Learning based optical flow estimation is utilized to obtain the motion information and reconstruct the current frames. Then employ two auto-encoder style neural networks to compress the corresponding motion and residual information.
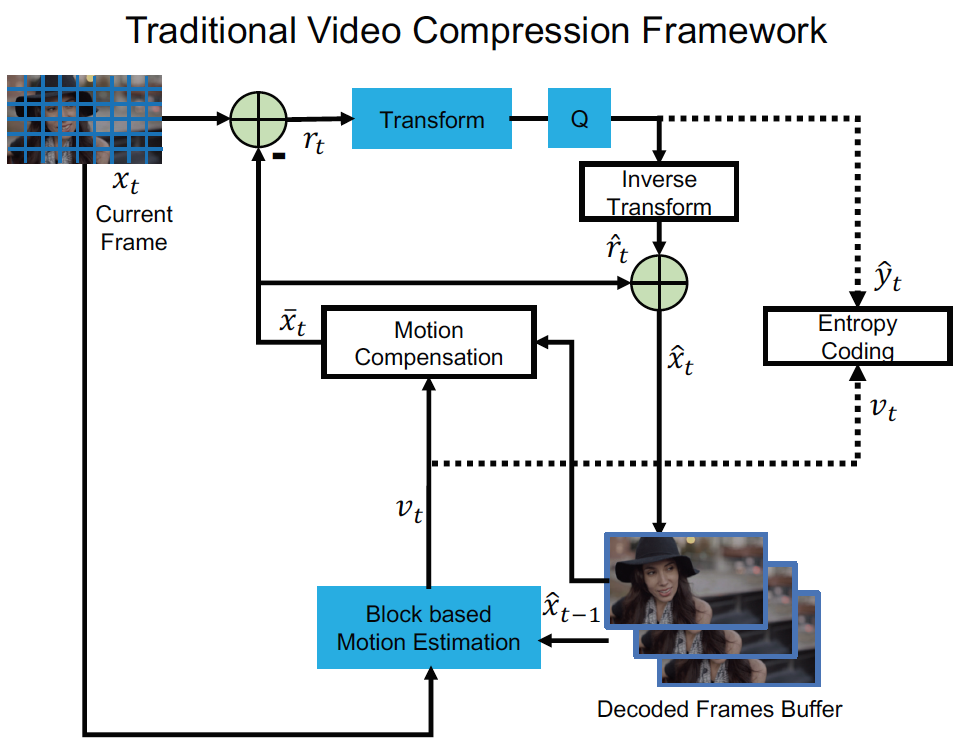
Traditional video compression framework将输入帧(x_t)分为一些相同大小的块(如(8 imes 8)), 算法在编码器端的编码过程如下:
-
运动估计: 估计当前帧(x_t)和上一帧的重构(hat{x}_{t-1})之间的运动, 得到每一个块对应的运动向量(motion vector, MV) (v_t)
-
运动补偿: 根据1中得到的运动向量(v_t), 将上一帧的重构的相应像素移动得到预测帧(overline{x}_{t}), 原始帧(x_t)和预测帧(overline{x}_{t})之间的残差(r_t=x_t-overline{x}_{t})
-
变换(Transform)和数字化(Quantization): 将2中得到的残差(r_t)数字化为(hat{y}_{t}), 在数字化时, 用一个线性变换(如DCT)来得到更好的压缩性能
-
逆变换: 3中的数字化结果(hat{y}_{t})通过逆变换得到重构残差(hat{r}_{t})
-
熵编码: 将1中的运动向量(v_t)和3中的数字化结果(hat{y}_{t})都通过熵编码方法编码为二进制, 并送给解码器
-
帧重构: 将2中的预测帧(overline{x}_{t})和4中的重构残差(hat{r}_{t})相加得到重构帧(hat{x}_{t}=hat{r}_{t}+overline{x}_{t}), 重构帧会在(t+1)帧的第1步中用到
