hadoop存在的两个问题:
1.内存受限的问题
联邦解决内存受限问题。
建立多个NameNode,每个NameNode记录元数据的一部分,但是对于元数据整体来说本质上还是只有一份。
2.单点故障
HA(high available)高可用,解决hdfs的单点故障问题。
主备namenode,存储相同的数据,如果主NameNode发生故障,则切换到备用Namenode上。
手动HA:
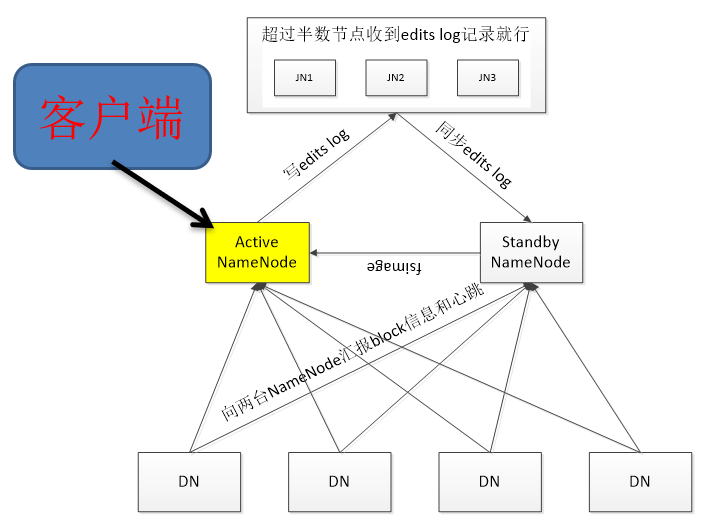
ActiveNameNode
1.与客户端建立连接,处理客户端的请求,
2.向JNN写入edits log文件,超过半数的JNN节点收到就行。
StandbyNameNode
1.standbyNameNode会监视任何对edit log 的修改,一旦edits log出现更改,StandbyNameNode就会根据edits log更新自己的元数据
2.合并edits log和fsimage文件
合并的时机:1.一小时;2.超过1 000 000万次事务(三秒钟检查一次事务数量)
3.当ActiveNameNode发生故障转移时,standbyNameNode主机会先确认自己已经读取了JNS上的所有更改来同步本身的元数据,然后由Standby状态切换为Active状态。
DataNodes
为了确保在发生故障转移时,NameNode拥有相同的数据块位置信息,DNS向所有的NameNode发送数据块位置信息和心跳数据。
JNS
JNs只允许一台NameNode向JNs写edits log数据,这样就能保证不会发生“脑裂”。
手动HA
通过命令实现主备之间的切换,可以用在HDFS升级等场合
自动HA

自动切换:
基于zookeeper实现,zookeeper分布式锁实现统一时间只有一个namenode获得节点
Zookeeper Failover Controller:监控namenode健康状态,并向zookeeper注册namenode
ZKFC:
1.监控本机namenode的状态
2.与zookeeper建立连接,保持心跳
3.当没有active namenode的时候为当前的namenode在zookeeper上抢占临时节点,获得节点为activeNameNode
4.如果当前的namenode不健康,让zookeeper删除临时节点,让对方抢占
5.如果zkfc退出,zookeeper临时节点消失,对方抢占
Hadoop HA 的集群搭建:
1.规划

2.搭建步骤
a) 将zookeeper.tar.gz上传到node2、node3、node4
b) 解压到/opt
tar -zxf zookeeper-3.4.6.tar.gz -C /opt
c) 配置环境变量:
export ZOOKEEPER_PREFIX=/opt/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_PREFIX/bin
然后 . /etc/profile让配置生效
d) 到$ZOOKEEPER_PREFIX/conf下
复制zoo_sample.cfg为zoo.cfg
cp zoo_sample.cfg zoo.cfg
e) 编辑zoo.cfg
添加如下行:
server.1=node2:2881:3881
server.2=node3:2881:3881
server.3=node4:2881:3881
修改
dataDir=/var/bjsxt/zookeeper/data
f) 创建/var/bjsxt/zookeeper/data目录,并在该目录下放一个文件:myid
在myid中写下当前zookeeper的编号
mkdir -p /var/bjsxt/zookeeper/data
echo 3 > /var/bjsxt/zookeeper/data/myid
2181 用户客户端连接zk集群的端口
zkCli.sh 客户端启动脚本
zkServer.sh 服务端启动脚本
mysql -uroot -p123456
mysqld 服务端
g) 将/opt/zookeeper-3.4.6通过网络拷贝到node2、node3上
scp -r zookeeper-3.4.6/ node2:/opt
scp -r zookeeper-3.4.6/ node3:/opt
h) 在node2和node3上分别创建/var/bjsxt/zookeeper/data目录,并在该目录下放一个文件:myid
node2:
mkdir -p /var/bjsxt/zookeeper/data
echo 1 > /var/bjsxt/zookeeper/data/myid
node3:
mkdir -p /var/bjsxt/zookeeper/data
echo 2 > /var/bjsxt/zookeeper/data/myid
i) 启动zookeeper
zkServer.sh start 启动zk
zkServer.sh stop 停止zk
zkServer.sh status 查看zk状态
zkServer.sh start|stop|status
