-1]: current_action = self.choose_action(current_state, epsilon) # 按一定概率,随机或贪婪地选择 next_state = self.get_next_state(current_state, current_action) next_state_reward = self.rewards[next_state] next_state_q_values = self.get_q_values(next_state) self.update_q_value(current_state, current_action, next_state_reward, next_state_q_values) current_state = next_state if env is not None: # 若提供了环境,则更新之! env.update(current_state) print(' ok') def play(self, env=None, delay=0.5): '''玩游戏,使用策略''' assert env != None, 'Env must be not None!' if pathlib.Path("q_table.pickle").exists(): self.load_policy() else: print("I need to learn before playing this game.") self.learn(env, 13) self.save_policy() print('Agent is playing...') current_state = self.states[0] env.update(current_state, delay) while current_state != self.states[-1]: current_action = self.choose_action(current_state, 1.) # 1., 不随机 next_state = self.get_next_state(current_state, current_action) current_state = next_state env.update(current_state, delay) print(' Congratulations, Agent got it!') if __name__ == '__main__': env = Env() # 环境 agent = Agent() # 个体 #agent.learn(env, episode=13) # 先学 #agent.save_policy() # 保存所学 #agent.load_policy() # 导入所学 agent.play(env) # 再玩