而对解码器来说, 基于在5中编码器输出的比特流, 在2中进行运动补偿, 在4中进行逆数字化, 最后在6中进行帧重构就得到了重构帧(hat{x}_{t})
Traditional Video Compression Framework:
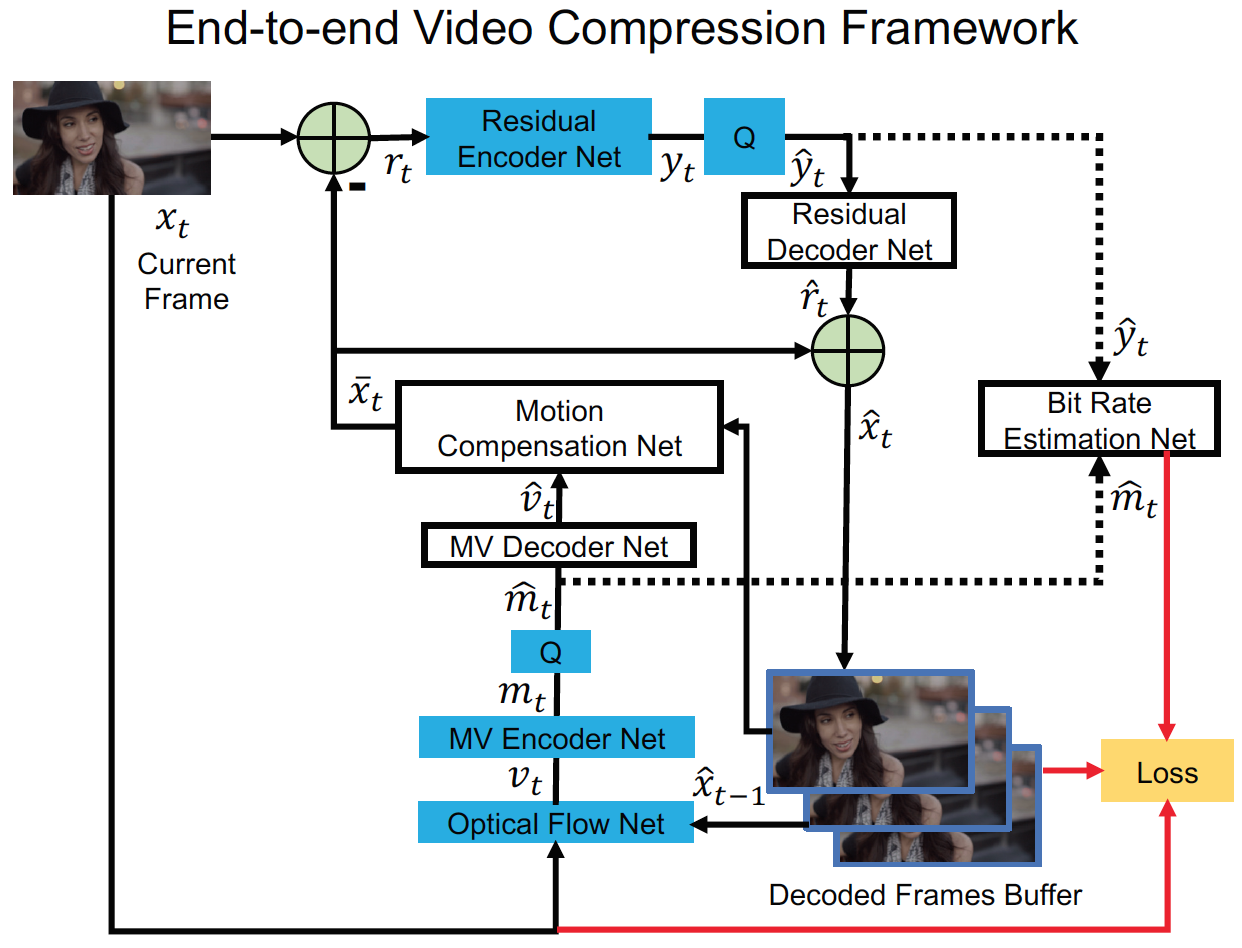
Deep learning based end-to-end video compression framework和traditional video compression framework是一一对应的:
N1. 运动估计和压缩: 用一个CNN来估计光流, 将其视为运动信息(v_t). 并且并不对原始的光流值进行编码, 而是用一个MV Encoder-Decoder来对光流值进行压缩和解码, 其中数字化的运动特征表示为(hat{m}_{t}), 然后再将(hat{m}_{t})通过MV Decoder进行解码得到重构运动信息(hat{v}_{t}). 细节在MV Encoder and Decoder Network
N2. 运动补偿: 通过一个运动补偿网络, 输入N1中得到的光流, 输出预测帧(overline{x}_{t}). 细节在下面
N3-N4. 变换, 数字化和逆变换: 不用3中的线性变换, 而是用一个高度非线性的残差Encoder-Decoder网络, 将残差(r_t)非线性的映射到表示(y_t). 然后将(y_t)数字化得到(hat{y}_t), (hat{y}_t)喂到残差解码网络中得到重构残差(hat{r}_t). 数字化方法用的是End-to-end optimized image compression中的方法. 细节在下面