j) 关闭zookeeper
zkServer.sh stop
l) 连接zookeeper
zkCli.sh node2、node3、node4都可以
m) 退出zkCli.sh命令
quit
hadoop配置
一律在node1上操作,做完后scp到node2、node3、node4
hadoop-env.sh配置JDK
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> hdfs://node1:9000 </property> <property> <name>hadoop.tmp.dir</name> <value>/var/bjsxt/hadoop/ha</value> </property> <!-- 指定每个zookeeper服务器的位置和客户端端口号 --> <property> <name>ha.zookeeper.quorum</name> <value>node2:2181,node3:2181,node4:2181</value> </property> </configuration>
hdfs-site.xml
<configuration> <!-- 指定block默认副本个数 --> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 用于解析fs.defaultFS中hdfs://mycluster中的mycluster地址 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- mycluster下面由两个namenode服务支撑 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--指定nn1的地址和端口号,发布的是一个hdfs://的服务--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node2:8020</value> </property> <!--指定三台journal服务器的地址--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value> </property> <!-- 指定客户端查找active的namenode的策略: 会给所有namenode发请求,以决定哪个是active的 --> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--在发生故障切换的时候,ssh到对方服务器,将namenode进程kill掉 kill -9 55767--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property> <!-- 指定journalnode在哪个目录存放edits log文件 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/var/bjsxt/hadoop/ha/jnn</value> </property> <!--启用自动故障切换--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
启动ha的hadoop先同步配置文件到node2、node3、node4
scp -r $HADOOP_HOME/etc/hadoop/* node[234]:/opt/hadoop-2.6.5/etc/hadoop/
0)启动zookeeper集群
a) 在node1
ode2
ode3上启动三台journalnode
hadoop-daemon.sh start journalnode
b) 任意选择node1,格式化HDFS
hdfs namenode -format
格式化后,启动namenode进程
hadoop-daemon.sh start namenode
c) 在另一台node2上同步元数据
hdfs namenode -bootstrapStandby
d) 初始化zookeeper上的内容 一定是在namenode节点上。
hdfs zkfc -formatZK
e) 启动hadoop集群,可在node1到node4这四台服务器上任意位置执行
start-dfs.sh
stop-dfs.sh停止hadoop服务。
zookeeper操作
在node2或者node3或者node4上运行
zkCli.sh
ls /hadoop-ha/mycluster 查看临时文件
get /hadoop-ha/mycluster/ActiveStandbyElectorLock 查看临时文件的内容
退出zkCli.sh
quit
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/root
/user/root是用户root家目录
停止集群:
首先
stop-dfs.sh
其次,停止zookeeper集群
node2、node3、node4上执行:
zkServer.sh stop
