学习视频
https://www.bilibili.com/video/av66130637?p=2
一、基础介绍
Hive本身并不支持数据存储和处理。而是提供了一种编程的语言
1.Hive两个方面特性
·采用批处理方式处理海量数
Hive会把HIveQL语句转换成MapReduce任务进行运行
数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化
·Hive提供了一系列对数据进行提取、转换、加载(ETL)的工具
可以存储、查询和分析存储在Hadoop中的大规模数据,这些工具能够很好地满足数据仓库各种应用场景
2.应用的技术
Hive依赖于HDFS存储数据
Hive依赖于MapReduce处理数据
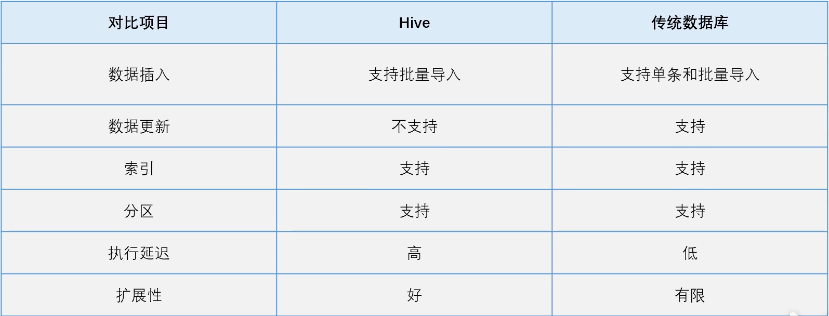
3.Hive和传统数据库的区别
4.Hive对外访问接口
CLI:一种命令工具
HWI:Hive Web Interface是Hive的Web接口
JDBC和ODBC:开放数据仓库连接接口
Thrift Server:基于Thrift架构开发的接口,允许外界通过这个接口实现对Hive仓库的RPC调用
二、MapReduce实现数据连接
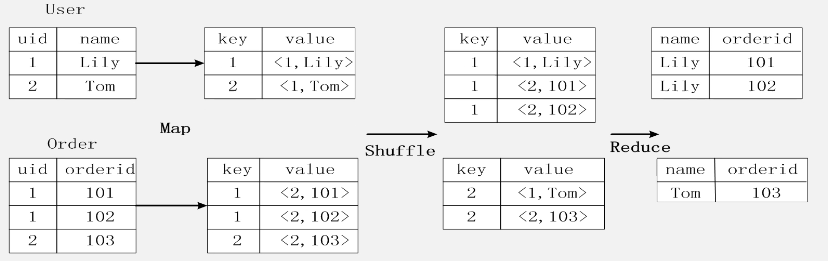
编写一个Map处理逻辑,处理逻辑输入关系数据库的表,通过Map对它进行转换
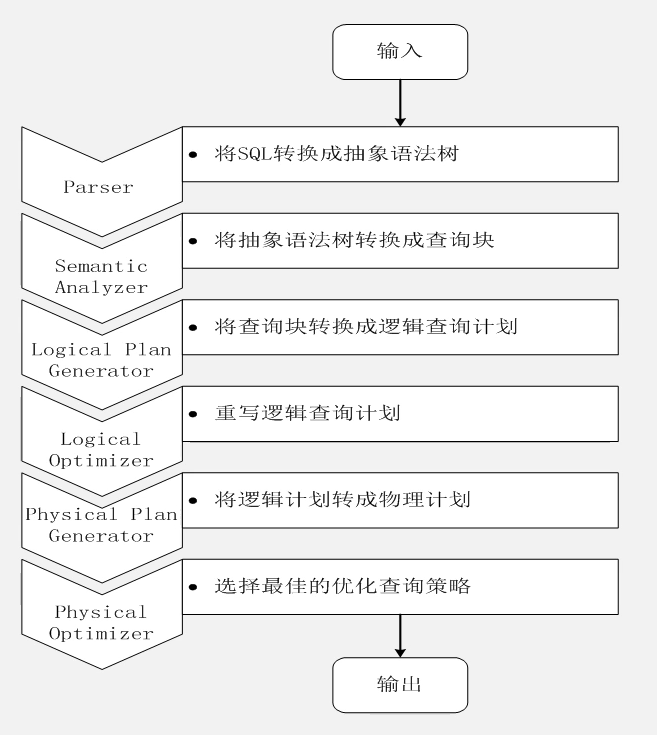
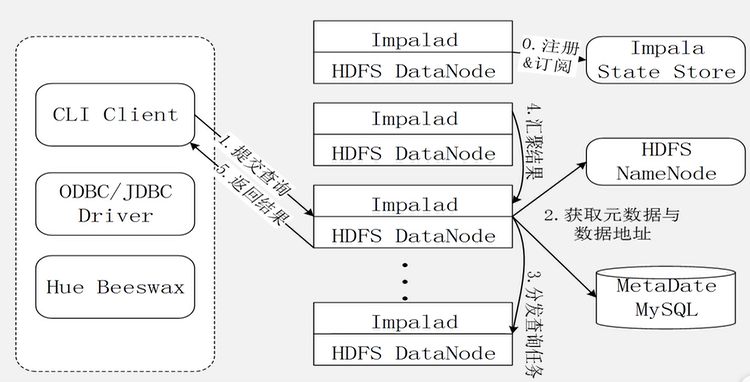
三、Impala查询执行过程
四、基本操作
1.创建数据库hive
![]()
防止抛出异常
![]()
2.创建表usr(含有三个属性id,name,age)
![]()
指定存储路径
![]()
3.创建视图little_usr(只包含urs表中的id,age)
![]()
4.查看Hive中所有的数据库

查看h开头的数据库

5.查看数据库Hive中u开头的表和视图
![]()
6.装载覆盖原有数据
![]()
装载不覆盖原有数据
![]()
7.插入数据并覆盖原有数据

插入数据并追加在原有数据之后