N5. 熵编码: 在测试时, 将N1中得到的数字化的运动表示(hat{m}_t)和N3中得到的残差表示(hat{y}_t)编码为比特流, 并送给解码器. 在训练时, 为了估计我们方法中的比特成本, 用CNN(下图中的bit rate estimation net)来获得每个符号在(hat{m}_t)和(hat{y}_t)中的概率分布. 细节在下面
N6. 帧重构: 和6相同
End-to-end video compression framework:
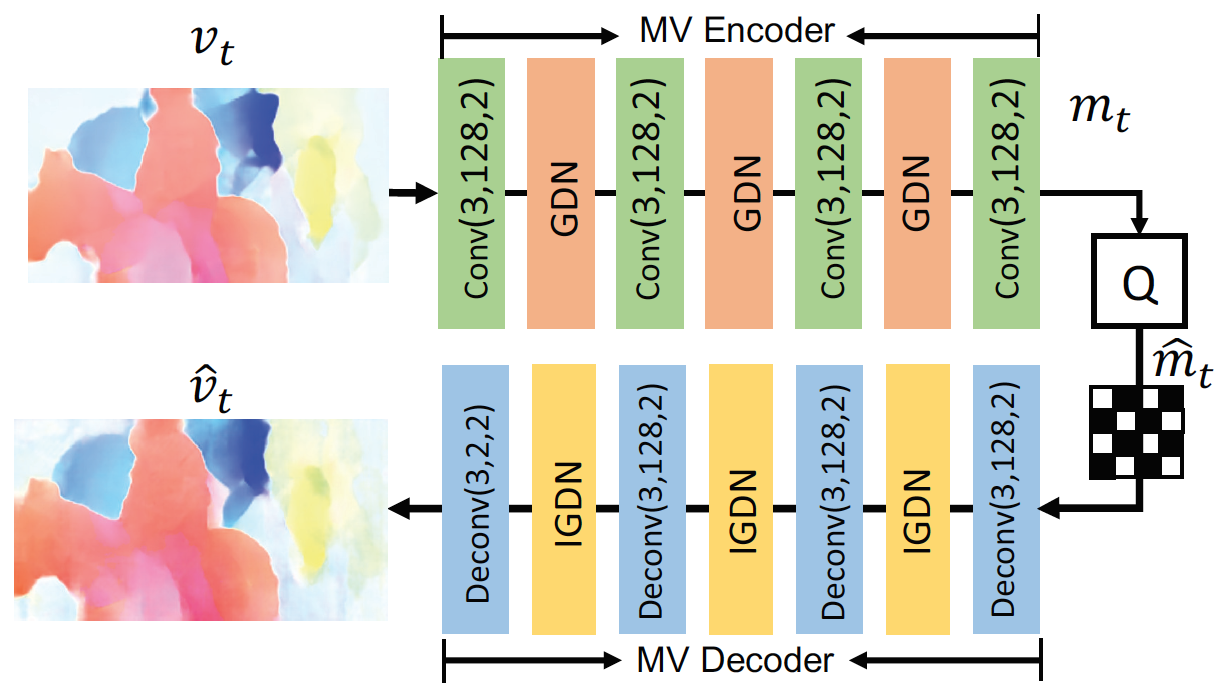
MV Encoder and Decoder Network:
用一个auto-encoder style network来压缩光流, End-to-end optimized image compression提出的首先用于图像压缩任务的方法
MV compression network:
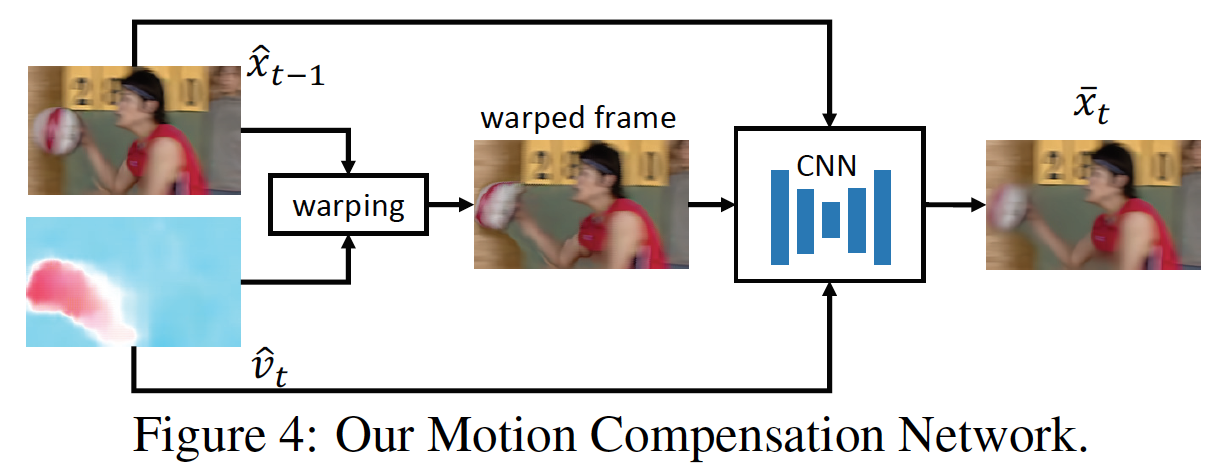
Motion Compensation Network:
输入上一帧的重构(hat{x}_{t-1})和运动向量(hat{v}_t), 输出预测帧(overline{x}_t), 并且希望它和当前帧(x_t)尽可能接近
- 将上一帧的重构(hat{x}_{t-1})基于运动信息(hat{v}_t)扭曲(warp)得到当前帧. 但是这样得到的帧仍然有瑕疵
- 为了去掉瑕疵, 联合扭曲后的帧(w(hat{x}_{t-1})), 参考帧(hat{x}_{t-1})和运动向量(hat{v}_t)来作为输入,喂到另一个CNN来得到调整后的预测帧(overline{x}_t)
这是种像素级的运动补偿方法
Residual Encoder and Decoder Network:
原始帧(x_t)和预测帧(overline{x}_t)之间的残差信息(r_t)通过residual encoder network编码
这篇论文用了Variational image compression with a scale hyperprior中的highly non-linear neural network来将残差变换成对应的潜变量表示
Training Strategy:
Goal: 1. minimize the number of bits used for encoding the video 2. reduce the distortion between the original input frame (x_t) and the reconstructed frame (hat{x}_t)
Rate-distortion optimization problem:
(d(x_t,hat{x}_t))表示(x_t)和(hat{x}_t)之间的失真, 实现中用MSE
(H(.))表示编码特征用的位数, residual representation (hat{y}_t)和motion representation (hat{m}_t)都需要编码成比特流
(lambda)是拉格朗日乘子
Quantization:
数字化操作不可微怎么办?
用End-to-end optimized image compression中的方法, 在训练阶段加入均匀噪声代替数字化运算(Q: ???)
比如(y_t)的数字化,训练时的数字化表示(hat{y}_t)用加均匀噪声来近似,即(hat{y}_t=y_t+eta),然后在推理阶段,直接用舍入操作,即(hat{y}_t=round(y_t))
Bit Rate Estimation:
(H(hat{m}_t))和(H(hat{y}_t))怎么求?
比特率的正确度量是对应潜变量表示的熵,因此用Variational image compression with a scale hyperprior中的CNN来估计(hat{m}_t)和(hat{y}_t)的概率分布
Buffering Previous Frames:
每次迭代的reconstructed frame会被保存在buffer中以便后面一帧拿来用